Clear Sky Science · ru
Преодоление разрыва в производительности: системная оптимизация локальных LLM для извлечения PHI из японских медицинских записей
Почему это важно для конфиденциальности пациентов
Больницы аккумулируют большие массивы медицинских записей, которые могли бы улучшить уход и исследования, но эти документы полны чувствительных данных: имён, адресов, дат. Мощные облачные AI‑системы хорошо справляются с сокрытием такой информации, однако многим больницам запрещено отправлять сырые данные пациентов на внешние серверы. В этом исследовании показано, что при тщательной настройке небольшие модели, работающие полностью внутри больницы, могут удивительно близко приблизиться к результатам ведущих облачных систем — предлагая способ использовать ИИ, сохраняя данные пациентов на месте.
Дилемма: приватность против прогресса
Современные большие языковые модели способны надёжно обнаруживать и удалять защищённую медицинскую информацию (PHI) из текста, часто превышая 90 процентов точности. Тем не менее отправка неизменённых записей пациентов в облачные сервисы создает правовые и этические риски в рамках таких регуляций, как HIPAA, GDPR и японский APPI. Многие учреждения настаивают на полной «суверенности данных», то есть чтобы информация никогда не покидала их компьютеры. До сих пор локальные модели, способные работать на внутреннем оборудовании, обычно пропускали гораздо больше идентификаторов, заставляя больницы выбирать: мощный анализ в облаке или более строгая приватность с менее эффективными инструментами. Авторы решили проверить, можно ли сократить этот разрыв настолько, чтобы обеспечить применение в реальной клинической практике.
Пошаговый план для более умного локального ИИ
