Clear Sky Science · ru
Бенчмаркинг моделей распознавания действий для выявления самоповреждений в студийных и реальных наборах данных
Надзор за пациентами «цифровыми глазами»
В психиатрических больницах медсёстры неустанно трудятся, чтобы обеспечить безопасность пациентов, особенно тех, кто может причинить себе вред. Но даже самые преданные сотрудники не могут наблюдать за каждой палатой каждую секунду. В этом исследовании проверяют, может ли искусственный интеллект (ИИ) помочь, автоматически анализируя видео с камер отделений, чтобы обнаруживать ранние признаки самоповреждений — предлагая дополнительный уровень защиты, не заменяя при этом человеческий уход.
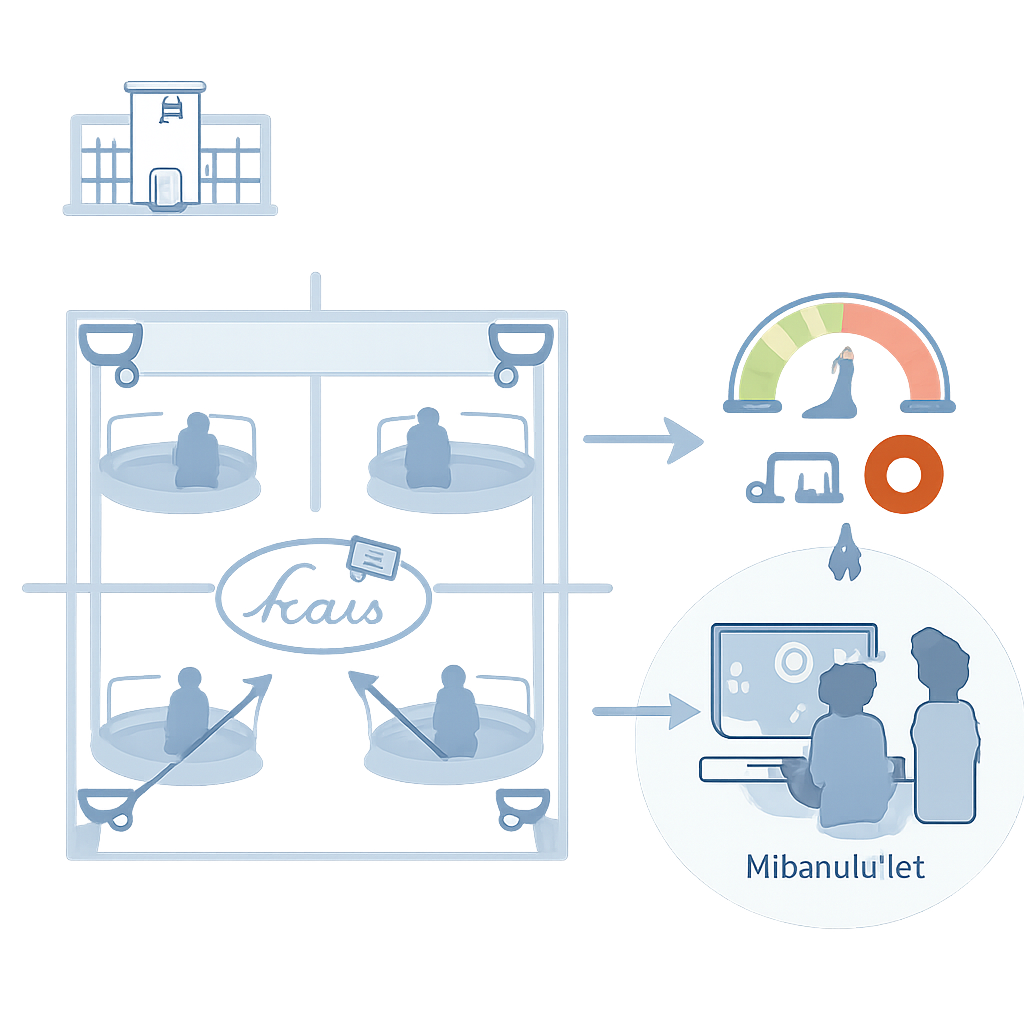
Почему самоповреждения так трудно заметить
Самоповреждение — любое намеренное причинение себе вреда — часто происходит быстро и незаметно: резкий порез под одеялом или небольшой инструмент, использованный вне поля зрения. Психиатрические отделения полагаются на регулярные обходы и видеонаблюдение, но «слепые зоны», усталость персонала и ограниченное дежурство ночью или в праздники делают постоянную бдительность невозможной. При этом запись и распространение реальных кадров пациентов вызывает серьёзные вопросы приватности и этики. В результате у исследователей было очень мало реалистичных видеоданных для обучения ИИ, который мог бы в реальном времени обнаруживать опасное поведение.
