Clear Sky Science · ru
Обобщаемость и переносимость моделей машинного обучения, использующих гиперспектральные данные отражения для признаков кукурузы
Почему сканирование листьев растений важно для нашего будущего питания
Кормить растущее население в условиях меняющегося климата можно только с помощью культур, способных выдерживать жару, засуху и другие стрессы. Селекционерам важно знать, какие растения имеют нужное сочетание структуры листа, химии и фотосинтетической эффективности — но прямое измерение этих признаков для тысяч растений медленно и разрушительно. В этом исследовании проверяют, можно ли просто отсканировать листья кукурузы гиперспектральным датчиком и с помощью машинного обучения надежно заменить трудоемкие лабораторные измерения, даже когда растения выращиваются в разные годы и в меняющихся полевых условиях.
Световые отпечатки листьев кукурузы
Каждый лист отражает свет в закономерности, зависящей от пигментов, содержания воды и внутренней структуры. Гиперспектральные датчики фиксируют этот рисунок по сотням длин волн от видимого до ближнего инфракрасного диапазона, создавая подробный «отпечаток» каждого листа. Исследователи собрали такие отпечатки в разнообразной популяции кукурузы, выращенной в три последовательных сезона, а также измерили 25 признаков, описывающих анатомию листа (например, удельную площадь листа и соотношение углерод–азот), газообмен (как листья поглощают CO2 и теряют воду) и хлорофилльную флуоресценцию (позволяющую оценить эффективность и регуляцию фотосинтеза). Этот богатый набор данных позволил проверить, насколько хорошо разные статистические модели умеют преобразовывать спектры света в оценки признаков.
Обучение машин «читать» листья
Команда сосредоточилась на двух широко используемых, относительно простых подходах машинного обучения: частичной наименьших квадратов регрессии (PLSR) и линейной регрессии опорных векторов (SVR). Обе методики сжимают детализированные спектры в меньший набор информативных признаков, прежде чем связать их с измеренными признаками. Ученые тщательно сравнили способы настройки моделей, особенно какое число компонент следует использовать в PLSR, и как избежать переобучения. Они также проверяли, лучше ли подавать в модели отдельные измерения листьев, усреднения по одному участку или усреднения по всем растениям одной генотипической линии. Для оценки точности и неопределённости применили строгую вложенную кросс-валидацию — по сути повторяющиеся циклы обучения и тестирования.
Какие признаки предсказываются легче всего
Некоторые признаки листа оказались гораздо более «читаемыми» по спектрам света, чем другие. Структурные и биохимические признаки, такие как удельная площадь листа и содержание азота, предсказывались с высокой точностью, особенно когда данные усреднялись на уровне генотипа для уменьшения шумов измерений. Некоторые показатели фотосинтетической ёмкости и отдельные индикаторы флуоресценции хлорофилла, отражающие поведение фотосистемы II при освещении, также демонстрировали умеренную предсказуемость. Напротив, признаки, связанные с быстрыми, кратковременными процессами — например скорость включения или ослабления защитного рассеяния энергии — плохо улавливались. Для таких признаков спектральный сигнал либо слаб, либо легко перекрывается вариацией среды в момент измерения.