Команда разработала пятиступенчатую схему оптимизации, чтобы постепенно улучшить работу локальных языковых моделей по удалению PHI из японских радиологических отчётов. Они начали с 14 разных моделей разных размеров, все запущены на изолированном компьютере без доступа в интернет, имитирующем безопасность больницы. На базе 160 тщательно сгенерированных синтетических отчётов — реалистичных, но полностью вымышленных — оценивали, насколько каждая модель обнаруживает и отделяет восемь типов идентификаторов: от имён и номеров документов до дат и подразделений. После исходного теста создали более полезные общие подсказки, затем адаптировали инструкции под особенности каждой модели, добавили автоматизированный цикл «самопроверки и исправления» и в конце протестировали лучшие кандидаты на отложенной выборке. 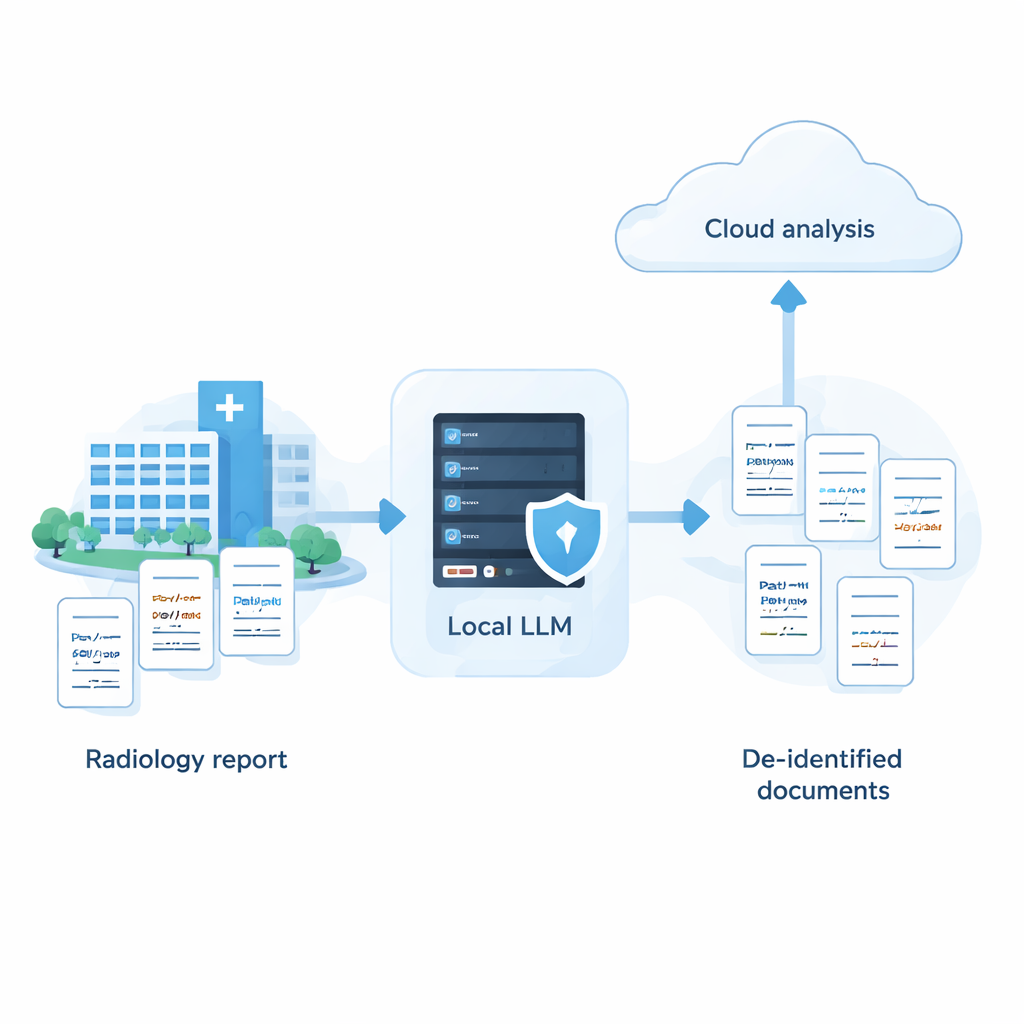
Приближение к облачному уровню
В ходе этого пошагового процесса исследователи обнаружили, что размер модели сам по себе не является ключом к успеху; некоторые очень большие системы всё ещё работали плохо. Наиболее перспективными оказались модели, которые хорошо реагировали на продуманное проектирование инструкций и анализ ошибок. Одна модель среднего класса, Mistral‑Small‑3.2, стала явным лидером после индивидуальных подсказок и шага самосовершенствования, где модель просматривала и выборочно исправляла свои ответы. По итоговым 60 тестам эта оптимизированная локальная конфигурация набрала 91,54 из 100 баллов — примерно 97,8 % от 93,56 балла ведущей облачной модели — при идеальном соблюдении правил форматирования. С практической точки зрения оставшееся отставание признали клинически несущественным. Основная цена — скорость: локальная обработка занимала около 25 секунд на типичный отчёт против менее 2 секунд в облаке, но это считалось приемлемым для рутинной пакетной обработки, не связанной с неотложной помощью. 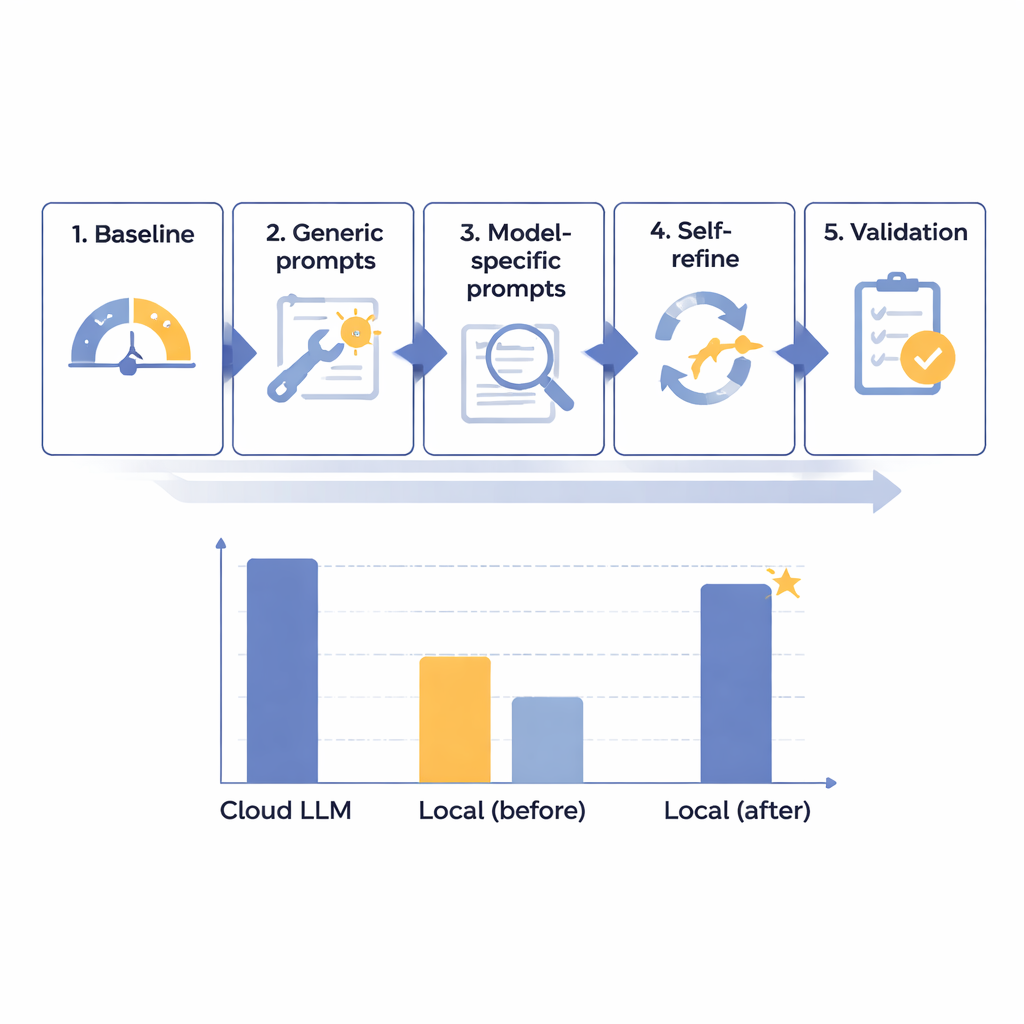
Неожиданный порог для самокоррекции
