Clear Sky Science · ru
Тест для оценки эффективности диагностических вопросов больших языковых моделей в беседах с пациентом
Почему важны умные медицинские вопросы
Когда вы приходите к врачу, первый услышанный диагноз редко основан на единственном упомянутом симптоме. Врачи задают серию уточняющих вопросов — о времени появления, интенсивности, сопутствующих проблемах — чтобы постепенно сузить круг возможных причин. Насколько бы мощны ни были сегодняшние системы ИИ, большинство из них всё ещё тестируют так, будто они сдают экзамены в формате множественного выбора, а не общаются с реальными людьми. В этой статье представлен Q4Dx, новый способ оценить, насколько хорошо большие языковые модели (LLM) могут играть роль «любопытного врача»: выбирать правильные вопросы в правильном порядке, чтобы эффективно прийти к верному диагнозу.
От экзаменационных задач к реальным беседам
Большинство существующих тестов медицинского ИИ предлагают моделям аккуратно оформленные, полностью описанные случаи — как в учебнике — и просят выбрать диагноз. Это показывает, что система «знает», но не демонстрирует, как она поведёт себя в беспорядочной, реальной беседе с пациентом, который забывает детали или описывает симптомы обычным языком. Авторы утверждают, что это серьёзная слепая зона. В клинике информация поступает медленно и часто неточно; навык хорошего клинициста заключается не только в том, что он уже знает, но и в том, что он умеет спросить. Q4Dx призван заполнить этот разрыв, сместив фокус с статического ответа на стратегию задавания вопросов во времени.
Создание правдоподобных историй пациентов
Для создания этой новой тестовой среды исследователи исходят из курированного медицинского ресурса, который связывает конкретные заболевания с характерными наборами симптомов. Они случайным образом выбирают 100 таких пар «заболевание–симптомы» и затем используют модель ИИ, чтобы преобразовать сухие списки симптомов в естественно звучащие описания пациентов — истории, которые человек мог бы реально рассказать в клинике. Из каждого полного случая генерируют сокращённые версии, где упомянуто лишь примерно 80 % или 50 % ключевых симптомов. Такое контролируемое «скрытие» информации позволяет изучать, насколько хорошо разные модели адаптируются, когда важные подсказки отсутствуют или только намекаются. Проверки перекрытия симптомов подтверждают, что укороченные версии действительно содержат меньше полезной информации, а не просто меньше слов.
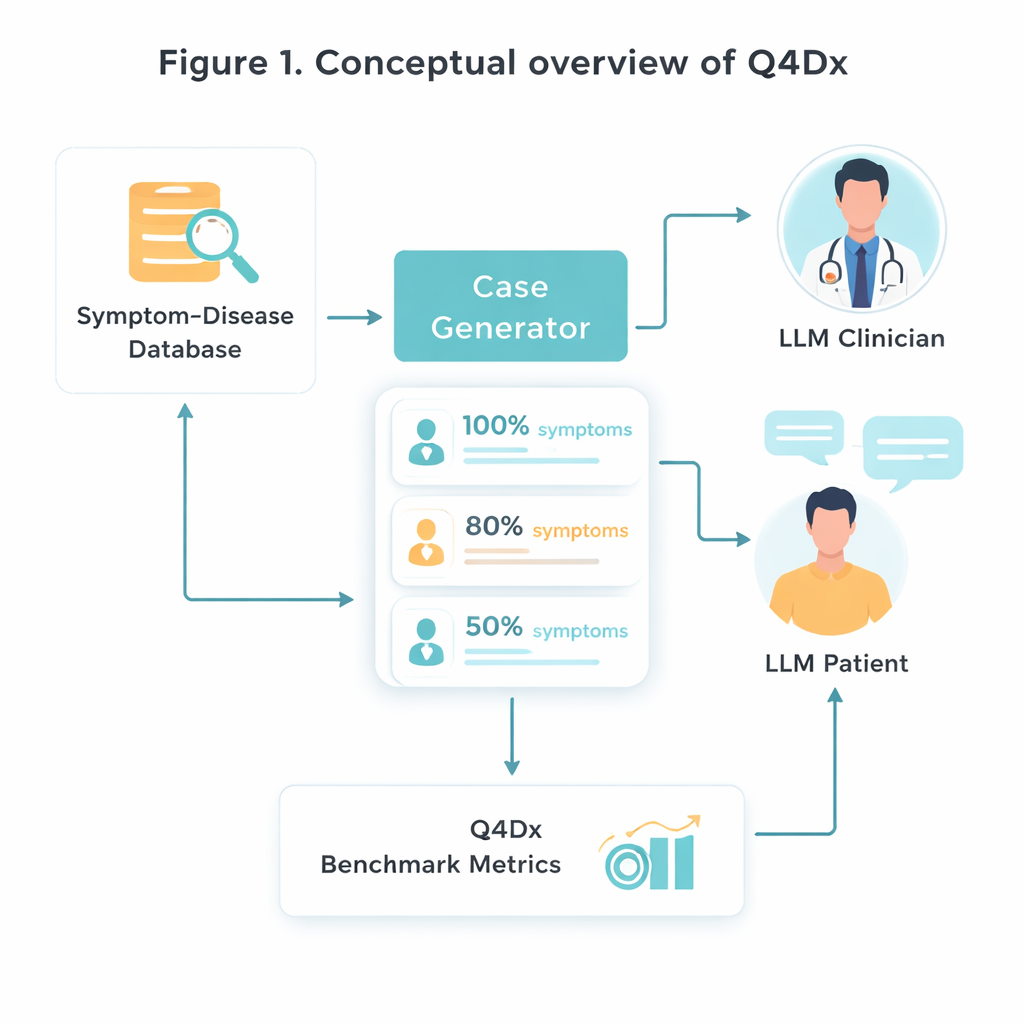
Эмулированные диалоги врач–пациент