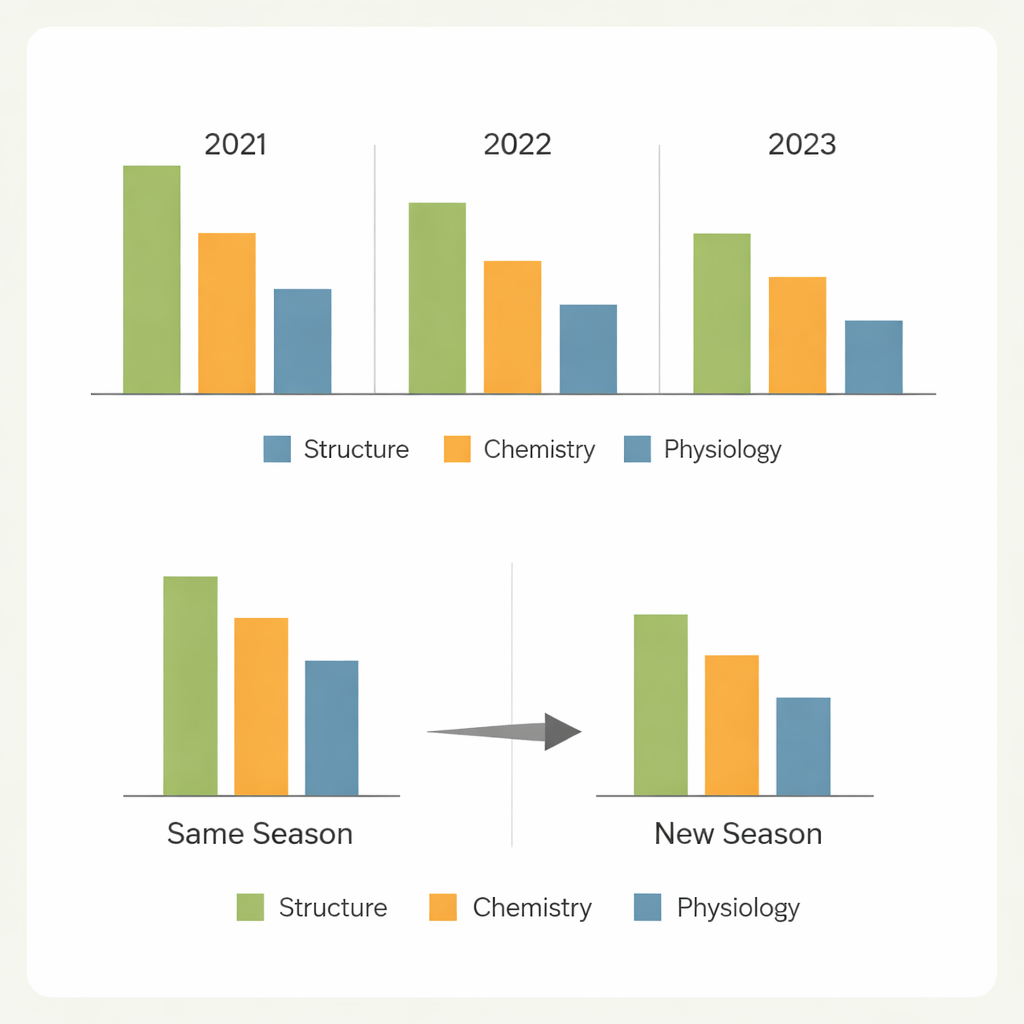
Из одного сезона в другой
Ключевой вопрос для практической селекции — можно ли доверять модели, обученной в одних условиях, в других. Когда модели предсказывали случайно выбранные растения в пределах того же сезона, производительность обычно была высокой для более простых признаков. Предсказание полностью новых генотипов, выращенных в том же сезоне, приводило лишь к умеренному снижению точности для структурных и связанных с азотом признаков, но к гораздо более резкому падению для признаков газообмена. Самое жесткое испытание — прогнозирование новых генотипов в другом году — выявило значительные потери точности, особенно для признаков, сильно зависящих от окружающей среды. Различия в погоде, состоянии полей и составе генотипов смещали спектральные паттерны достаточно, чтобы ограничить переносимость, причём один из сезонов оказался особенно трудным для предсказания по другим.
Что это означает для селекции и дистанционного зондирования
Для селекционеров и ученых по культурам исследование несет и обнадеживающие, и предостерегающие выводы. Гиперспектральное сканирование в сочетании с относительно простыми методами машинного обучения уже является мощным инструментом для высокопроизводительной оценки стабильных, интегративных признаков, таких как структура листа и азотный статус, и может достаточно хорошо обобщаться по генотипам и годам для этих целей. Однако тот же подход значительно менее надежен для быстрых, чувствительных к среде физиологических признаков при переносе моделей за пределы условий обучения. Авторы делают вывод, что гиперспектральные методы готовы поддерживать крупномасштабный отбор по некоторым ключевым признакам кукурузы, но предсказание динамического физиологического поведения в разных средах потребует более богатых учебных данных, более продвинутого моделирования и, возможно, дополнительных типов измерений.
Цитирование: Xu, R., Ferguson, J., Breil-Aubert, M. et al. Generalizability and transferability of machine learning models using hyperspectral reflectance data for maize traits. Sci Rep 16, 5865 (2026). https://doi.org/10.1038/s41598-026-36819-1
Ключевые слова: гиперспектральное отражение, кукуруза, машинное обучение, фенотипирование растений, фотосинтез