Clear Sky Science · ru
Оценка дисперсии на основе машинного обучения при двухфазной выборке с использованием данных здравоохранения и образования
Почему более точные средние имеют значение для решений в реальном мире
Когда врачи исследуют артериальное давление или педагоги отслеживают оценки учащихся, их интересует не только среднее значение — важно также понять, насколько сильно люди отличаются друг от друга вокруг этого среднего. Это рассеяние, называемое вариабельностью, подсказывает, сколько пациентов нужно набрать в клиническое исследование, какого масштаба должен быть репетиторский проект или насколько обоснованы политические решения. Статья, лежащая в основе этого обзора, предлагает новый, статистически обоснованный способ более точной оценки этой вариабельности, объединяющий классические идеи выборки с современным машинным обучением и проверенный на данных здравоохранения и образования.
Измерение разброса при неполной информации
В идеале исследователи знали бы дополнительные характеристики каждого человека в популяции до проведения опроса: возраст, учебные привычки, медицинскую историю и прочее. На практике такая информация часто фрагментарна или дорога в сборе. Авторы работают в рамках конструкции, называемой двухфазной выборкой, чтобы справиться с этим. На первой фазе берут большую, относительно недорогую выборку и фиксируют простую фоновые характеристики, например возраст или наличие доступа в интернет. На второй фазе отбирают меньшую подселекцию и измеряют более дорогой или долгий результат, например систолическое давление или итоговые экзаменационные оценки. Задача — использовать эти два уровня информации, чтобы оценить, насколько сильно результат варьируется во всей популяции.
Новый оцениватель, использующий и числовые, и бинарные признаки
Большинство традиционных методов измерения вариабельности опираются только на сам результат или на одну вспомогательную переменную и часто предполагают удобные колоколообразные распределения. Авторы предлагают новый оцениватель дисперсии, который одновременно использует два вида дополнительной информации: числовую вспомогательную переменную (например возраст или еженедельное время учёбы) и бинарный признак «да/нет» (например пол или доступ в интернет). Они математически выводят поведение этого комбинированного «смесевого» оценивателя, получая формулы для его смещения и среднеквадратичной ошибки — двух ключевых мер точности. При разумных условиях оцениватель фактически несмещён, а его ожидаемая ошибка меньше, чем у широко применяемых конкурирующих формул, то есть он обеспечивает более острые оценки неопределённости при тех же объёмах данных.
Проверка работы в разных моделях данных
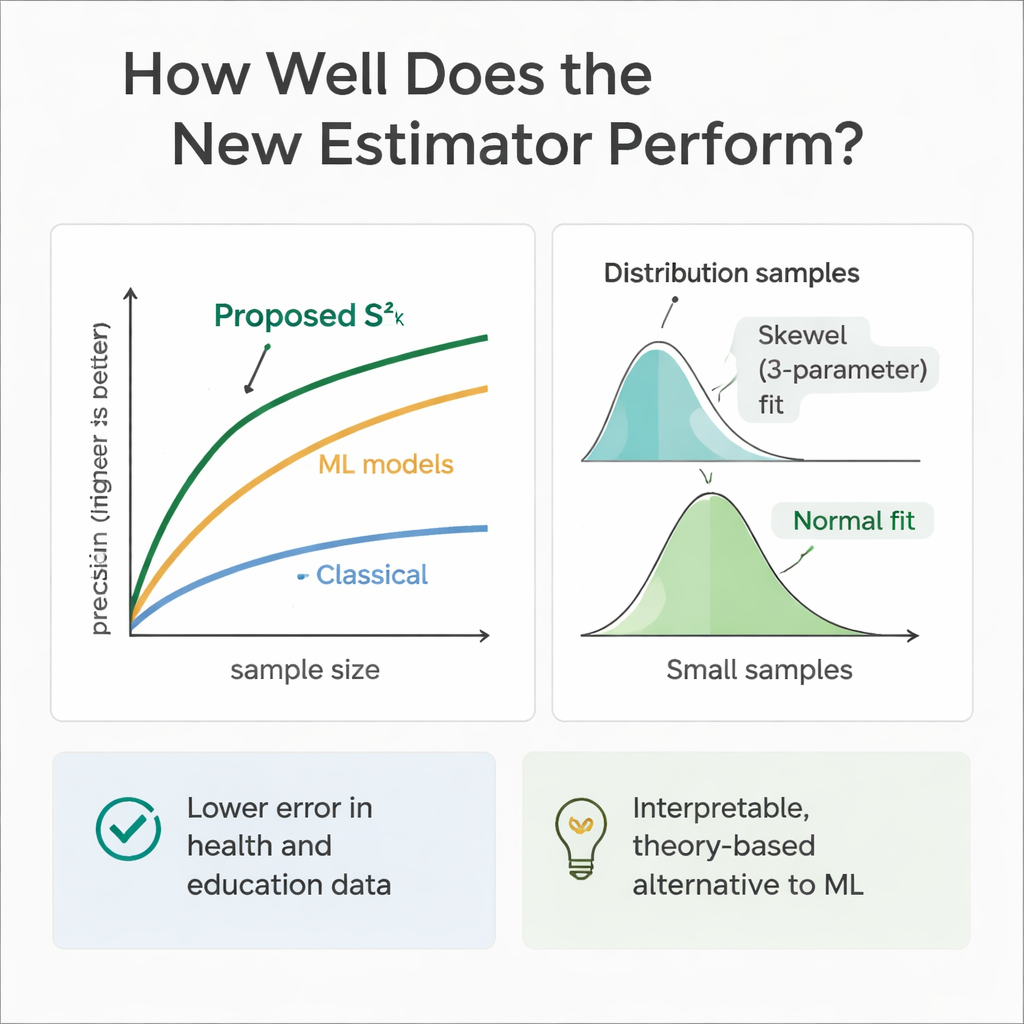
Чтобы проверить, совпадает ли теория с практикой, команда провела обширные компьютерные эксперименты. Они смоделировали популяции, где вспомогательные переменные и результат следовали ряду распределений — от симметричных (нормальное и равномерное) до скошенных (гамма и Вейбулла). С помощью повторных выборок сравнивали ошибку нового оценивателя с несколькими устоявшимися методами при разных размерах выборок. Почти во всех сценариях, особенно при увеличении объёма выборки, новый подход демонстрировал значительно большую относительную эффективность — часто снижая ошибку на 30–70 процентов по сравнению с классическим оценивателем дисперсии. Авторы также изучали распределение самого оценивателя по результатам выборок и обнаружили, что для умеренных объёмов выборки его лучше всего описывает гибкая трёхпараметрическая кривая Вейбулла, тогда как при больших объёмах оно стремится к нормальному виду.
