Clear Sky Science · ru
Эволюция обнаружения объектов: от CNN к трансформерам и мультимодальному слиянию
Обучая компьютеры видеть повседневные объекты
Каждый раз, когда ваш телефон отмечает друзей на фото, автомобиль замечает пешехода или медицинский инструмент выделяет опухоль на снимке, за этим работает тихо мощная технология: обнаружение объектов. В этом обзорном материале объясняется, как обнаружение объектов быстро развивалось за последнее десятилетие — от ранних приёмов обработки изображений до современных систем на основе трансформеров и мультисенсорного слияния — и почему эти достижения важны для более безопасных улиц, умных роботов и более точных медицинских диагнозов.
От пикселей к узнаваемым вещам
Обнаружение объектов — это задача поиска и маркировки конкретных предметов на изображениях или в видео: автомобилей, велосипедистов, животных, анатомических структур и других. Статья начинается с описания областей применения: автономное вождение, наблюдение, медицинская визуализация и робототехника. Ранние системы опирались на вручную разработанные правила для выделения форм и текстур, тогда как современные подходы учатся прямо на данных с помощью глубокого обучения. Сегодня доминируют две большие семьи методов: сверточные нейронные сети (CNN), которые отлично выявляют локальные паттерны — края и углы, — и трансформеры, которые превосходят в понимании общей сцены и отношений между удалёнными объектами. Вкупе они определяют, как современные машины «видят» мир.
Как работают классические движки зрения
Методы на базе CNN по-прежнему обеспечивают работу многих приложений в реальном времени. Они сканируют изображение малыми фильтрами, накапливая всё более богатые карты признаков, а затем передают их в блоки детектирования, которые рисуют ограничивающие рамки и присваивают метки. Обзор объясняет две основные стратегии. Двухэтапные системы, например Faster R-CNN, сначала предлагают вероятные регионы объектов, а затем уточняют их, обычно достигая высокой точности ценой больших вычислений. Одноэтапные системы, такие как семейство YOLO, пропускают этап предложений и предсказывают рамки и метки за один проход, жертвуя частью точности ради скорости. Современные версии YOLOv5 и YOLOv8 были значительно оптимизированы — добавлены более умные пирамиды признаков для мелких объектов, лёгкие блоки для устройств на краю сети и улучшенные функции потерь — чтобы достигать сотен кадров в секунду и оставаться конкурентоспособными в жёстких бенчмарках.