Одно из наиболее интересных наблюдений — некий переломный момент около 87–88 баллов по 100‑балльной шкале авторов. Модели, набравшие ниже этого уровня на исходном этапе — например, Mistral‑Small‑3.2 — существенно выигрывали от цикла самосовершенствования, добавляя почти семь баллов за счёт исправления небольшой доли собственных ошибок. Модели, которые изначально превышали этот порог, почти не улучшались и иногда тратили ресурсы, пытаясь «исправить» уже верные ответы. Это указывает на то, что продвинутые инструменты оптимизации лучше применять для моделей, которые хороши, но ещё не отличны, позволяя больницам концентрировать вычислительные ресурсы и труд сотрудников там, где отдача будет максимальной. Авторы предупреждают, что этот порог основан лишь на двух моделях и требует подтверждения, но он даёт раннее практическое правило при планировании развертывания.
Что это значит для больниц и пациентов
Исследование показывает, что больницам не нужно выбирать между надёжной приватностью и мощным ИИ. При системном подходе — скрининг множества моделей, настройка подсказок с учётом сильных и слабых сторон и добавление интеллектуального шага самопроверки — полностью локальная система может приблизиться по точности к ведущим облачным сервисам при удалении чувствительной информации из медицинского текста. На практике это открывает возможность гибридной стратегии: PHI удаляется безопасно на машинах, принадлежащих больнице, а в облако отправляются только анонимизированные отчёты, из которых удалены имена и другие идентификаторы, для более продвинутого анализа. Хотя работа пока базируется на синтетических японских радиологических отчётах и требует проверки на реальных данных и других языках, она предлагает практическую дорожную карту для учреждений, желающих использовать ИИ, сохраняя доверие пациентов и защищая их приватность.
Цитирование: Wada, A., Nishizawa, M., Yamamoto, A. et al. Bridging the performance gap: systematic optimization of local LLMs for Japanese medical PHI extraction. Sci Rep 16, 5910 (2026). https://doi.org/10.1038/s41598-026-36904-5
Ключевые слова: деидентификация медицинских данных, конфиденциальность пациентов, локальные языковые модели, ИИ в здравоохранении, радиологические отчёты