Реальные данные из клиник и классов
Метод затем был применён к двум реальным кейсам. В медицинском наборе данных результатом было систолическое артериальное давление, числовой вспомогательной переменной был возраст, а бинарным признаком — пол. В образовательном наборе данных результатом была итоговая оценка за курс, вспомогательной переменной — еженедельное время занятий, а признаком — наличие у студента доступа в интернет. В обоих случаях предложенный оцениватель дал наименьшую среднеквадратичную ошибку среди всех проверенных статистических конкурентов, существенно сужая оценку вариабельности вокруг среднего давления и среднего учебного результата. Это улучшение выражается в более точных доверительных интервалах и более надёжных сравнениях между группами или вмешательствами.
Как это соотносится с машинным обучением
Поскольку модели машинного обучения отлично справляются с предсказанием, авторы также обучили регрессионные деревья, случайные леса и метод опорных векторов в тех же смоделированных сценариях здравоохранения и образования. Эти модели, получающие те же вспомогательные переменные, часто сравнивались с новым оценивателем и иногда немного превосходили его по чистой предиктивной точности. Однако они ведут себя как «чёрные ящики»: трудно проследить, как именно они комбинируют информацию, и им не хватает ясных формул, необходимых для традиционного вывода в выборочных исследованиях. В отличие от них, предложенный оцениватель прозрачен и укоренён в теории выборки, что делает его проще в обосновании в нормативных, клинических или политических контекстах, где объяснимость важна не меньше, чем сырая производительность.
Что это значит для практических опросов
Проще говоря, работа показывает, что исследователи могут получить более надёжные меры разброса без существенного увеличения объёмов выборки, просто дисциплинированно используя даже минимальную дополнительную информацию, которую они уже собирают. Объединив числовой фактор (например возраст или время учёбы) с простым бинарным признаком (например пол или доступ в интернет) в двухэтапном плане выборки, новый оцениватель даёт более острые и стабильные оценки дисперсии, чем традиционные методы. Хотя продвинутые инструменты машинного обучения остаются полезными эталонами, этот подход предлагает практичное и интерпретируемое среднее решение, помогая аналитикам в здравоохранении и образовании делать более обоснованные выводы из ограниченных данных.
Цитирование: Al-Marzouki, S., Nafisah, I.A., Dalam, M.E.E. et al. Machine learning based variance estimation under two phase sampling using health and education sector data. Sci Rep 16, 7760 (2026). https://doi.org/10.1038/s41598-026-36844-0
Ключевые слова: дескриптивная выборка, оценка дисперсии, машинное обучение, медицинские данные, исследования в области образования