Clear Sky Science · ru
Построение и применение графа знаний для документов стандартов качества семян
Почему правила для семян важны для продовольствия всех
За каждой пачкой риса или пакетом семян овощей стоит сеть технических стандартов, которые незаметно защищают урожайность и продовольственную безопасность. Тем не менее эти правила качества семян обычно скрыты в плотных PDF‑документах, которые трудно просматривать и интерпретировать фермерам, регуляторам и компаниям. В этом исследовании показано, как превращение таких статичных документов в «живую» карту связанных фактов — граф знаний — может сделать сельскохозяйственные стандарты более прозрачными, поисковыми и пригодными для эры цифрового земледелия. 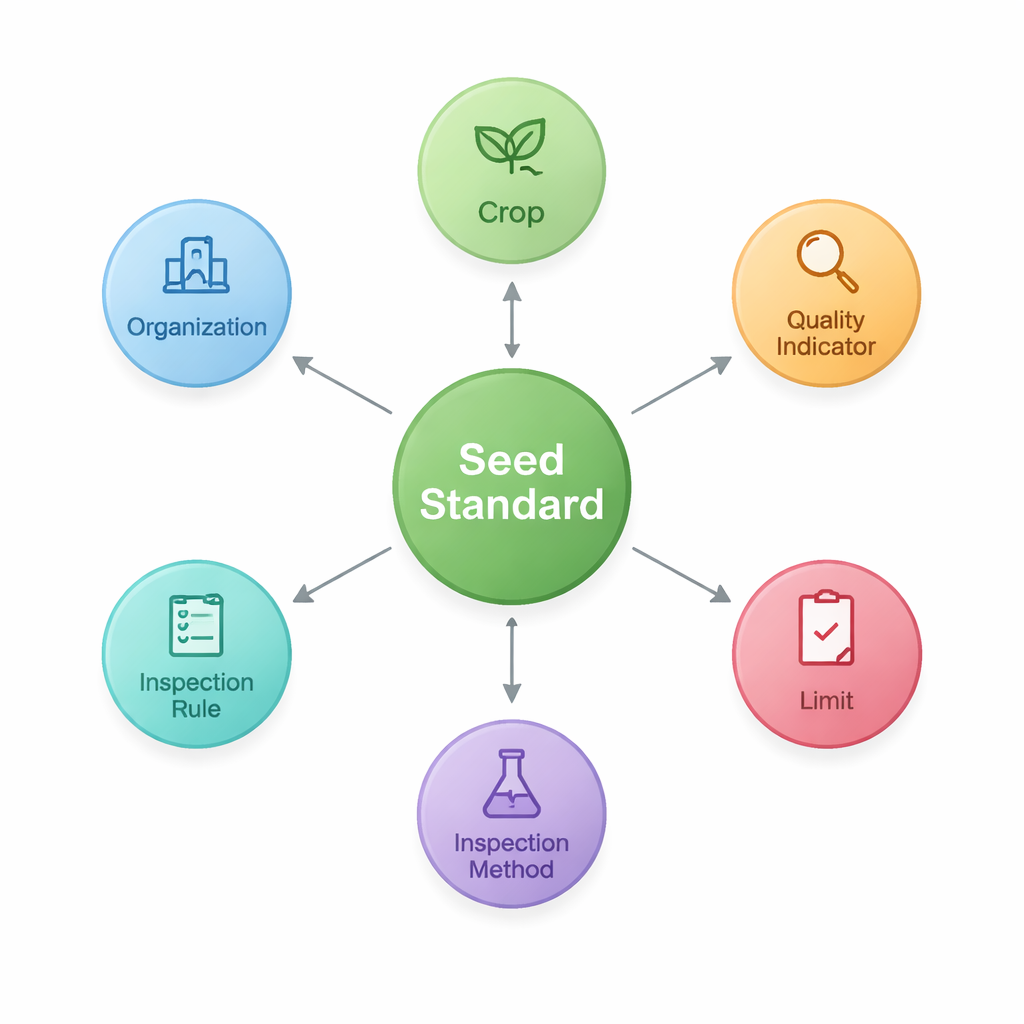
От бумажных стандартов к умной информации
Стандарты качества семян определяют, что считается приемлемым: насколько чистой должна быть партия, сколько семян должно всходить, какое допускается содержание влаги и какие методы используются для проверки этих показателей. В Китае число таких документов резко выросло, и многие по‑прежнему существуют лишь в виде отсканированных страниц или неструктурированного текста. Простой поиск по ключевым словам с трудом отвечает на практические вопросы вроде «Какие пределы чистоты для этой культуры?» или «Какое правило заменило прежнее?». Авторы утверждают, что чтобы не отставать от быстрых изменений в сельском хозяйстве, эти стандарты должны перейти от страниц, понятных людям, к представлениям, понятным машинам, которые поддерживают быстрые запросы, сравнения и автоматические проверки.
