Clear Sky Science · ru
Определение функционального статуса подвижности в электронных медицинских записях с использованием больших языковых моделей
Почему способность к ходьбе — важный показатель здоровья
Поскольку люди живут дольше, врачи обращают внимание не только на продолжительность жизни, но и на то, насколько хорошо мы можем двигаться, ходить и заботиться о себе. Трудности с подъёмом со стула, подъемом по лестнице или передвижением по городу часто проявляются задолго до медицинского кризиса. Тем не менее наиболее подробные описания повседневных способностей человека обычно скрыты в свободном тексте заметок врачей и терапевтов в электронных медицинских записях, где их трудно найти с помощью компьютера. В этом исследовании изучают, могут ли современные большие языковые модели — тот же тип ИИ, что стоит за многими чат‑ботами — надежно читать эти заметки и превращать описания движений в структурированную, удобную для поиска информацию.
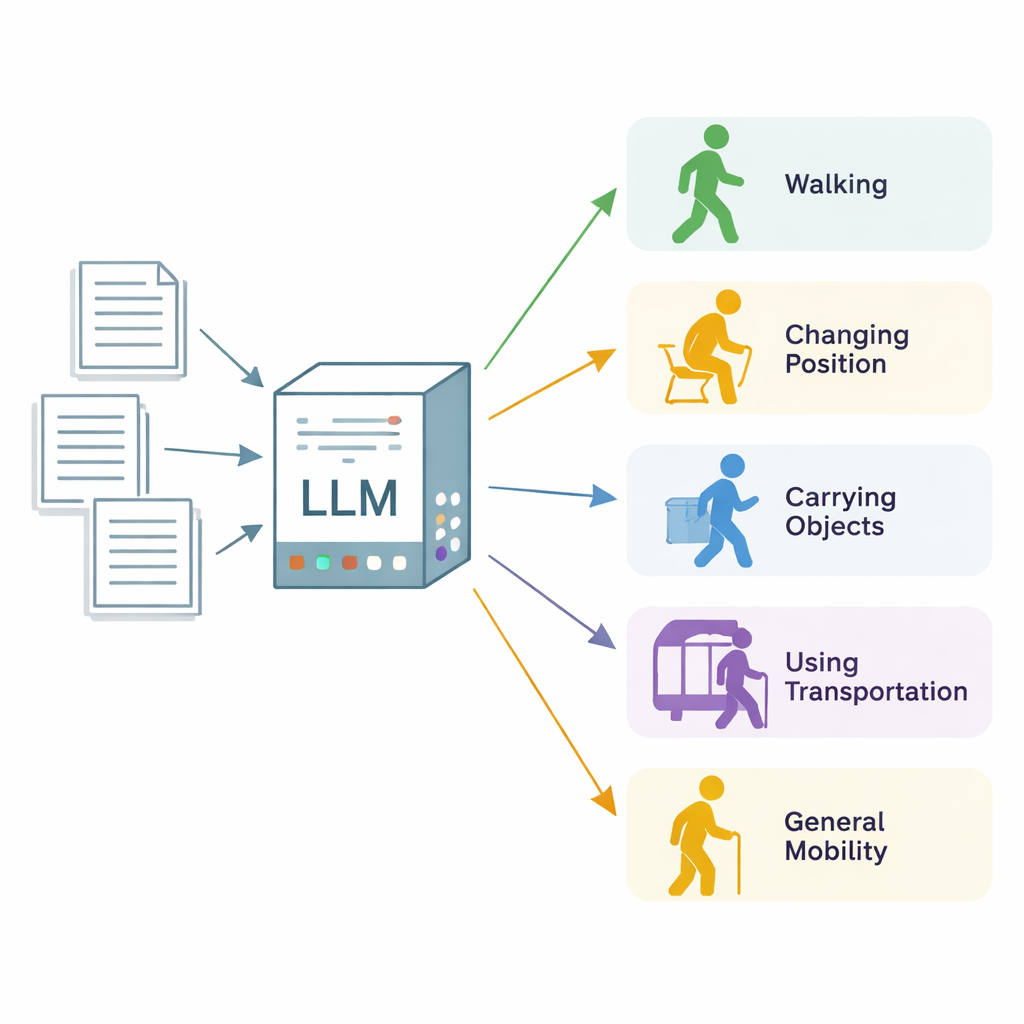
Преобразование неструктурированных заметок в пригодные данные о подвижности
Исследователи сосредоточились на «функциональном статусе подвижности» — широком понятии, описывающем, насколько хорошо человек меняет положение тела, ходит, переносит и управляет предметами, пользуется транспортом и передвигается в повседневной жизни. Они использовали 600 реальных клинических заметок из трёх медицинских учреждений Миннесоты и Висконсина, большинство из которых были из визитов к физиотерапевтам и практическим терапевтам, а также набор более общих клинических заметок. Экспертные аннотаторы просматривали каждую заметку по секциям и помечали все отрывки, описывающие одну из пяти категорий подвижности, отмечая, был ли пациент явно ограничен («нарушено») или функционировал нормально («не нарушено»). Эти экспертные метки служили золотым стандартом для оценки работы ИИ‑системы.
