Clear Sky Science · ru
Смещение интерпретации в объяснимом ИИ при шуме меток
Почему объяснения ИИ могут тихо давать сбой
Сегодня многие люди полагаются на искусственный интеллект не только ради ответов, но и ради объяснений: почему отказали в кредите? почему систему признали пациента высокорисковым? В этом исследовании показано, что даже когда точность модели ИИ кажется стабильно хорошей, рассказ о том, почему она приняла решение, может резко измениться, если в обучающих данных есть ошибки. Это скрытое смещение в объяснениях — которое авторы называют «смещением интерпретации» — может ввести в заблуждение специалистов, которые полагаются на ИИ при обосновании важных решений.
Когда чистые данные встречают грязные метки
Большинство современных систем ИИ — «черные ящики», выдающие предсказания без ясных причин. Чтобы сделать ИИ более прозрачным, во многих приложениях используют модели на правилах, напоминающие человеческое рассуждение в формате если–то: например, «если кровяное давление высокое и возраст старше 60, то риск высокий». Такие наборы правил особенно привлекательны в чувствительных областях — здравоохранении, юриспруденции и финансах — где пользователям важно проверять и доверять логике. Но в реальности данные редко бывают идеальными. Одна из распространенных проблем — шум меток: случаи, когда предполагаемый «правильный ответ» в обучающем наборе неверен, например из‑за ошибочно записанного диагноза или неправильно помеченного исхода клиента. Хотя известно, что шум меток портит качество предсказаний, его влияние на стабильность объяснений ИИ систематически не изучалось.
Проверка устойчивости объяснений при шуме
Авторы оценили, насколько устойчивыми остаются объяснения в виде правил, когда метки постепенно искажаются. Они использовали четыре набора данных из медицины, банковского дела, исследований печени и даже теории чисел — все как задачи предсказания «да/нет». Сравнивались три метода обучения правил: два популярных быстрых алгоритма (IREP и RIPPER) и более ресурсоёмкий подход, называемый Human Knowledge Models (HKM), который явно нацелен на получение очень простых, похожих на человеческие, наборов правил. Для каждого метода исследователи многократно обучали модели, случайным образом переворачивая возрастающую долю меток в обучающем наборе — от почти чистых данных до почти полного бессмысленного шума. Они отслеживали две вещи параллельно: насколько хорошо модели предсказывают на чистом тестовом наборе и насколько изменились выученные правила по сравнению с объяснениями на данных без шума.
Точность устойчива, логика меняется
На первый взгляд результаты могли успокоить пользователей ложным чувством безопасности. При умеренных уровнях шума, особенно для метода HKM, предсказательная производительность выглядела относительно стабильной по общепринятому F1‑метрике. Но при более внимательном рассмотрении наборы правил рассказали иную историю. С помощью меры сходства, сравнивающей коллекции правил, авторы обнаружили, что даже небольшие количества шума меток быстро разрушают перекрытие между исходными и искаженными объяснениями. Иными словами, модель всё ещё может правильно решать многие случаи, но по всё более разным причинам. Более сложные наборы правил были особенно хрупки: по мере роста числа условий в правиле небольшие изменения в данных легче ломали или заменяли эти правила, ускоряя потерю стабильности интерпретируемости.