Построение карты знаний о семенах
Для этого исследователи сначала разрабатывают «онтологию» — общую схему, задающую основные строительные блоки стандартов семян и их связи. Они выделяют семь основных типов сущностей, включая сам стандарт, покрываемую культуру, показатели качества (такие как чистота или скорость прорастания), числовые пределы для этих показателей, методы и правила инспекции, а также организации, разрабатывающие или публикующие документы. Эта структура фиксирует такие шаблоны, как «Культура–Показатель качества–Предел», которые особенно важны в сельском хозяйстве. Используя эту схему, они затем сохраняют извлечённые факты в виде узлов и связей в графовой базе данных (Neo4j), создав сеть из 2436 сущностей, связанных 3011 отношениями.
Сочетание правил и машинного обучения
Главная сложность состоит в том, чтобы извлечь чистые и надёжные факты из «грязных» исходных документов. Стандарты семян содержат аккуратно оформленные таблицы, строгие метаданные на титульных страницах и длинные свободно сформулированные пункты. Ни одна техника не решает все задачи одновременно. Поэтому команда создаёт гибридную систему извлечения. Для чтения структурированных таблиц и базовой информации документа они используют точные шаблоны правил (регулярные выражения), которые хорошо работают для строго формализованных частей. Для более сложного повествовательного текста — например, подробных правил инспекции — они обучают современную конвейерную модель BERT–BiLSTM–CRF для распознавания ключевых названий, кодов и технических терминов. Эта модель учится на тщательно размеченных примерах и способна находить сущности даже при вариативной формулировке и в длинных предложениях. 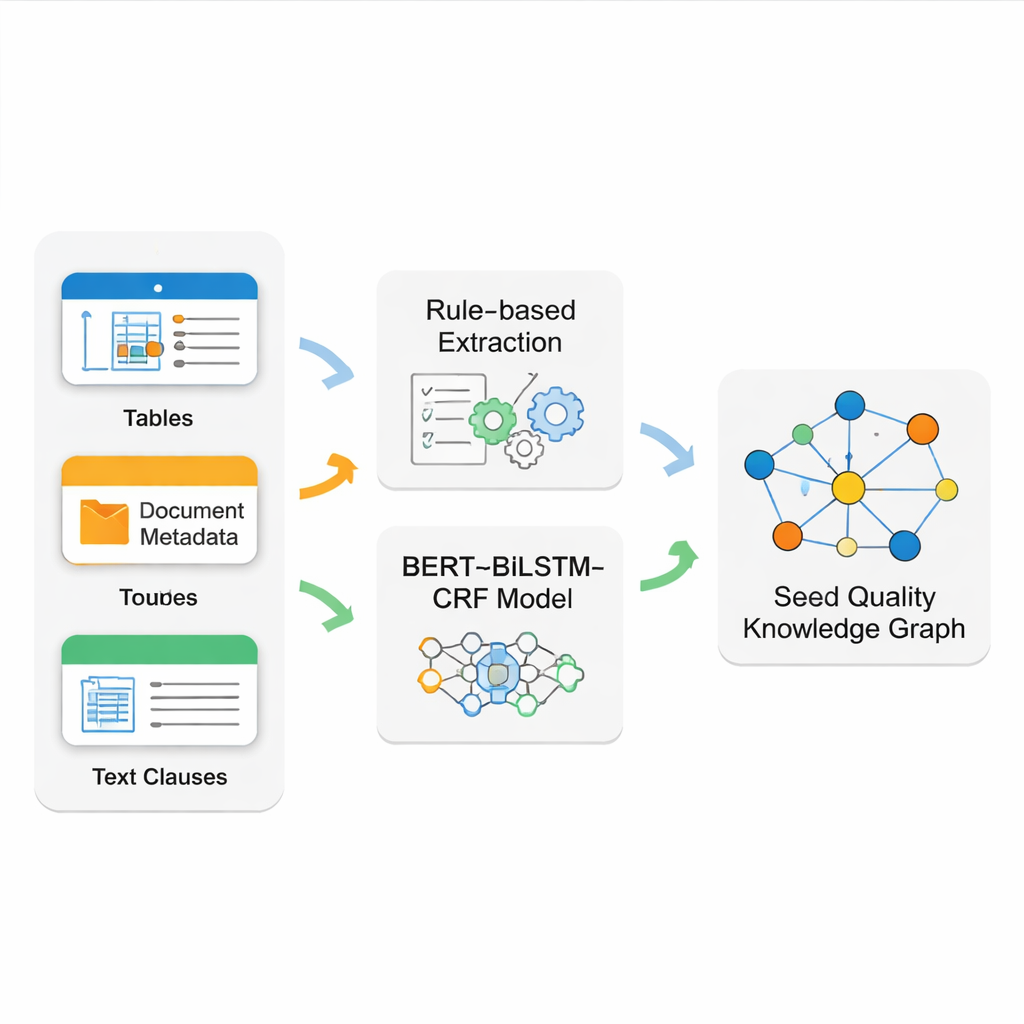
Насколько хорошо система работает на практике
