Clear Sky Science · ru
Большая модель языка, основанная на знаниях, для генерации персонализированных планов спортивных тренировок
Умнее планы тренировок для обычных людей
Большинство фитнес-приложений обещают персонализацию, но многие по-прежнему опираются на общие шаблоны, которые игнорируют реальное состояние вашего тела. В этой статье представлен LLM-SPTRec — новая система, использующая тот же тип больших языковых моделей, что и современные чатботы, в сочетании с проверенными знаниями спортивной науки и данными носимых устройств, для создания более безопасных и эффективных планов тренировок. Для тех, кто задавался вопросом, почему приложение постоянно предлагает неподходящие упражнения, или беспокоился, безопасны ли советы по здоровью, сгенерированные ИИ, эта работа показывает, как сделать цифровой коучинг одновременно более персональным и более научно обоснованным.
Почему традиционные фитнес-приложения оказываются недостаточными
Обычные рекомендательные системы, похожие на те, что предлагают фильмы или товары, испытывают трудности при применении к физическим упражнениям. Они часто копируют и повторно используют стандартные шаблоны, плохо справляются с ограниченными данными для новых пользователей и редко учитывают, как ваше тело меняется день ото дня. Хуже того, они не рассчитаны на принятие решений, где важна безопасность. Универсальные языковые модели хорошо умеют рассуждать о тренировках, но поскольку они обучены на разнородных текстах из интернета, они могут «галлюцинировать» рискованные советы или пренебрегать необходимыми днями отдыха. Авторы утверждают, что для планирования тренировок — где плохие рекомендации могут привести к травмам или перетренированности — ИИ должен быть привязан к проверенной спортивной науке и отслеживать изменение состояния человека во времени.
Создание детальной картины человека
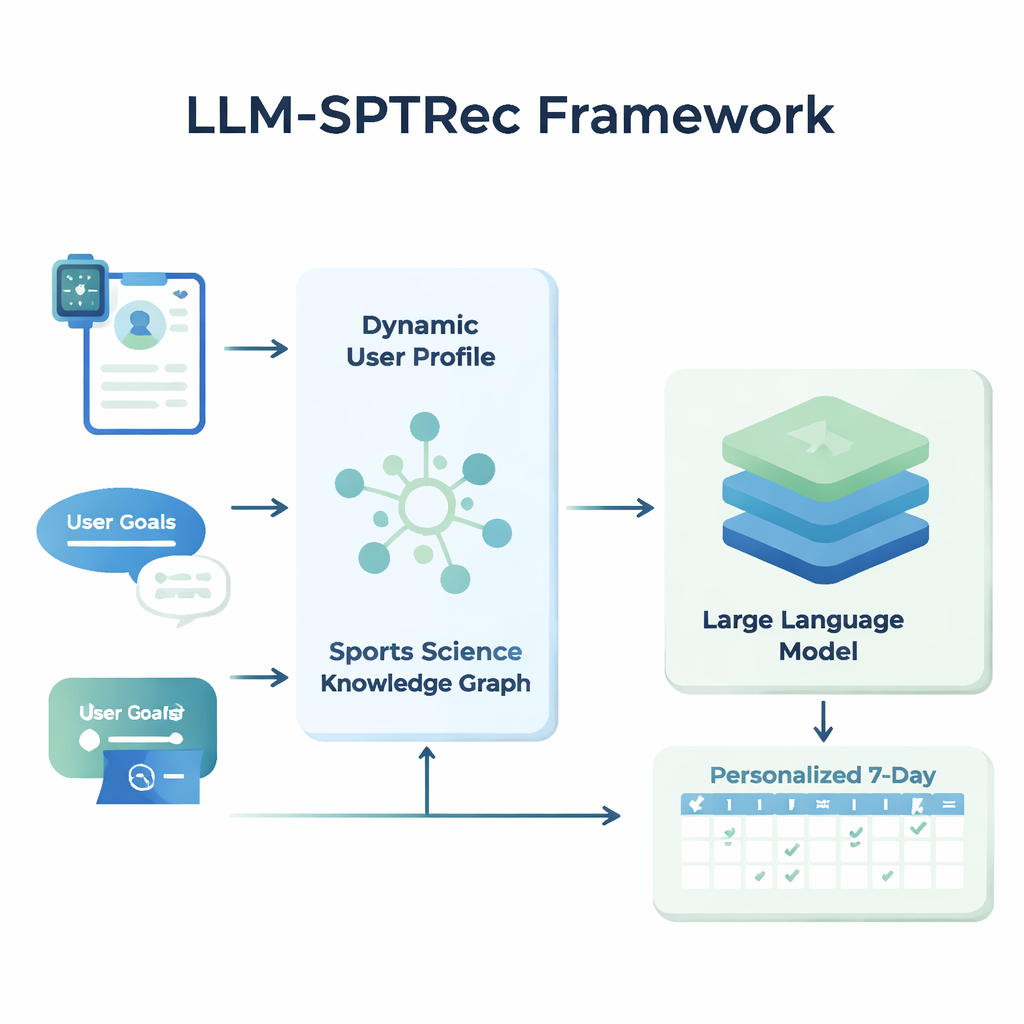
В основе LLM-SPTRec лежит модуль, который создает подробный снимок каждого пользователя. Вместо того чтобы хранить только возраст, пол или уровень опыта, система объединяет три типа информации: статические характеристики (например, история тренировок), динамические сигналы (такие как частота сердечных сокращений, вариабельность сердечного ритма, оценка сна и предыдущие тренировки из