Создание более безопасных тестовых наборов для ИИ
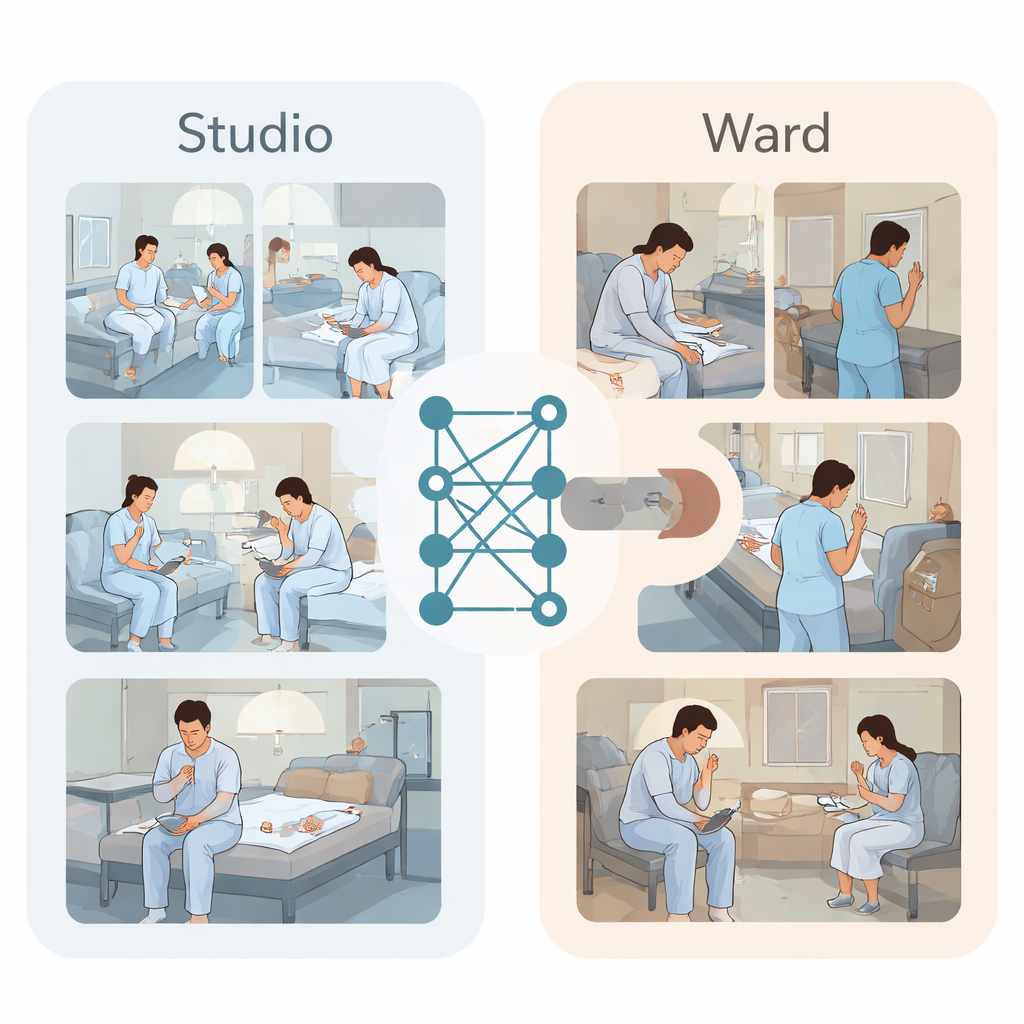
Чтобы преодолеть этот тупик, авторы собрали два типа видеоданных. Во-первых, в студии, стилизованной под четырёхместную психиатрическую палату, семь молодых актёров в больничных халатах разыгрывали заранее спланированные сцены. Они искали повседневные предметы — пластмассовые крышки, тюбики от бальзама для губ, небольшие гвоздики — а затем инсценировали короткие эпизоды самоповреждающих движений на запястье, предплечье или бедре; камеры сверху записывали со всех углов. Эксперты разметили каждый видеоролик как нормальное поведение или самоповреждение, сформировав аккуратную, сбалансированную коллекцию из 1120 клипов. Во-вторых, команда собрала реальные записи с камер безопасности из защищённых психиатрических отделений за десять месяцев. Клинические сотрудники искали в медицинских записях пометки о таких действиях, как расчесывание, ковыряние или порезы, и затем находили соответствующее видео. После размытия лиц и удаления идентифицирующих деталей они собрали 59 клипов с фактическими самоповреждениями и 59 нормальных клипов для сравнения.