Как модель ИИ обучили читать как клиницист
Команда использовала Llama 3, открытую большую языковую модель, и запускала её на защищённых локальных серверах, чтобы данные пациентов не покидали систему здравоохранения. Вместо обучения модели с нуля они тщательно разработали подсказки — наборы письменных инструкций и определений — чтобы научить модель тому, что искать. Пробовали «zero‑shot» подсказки, которые содержат только инструкции, и «few‑shot» подсказки, которые также включают несколько примеров заметок. Затем они проанализировали ошибки модели и создали «информированную об ошибках» подсказку, в которой было явно указано, что включать, что игнорировать (например, планы на будущие процедуры) и как поступать с трудными случаями, такими как падения, головокружение или использование инвалидной коляски. Модель просили для каждой секции заметки и для каждой категории подвижности ответить, упоминается ли подвижность вообще и, если да, ограничен ли пациент.
Хорошие результаты при объединении данных на уровне пациента
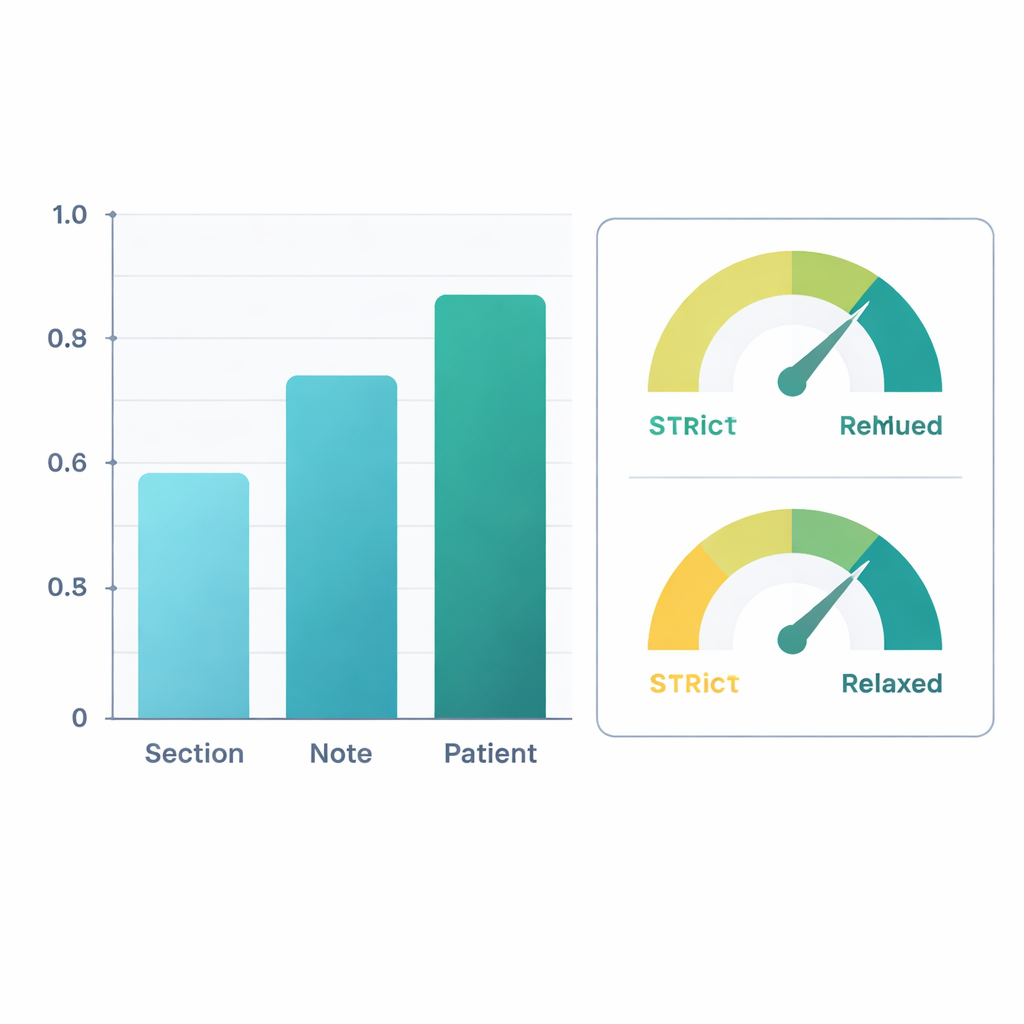
По сравнению с экспертными метками доработанная система показала хорошие результаты. На уровне целого пациента — объединяя информацию по всем его заметкам — ИИ достиг F1‑метрики (распространённой меры точности) примерно 0,88 для простого выявления информации о подвижности и 0,90 для определения, был ли человек ограничен. Это означает, что его суждения в значительной степени совпадали с оценками людей‑рецензентов. Показатели были несколько ниже при анализе отдельных секций заметок, где формулировки могут быть скупыми или неоднозначными, но точность улучшалась по мере объединения информации в пределах заметки, а затем по всем заметкам пациента. В втором анализе исследователи считали «клінічески обоснованные выводы» правильными — например, предположение, что сильная боль в колене при ходьбе вероятно ограничивает ходьбу, даже если это прямо не указано. При таком более снисходительном подходе F1‑метрики на уровне пациента выросли выше 0,96 для извлечения и 0,95 для классификации ограничений.
Что ИИ делал неправильно — и почему это всё равно важно