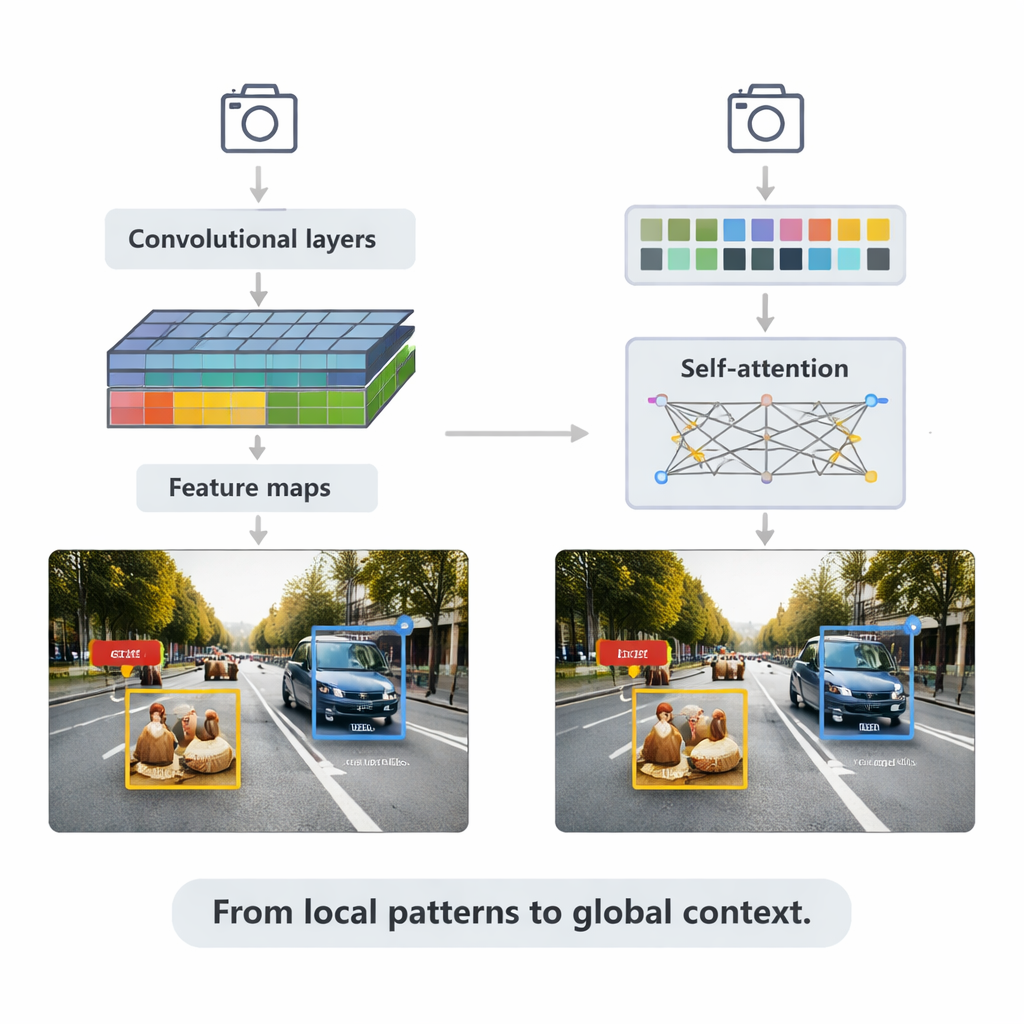
Трансформеры и сила контекста
Далее статья обращается к трансформерам — новой архитектуре, заимствованной у языковых моделей. Вместо того чтобы фокусироваться лишь на локальных окрестностях, трансформеры используют «самовнимание», сравнивая каждый фрагмент изображения со всеми остальными и узнавая, какие регионы наиболее важны для конкретного решения. Detection Transformer (DETR) и его преемники избавляются от многих вручную придуманых приёмов, стремясь к более чистым конвейерам «от конца до конца». Варианты, такие как Deformable DETR и RT-DETR, сокращают вычисления и ускоряют обучение, позволяя трансформерам работать в реальном времени и при этом достигать одних из лучших результатов на широко используемом бенчмарке COCO. Эти модели особенно эффективны в сложных сценах с перекрывающимися объектами и запутанными фонами, где глобальный контекст помогает, например, различить пешехода, частично скрытого за автомобилем.
Смешение камер, лазеров и языка
Условия реального мира — туман, темнота, блики, загромождённость — часто ставят в тупик системы с одним сенсором. В обзоре особое внимание уделено мультимодальному слиянию: объединению данных с обычных камер (RGB), датчиков глубины вроде LiDAR, тепловизоров и даже текстовых описаний. Авторы предлагают понятную таксономию способов такого объединения: раннее слияние смешивает сырые данные в начале, среднее слияние объединяет выученные признаки внутри сети, а позднее слияние комбинирует выходы отдельных детекторов в конце. Современные «fusion-трансформеры» используют механизмы внимания для выравнивания этих потоков, так что точные измерения расстояния от LiDAR, богатая информация об внешнем виде из RGB-изображений и семантические подсказки из языка усиливают друг друга. Такой подход улучшает обнаружение в автономном вождении, медицинской визуализации, понимании видео и сценах с большим количеством текста.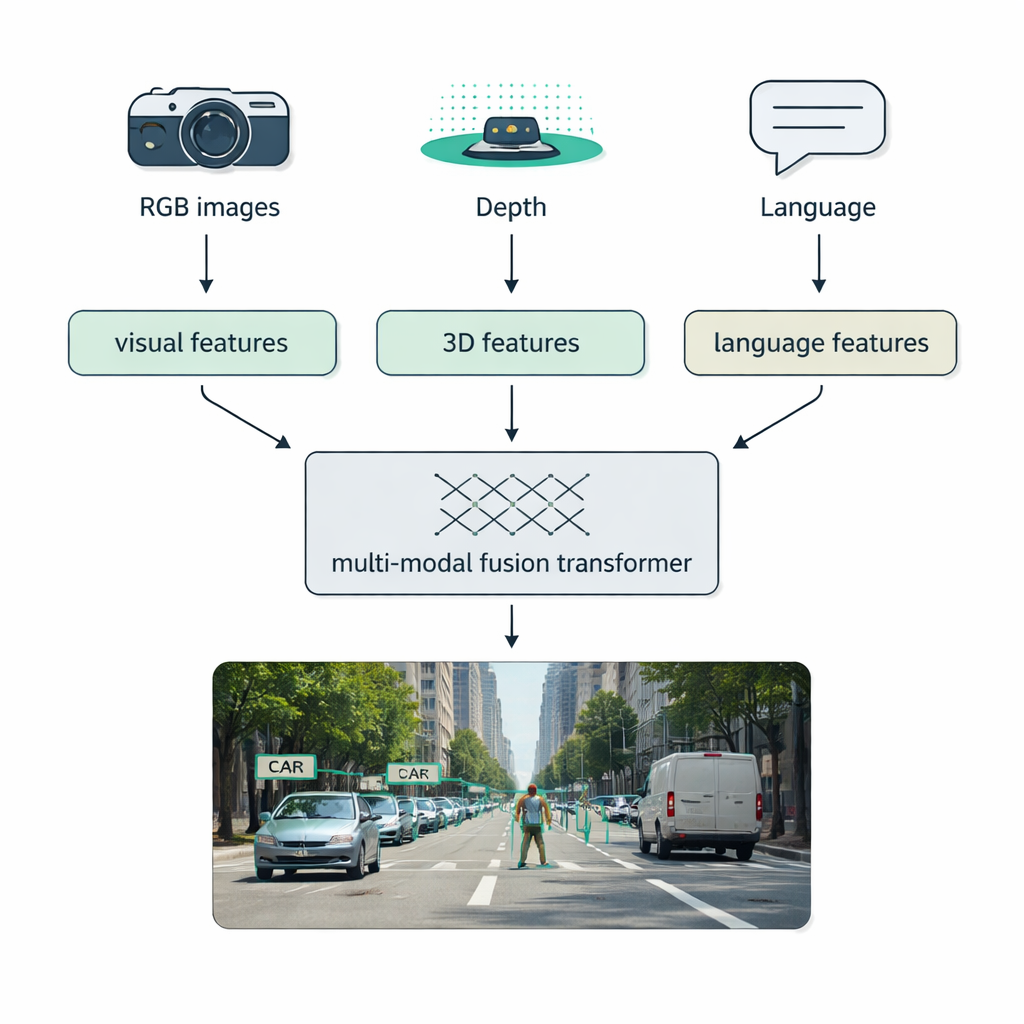
