Clear Sky Science · ru
MQADet: plug-and-play парадигма для улучшения обнаружения объектов с открытым словарём посредством мультимодального вопросно-ответного подхода
Почему более умные поисковики объектов важны
Телефоны, автомобили, домашние роботы и поисковые системы всё чаще полагаются на ПО, которое умеет находить объекты на изображениях: ребёнка, переходящего дорогу, ваши потерянные ключи на столе или конкретный товар на полке. Но большинство современных систем понимают только короткие простые метки вроде «собака» или «машина». Если вы попросите «маленькую собаку с красным ошейником, лежащую за подушкой дивана», они часто запутаются. В этой статье представлена MQADet — способ улучшить существующие системы поиска объектов, чтобы они понимали такие богатые, подробные описания без дообучения основных моделей.
От фиксированных списков к открытой интерпретации
Традиционные детекторы объектов обучаются на фиксированных наборах категорий, например на 80 повседневных классах популярного датасета COCO. Они хорошо работают, пока объект относится к одной из этих категорий и запрос короткий и понятный. Однако реальный мир сложен. Люди описывают вещи длинными фразами, тонкими атрибутами и отношениями, например «мужчина в жёлтом жилете, стоящий за грузовиком». Новые «обнаружители с открытым словарём» пытаются выйти за пределы фиксированных списков, связывая изображения с текстом, но им всё ещё сложно обрабатывать сложные формулировки и редкие, «длиннохвостые» категории, которые редко встречаются в данных обучения. Для улучшения им также требуется много вычислений и данных.
Дать языковым моделям руководить поиском
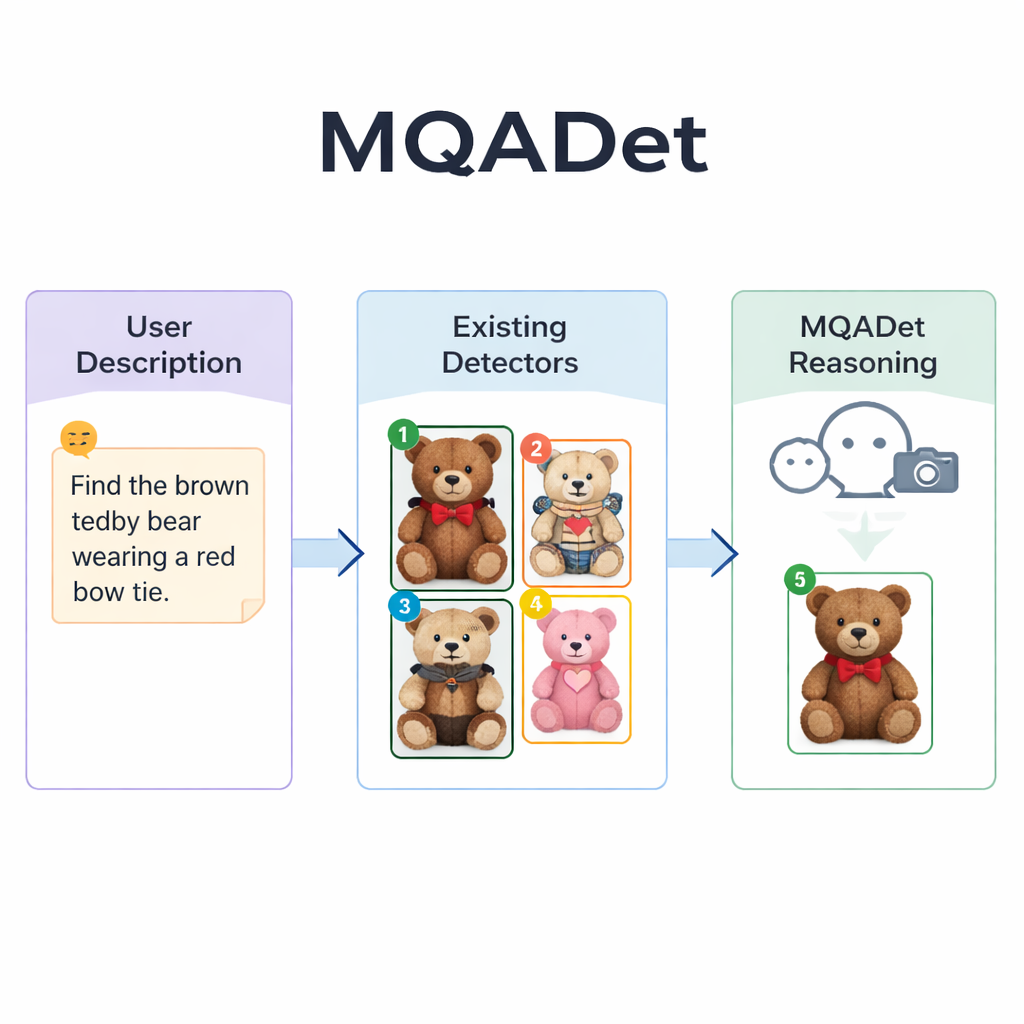
MQADet решает эти проблемы, располагая мультимодальную большую языковую модель — систему, которая может смотреть на изображения и читать текст — поверх существующих детекторов в трёхэтапном процессе вопросно-ответного взаимодействия. Сначала этап, называемый Text-Aware Subject Extraction, читает полное предложение пользователя и выделяет истинные объекты интереса, например «зонт» и «пешеход» из длинного описания. Это похоже на то, как человек быстро определяет основные существительные в предложении перед тем, как осмотреть сцену. Важно, что этот этап использует хорошее понимание естественного языка моделью, поэтому он умеет работать с длинными описательными фразами, а не только с отдельными словами.
Отмечаем кандидатов на изображении