Большинство ошибок возникало из-за того, что модель делала выводы «между строк»: она часто интерпретировала наличие проблем с подвижностью на основании боли, головокружения или планов на будущую терапию, даже если в заметке не было прямого указания на ограничение. Другие ошибки отражали серые зоны в определениях, например, следует ли рассматривать повторяющиеся падения как проблему ходьбы или как проблему равновесия при смене положения. Класс «подвижность, неуточнённая», предназначенный для повседневной активности и упражнений, особенно трудно было однозначно определить. Несмотря на эти сложности, ошибки обычно были клинически обоснованными, а не случайными или абсурдными. Запуск модели в детерминированном режиме (без встроенной случайности) на изолированных локальных серверах также гарантировал воспроизводимость результатов и сохранность конфиденциальности пациентов.
Как это может изменить уход за пожилыми людьми
Для неспециалиста вывод таков: система ИИ теперь может достаточно хорошо прочитывать рутинные заметки врачей и терапевтов, чтобы суммировать, насколько хорошо пациенты передвигаются и с чем у них возникают трудности. Это означает, что службы здравоохранения могут отслеживать изменения в ходьбе, равновесии и повседневной активности с течением времени без введения новых опросников или тестов, выявлять людей с высоким риском падений или госпитализаций и определять, кому может понадобиться физиотерапия или оценка безопасности в доме. Преобразуя миллионы заметок в свободном тексте в структурированные данные о подвижности, этот подход помогает врачам увидеть более полную картину того, как старение и заболевания влияют на повседневную жизнь — приближая здравоохранение к по‑настоящему персонализированной медицине, ориентированной на функциональность.
Цитирование: Liu, X., Garg, M., Jia, H. et al. Mobility functional status ascertainment in electronic health records using large language models. Sci Rep 16, 6045 (2026). https://doi.org/10.1038/s41598-026-37025-9
Ключевые слова: подвижность, электронные медицинские записи, большие языковые модели, функциональный статус, клинический ИИ