Бенчмарки, ограничения и что будет дальше
На стандартных тестах, таких как MS COCO, обзор сравнивает детекторы на базе CNN и трансформеров по точности и скорости. Классические двухэтапные CNN остаются сильными, но медленнее; модели в стиле YOLO доминируют на лёгком аппаратном обеспечении; а системы на основе трансформеров сейчас лидируют по точности, сокращая разрыв по скорости. Специализированные инфракрасные методы достигают очень высоких результатов в условиях плохой видимости. Тем не менее остаются сложные задачи: очень маленькие или экстремально крупные объекты, сильная окклюзия, изменяющаяся погода и освещение, а также необходимость надёжной работы на крошечных устройствах. Взгляд в будущее показывает тенденции к объединённым моделям восприятия, которые одновременно решают задачи детекции, сегментации и подписи, а также к «фундаментальным моделям», которые объединяют зрение и язык, чтобы распознавать объекты, описанные простым текстом, даже если они не были помечены в обучающей выборке.
Почему это важно в повседневной жизни
Для неспециалистов главный вывод таков: обнаружение объектов движется от узких, вручную настроенных систем к гибким универсальным механизмам зрения, способным адаптироваться к новым задачам, средам и сенсорам. CNN обеспечивают быстрое и эффективное распознавание шаблонов; трансформеры добавляют более глобальное, контекстуально осознанное понимание; а мультимодальное слияние привносит дополнительные подсказки о глубине, температуре и языке. В совокупности эти достижения обещают автомобили, которые лучше предугадывают опасности, инструменты, которые с большей уверенностью помогают врачам, и домашние устройства, которые взаимодействуют с окружением безопаснее и умнее — приближая машинное восприятие к богатству человеческого зрения.
Цитирование: Wang, Z., Chen, Y., Gu, Y. et al. The evolution of object detection from CNNs to transformers and multi-modal fusion. Sci Rep 16, 7517 (2026). https://doi.org/10.1038/s41598-026-37052-6
Ключевые слова: обнаружение объектов, компьютерное зрение, глубокое обучение, модели трансформеров, мультимодальное слияние