носимых устройств и журналов) и текстовые цели, написанные пользователем. Модель на основе трансформера — родственник технологии современных языковых моделей — изучает закономерности во временных рядах, например, как интенсивная тренировка вчера может повлиять на готовность сегодня. Механизм внимания затем определяет, какие сигналы наиболее важны в данный момент, объединяя их в единое числовое представление текущего состояния пользователя.
Обучение ИИ реальной спортивной науке
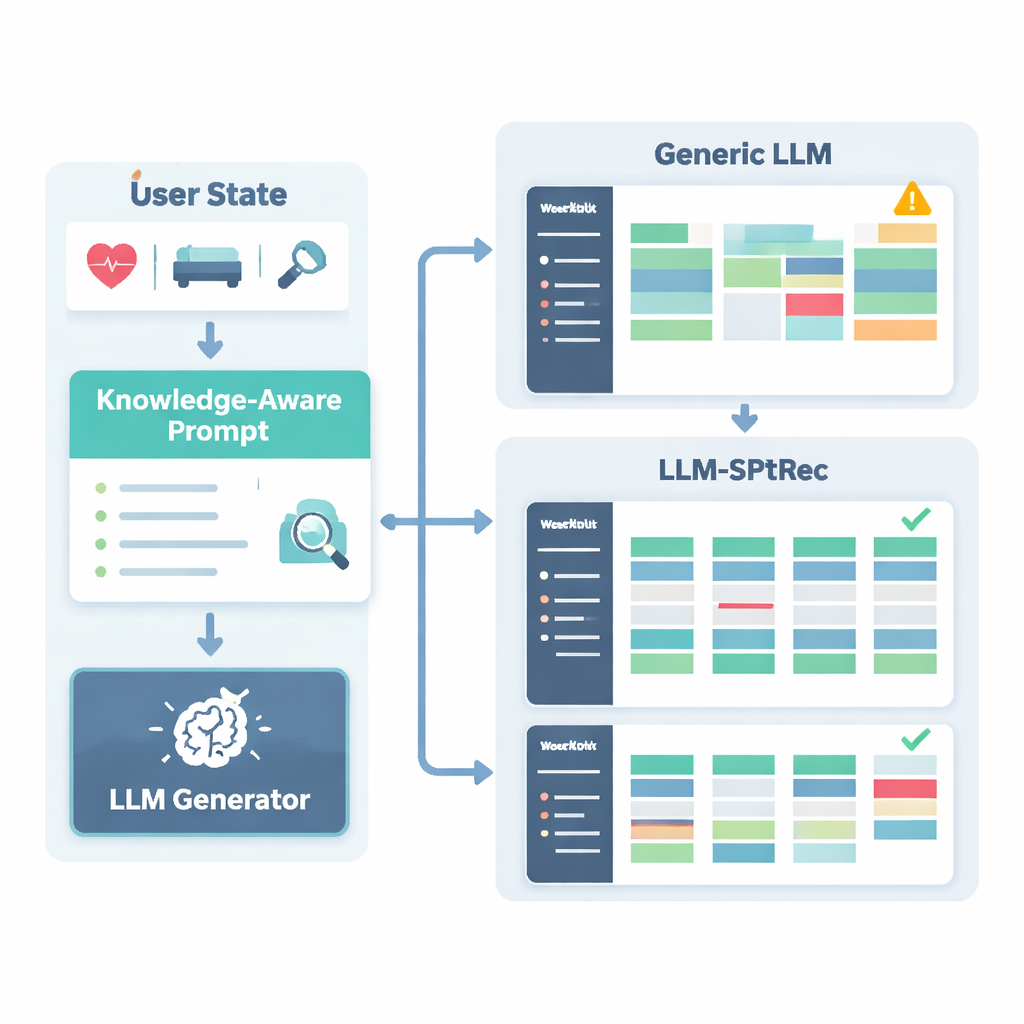
Чтобы предотвратить небезопасные или ненаучные рекомендации, исследователи создали Граф знаний спортивной науки — по сути структурированную карту одобренных экспертами фактов. Он включает тысячи записей, связывающих упражнения с мышцами, типами движений, оборудованием, распространенными травмами и принципами тренировки, такими как прогрессивная нагрузка и специфичность. Для каждого пользователя система извлекает наиболее релевантные части этого графа — например, какие мышцы задействует жим лежа и какие движения вредны при проблемах с плечом — и преобразует их в читаемый текст, который подается в языковую модель вместе с профилем пользователя. Языковая модель затем по заранее продуманному запросу генерирует многодневный план тренировок в структурированном формате, соблюдая правила, такие как чередование групп мышц между днями и избегание известных противопоказаний.
Поддержание структуры планов, безопасность и их улучшение со временем
LLM-SPTRec делает больше, чем просто генерирует текст. Модуль валидации проверяет каждый план по жестким правилам, например, чтобы не перегружать одни и те же основные группы мышц в подряд идущие дни, и отмечает конфликты с рисками травм, сохраненными в графе знаний. Если план не проходит проверки, система снова направляет запрос модели, явно указывая на ошибки, пока не будет получен безопасный план. Обучение системы также происходит в два этапа. Сначала она учится на большой коллекции планов, созданных экспертами. Затем ее дорабатывают с помощью обратной связи, где симулированные или реальные оценки пользователей вознаграждают планы, которые последовательны, соответствуют целям и приятны в выполнении, и строго наказывают за небезопасные предложения. Этот цикл обратной связи направляет модель к рекомендациям, которые лучше работают на практике.