На втором этапе, Text-Guided Multimodal Object Positioning, MQADet передаёт извлечённые объекты вместе с изображением существующему детектору с открытым словарём — например, Grounding DINO, YOLO-World или OmDet-Turbo. Детектор предлагает несколько возможных мест на изображении, где может находиться каждый объект, рисуя рамку вокруг каждого кандидата и помещая простой номер внутри рамки. В результате получается «отмеченное изображение», показывающее все правдоподобные варианты. Важно, что MQADet не дообучает эти детекторы — он просто использует их как есть. Это делает подход plug-and-play: когда появляется более хороший детектор, его можно просто вставить в конвейер без дополнительных данных или настройки.

Рассуждение для выбора наилучшего совпадения
Третий этап, называемый MLLMs-Driven Optimal Object Selection, превращает окончательный выбор в вопрос с несколькими вариантами для языковой модели: учитывая исходное описание и отмеченное изображение с пронумерованными рамками, какой номер лучше всего соответствует тексту? Поскольку модель видит и детальную формулировку, и визуальную компоновку, она может учитывать тонкие подсказки — узоры, цвета, пространственные отношения вроде «слева» и взаимодействия между объектами. Авторы показывают, что без этого шага рассуждения точность резко падает, что подчёркивает его важность. Благодаря этой трёхшаговой архитектуре MQADet повысил точность на четырёх требовательных бенчмарках с длинными естественными предложениями, часто улучшая работу существующих детекторов на 10–40 процентных пунктов без изменения их внутренних весов.
Что это означает для повседневных технологий
Для неспециалиста ключевое сообщение в том, что больше не нужно перестраивать детекторы объектов с нуля, чтобы сделать их умнее. MQADet действует как интеллектуальный помощник поверх текущих систем, помогая им интерпретировать богатые человеческие описания и выбирать правильный объект в сложных сценах. Это может сделать визуальный поиск, помощников и автономные устройства более надёжными при работе с естественной речью людей — полной деталей, нюансов и контекста — прокладывая путь к более интуитивному взаимодействию с визуальным миром на основе языка.
Цитирование: Li, C., Zhao, X., Zhang, J. et al. MQADet: a plug-and-play paradigm for enhancing open-vocabulary object detection via multimodal question answering. Sci Rep 16, 6286 (2026). https://doi.org/10.1038/s41598-026-36936-x
Ключевые слова: обнаружение объектов с открытым словарём, мультимодальные большие языковые модели, визуальное вопросно-ответное взаимодействие, компьютерное зрение, понимание изображений