При тестировании гибридный подход показывает высокую эффективность. Языковая модель достигает суммарного F1‑скорa (баланс точности и полноты) примерно 91,6%, обгоняя два широко используемых базовых метода. Она особенно хорошо выявляет структурированные элементы, такие как коды стандартов, и сохраняет устойчивость даже в сложных задачах, например при обработке длинных правил инспекции. После загрузки всей этой информации в граф знаний пользователи могут визуально изучать, как данный стандарт связан с предыдущими версиями, какие организации его разрабатывали, какие культуры и показатели он охватывает и какие методы испытаний он предписывает. Вместо перелистывания длинных PDF‑файлов регуляторы и семенные компании могут выполнять целевые поиски и получать связанные результаты за секунды.
Что это значит для фермеров и продовольственных систем
Для неспециалистов результат — более умный способ управлять правилами, которые обеспечивают надёжность семян и продуктивность посевов. Исследование показывает, что сочетание чёткой концептуальной схемы с методами извлечения, основанными как на правилах, так и на обучении, позволяет превратить разрозненные стандарты качества семян в связную, доступную для поиска базу знаний. Это создаёт техническую основу для «SMART» стандартов, которые компьютеры смогут читать, проверять и обновлять по мере изменения регуляций. В долгосрочной перспективе такие инструменты помогут фермерам и агробизнесу быстро подтверждать соответствие семян текущим требованиям качества, поддерживать регуляторов в отслеживании правок и пробелов и способствовать более стабильным урожаям и продовольственной безопасности.
Цитирование: Yang, Z., He, Q. & Zhang, J. Construction and application of knowledge graph for seed quality standard documents. Sci Rep 16, 5997 (2026). https://doi.org/10.1038/s41598-026-37084-y
Ключевые слова: стандарты качества семян, граф знаний, оцифровка сельского хозяйства, распознавание именованных сущностей, умные стандарты