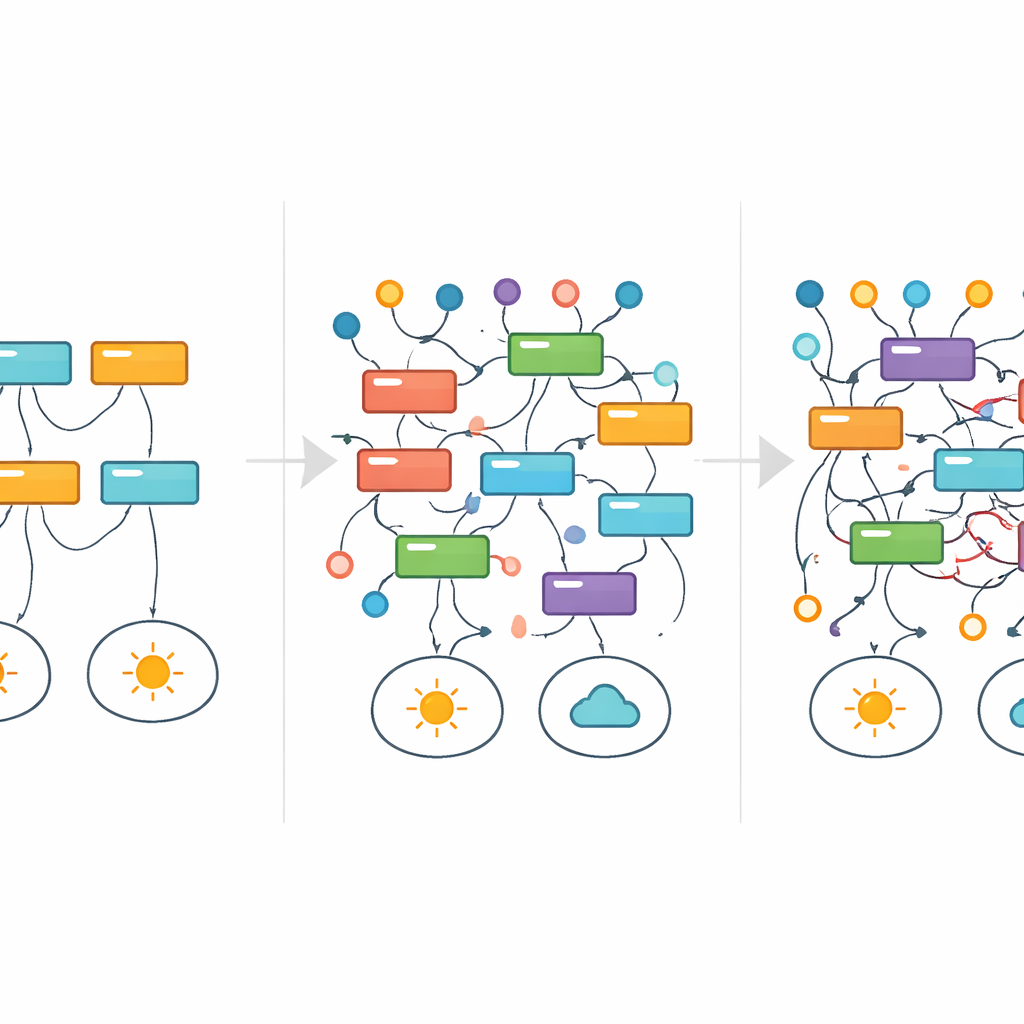
Отслеживание правил, которые появляются и исчезают
Чтобы визуализировать, как отдельные объяснения выживают или исчезают по мере увеличения шума, исследователи позаимствовали инструмент из медицины: анализ выживаемости. Вместо того чтобы отслеживать выживание пациентов во времени, они отслеживали, как долго конкретное правило продолжало появляться среди лучших моделей по мере возрастания шума меток. Вместо постепенного угасания многие правила мигали — появлялись и исчезали — что указывало на то, что совершенно разные объяснения могли доминировать на разных уровнях шума, даже для одной и той же задачи. В простом наборе данных о делимости чисел, например, чистые и математически верные правила постепенно заменялись более общими приближениями и в конце концов запутанными, на вид произвольными шаблонами, которые всё ещё соответствовали искаженными меткам. На протяжении большей части этого процесса сводные метрики производительности явно ничего не сигнализировали о проблеме.
Что это значит для людей, которые полагаются на ИИ
Главный вывод заключается в том, что «доверенный» ИИ нельзя оценивать только по точности. Даже модели, которые представляют свою логику в человекочитаемых правилах, могут тайно менять свои рассуждения, когда метки, на которых они обучаются, неточны — а именно такая ситуация характерна для большинства реальных баз данных. Авторы утверждают, что разработчики и регуляторы должны рассматривать стабильность объяснений как важное требование наравне с точностью и справедливостью. Необходимы новые метрики, которые напрямую измеряют, насколько консистентны объяснения модели при наличии шума, и инструменты, которые будут предупреждать пользователей о смещении интерпретации, если мы хотим, чтобы истории, которые ИИ рассказывает о мире, были столь же надежны, как и его предсказания.
Цитирование: Raikovskaia, A., Rakhimzhanov, N. & Pianykh, O.S. Interpretation drift in explainable AI under label noise. Sci Rep 16, 8528 (2026). https://doi.org/10.1038/s41598-026-37070-4
Ключевые слова: объяснимый ИИ, шум меток, интерпретируемость модели, модели на правилах, смещение интерпретации