Насколько хорошо система работает на практике
Авторы протестировали LLM-SPTRec на большой реальной базе данных SportFit-1M, которая объединяет анонимизированные данные из фитнес-приложений и носимых устройств, охватывая десятки тысяч пользователей и миллионы записей о тренировках и физиологических показателях. Они сравнили свою систему с сильными базовыми методами: классической коллаборативной фильтрацией, последовательной моделью, которая учитывает только прошлые выборы, передовым рекомендателем на основе графа знаний и универсальной системой на базе языковой модели. LLM-SPTRec превзошел их всех не только в выборе подходящих упражнений, но, что важнее, в создании полных планов, которые эксперты оценили как более согласованные и лучше соответствующие целям пользователей. Прогнозируемые оценки удовлетворенности пользователей также были выше, а небольшое исследование с участием сертифицированных тренеров поставило его безопасность значительно выше по сравнению с общей языковой моделью без привязки к спортивной науке.
Что это значит для будущего цифрового коучинга
Для неспециалиста главный вывод таков: более умный и безопасный ИИ-коучинг возможен, когда сходятся три компонента — богатые данные с ваших устройств, экспертная спортивная наука, закодированная в виде структурированных знаний, и мощные языковые модели, чья креативность тщательно направляется и проверяется. LLM-SPTRec показывает, что такое сочетание может генерировать адаптивные планы на каждый день, которые учитывают меняющееся состояние вашего тела и ваши личные цели, снижая риск вредных или бессмысленных советов. В перспективе тот же подход можно расширить за рамки тренировок на питание, восстановление после травм или даже психическое благополучие, что указывает на будущее, в котором ИИ-помощники будут действовать не как общие чатботы, а как знающие и ориентированные на безопасность цифровые тренеры.
Цитирование: He, Z., Wang, J., Zhang, B. et al. Knowledge-grounded large language model for personalized sports training plan generation. Sci Rep 16, 6793 (2026). https://doi.org/10.1038/s41598-026-37075-z
Ключевые слова: персонализированные тренировки, ИИ в спортивной науке, рекомендации по фитнесу, данные носимых устройств, граф знаний