Испытание современных видеомоделей ИИ
Имея эти наборы данных, команда провела бенчмаркинг ведущих систем распознавания действий — компьютерных программ, которые призваны понимать, что делают люди на видео. Некоторые модели опирались на более старые сверточные сети, анализирующие короткие последовательности кадров, тогда как новейшие трансформерные модели используют механизмы внимания, связывая шаблоны в пространстве и времени. Все модели обучались только на студийных видео, чтобы классифицировать клип как самоповреждение или нормальное поведение. Важно, что исследователи применяли строгую схему тестирования: в каждом раунде все клипы одного актёра исключались как полностью новые тестовые данные, что гарантировало, что алгоритмы не могли просто запомнить отдельных людей.
Когда чистая студийная съёмка встречается с беспорядочной реальностью
На аккуратных студийных записях выделялась самая продвинутая трансформерная модель, называемая VideoMAEv2. Она лучше балансировала пропуски и ложные тревоги по сравнению с остальными, достигая F1-метрики (комбинированная мера точности и полноты) примерно 0,65, в то время как более простые методы находились близко к случайному угадыванию. Визуальные объяснения показали, что модель сосредотачивалась точно на месте контакта инструмента с кожей, а не отвлекалась на фоновые движения. Но когда те же обученные системы запустили на реальных записях из отделений — без дообучения — их эффективность упала. VideoMAEv2 всё ещё показывала результат лучше случайного, с F1 около 0,61, однако особенно плохо она справлялась с тонкими действиями, такими как ковыряние и расчёсывание, которых не было в моделированных данных, а также с пациентами, которые были невысокого роста, находились далеко от камеры или были частично закрыты.
Что это означает для безопасности пациентов
В совокупности результаты показывают явный разрыв «симуляция‑в‑реальность». Системы ИИ, многообещающе показавшие себя на тщательно инсценированных видео, могут давать сбои при столкновении с беспорядком, необычными ракурсами и разнообразием поведения в реальной больничной среде. Главный вклад исследования — не готовое средство безопасности, а отправная точка: публичный, хорошо размеченный студийный набор данных, аккуратно собранный реальный тестовый набор и прозрачный бенчмарк, показывающий, где современные методы терпят неудачу. Для неспециалистов посыл простой: ИИ уже может помогать выделять подозрительные моменты в видеопотоках отделений, но пока ему нельзя доверять как единственному стражу. Для устранения этого разрыва потребуются более богатые, разнообразные обучающие данные и более умные модели, создаваемые с учётом приватности, справедливости и клинического суждения.
Цитирование: Lee, K., Lee, D., Ham, HS. et al. Benchmarking action recognition models for self-harm detection in studio and real-world datasets. Sci Rep 16, 6850 (2026). https://doi.org/10.1038/s41598-026-36999-w
Ключевые слова: выявление самоповреждений, психиатрические палаты, распознавание действий по видео, искусственный интеллект в здравоохранении, безопасность пациентов