Сердце Q4Dx — большая коллекция смоделированных разговоров между двумя агентами ИИ. Один играет роль пациента и имеет полный доступ к базовому заболеванию и его полному набору симптомов. Другой выступает врачом: он видит только частичное, возможно нечеткое описание случая в начале и должен решать, что спросить дальше. После каждого ответа пациента врач-агент делает предварительный диагноз, создавая пошаговую цепочку эволюции своих предположений. Записывая все вопросы, ответы и промежуточные догадки, бенчмарк фиксирует не только то, правильно ли модель отвечает, но и как она приходит к выводу. Эти последовательности вопросов, сгенерированные ИИ, используются как эталонные стратегии — не как безупречная медицинская истина, а как согласованная шкала, по которой можно сравнивать будущие модели и даже человеческих стажёров.
Оценка хороших вопросов, а не только правильных ответов
Для оценки производительности авторы разрабатывают три простые, но дополняющие друг друга метрики. Zero‑Shot Diagnostic Accuracy (ZDA) спрашивает: если дать модели полный случай сразу, сможет ли она немедленно назвать правильное заболевание? Mean Questions to Correct Diagnosis (MQD) отражает эффективность: в среднем, сколько вопросов пациенту нужно задать модели, прежде чем она впервые назовёт верный диагноз, с лимитом в пять вопросов? Наконец, Interrogation Sequence Efficiency (ISE) оценивает качество самого пути опроса — насколько по смыслу выбранные моделью вопросы соответствуют эталонной последовательности. С помощью этих метрик команда показывает, что сильная универсальная модель (GPT‑4.1) правильно диагностирует примерно в половине случаев при наличии полной информации, но её точность падает по мере «скрытия» симптомов. В то же время её интерактивные сессии обычно завершаются успехом после всего нескольких удачно выбранных вопросов, и её вопросы становятся более согласованными со стратегиями экспертов по мере нескольких ходов.

Что это значит для будущего медицинского ИИ
Для неспециалистов посыл этой работы прост: в медицине умение задавать умные вопросы так же важно, как и иметь правильные ответы, и ИИ нужно оценивать по обеим сторонам. Q4Dx предлагает повторяемую, общедоступную платформу для такой оценки. Предоставляя правдоподобные истории пациентов с различным количеством недостающей информации, подробные следы бесед и чёткие меры как точности, так и эффективности, этот бенчмарк позволяет исследователям сравнивать разные системы ИИ и даже сопоставлять их с человеческими клиницистами в контролируемых условиях. Со временем инструменты вроде Q4Dx могут помочь обучать более безопасных и надёжных клинических ассистентов и улучшать обучение врачей и студентов диагностическому интервьюированию — в конечном счёте поддерживая лучшее лечение реальных пациентов.
Цитирование: Werthaim, M., Kimhi, M., Apartsin, A. et al. A benchmark for evaluating diagnostic questioning efficiency of LLMs in patient conversations. Sci Rep 16, 6121 (2026). https://doi.org/10.1038/s41598-026-37022-y
Ключевые слова: медицинский ИИ, диагностическое мышление, клинический диалог, большие языковые модели, стратегия опроса