Clear Sky Science · ru
Таксономическое моделирование и классификация при отчетности о сбоях космического оборудования
Поиск закономерностей в сбоях полетов
Каждая миссия в космосе зависит от множества элементов оборудования, которые должны работать безотказно — от болтов и кабелей до систем жизнеобеспечения. Когда что-то идет не так, инженеры составляют подробные отчеты о несоответствиях, но у NASA сейчас более 54 000 таких записей — слишком много, чтобы люди могли просмотреть их вручную. В этом исследовании показано, как современные инструменты обработки языка и машинного обучения могут превратить эту гору текста в организованные знания, помогая инженерам обнаруживать шаблоны сбоев, улучшать конструкции и повышать безопасность экипажей.
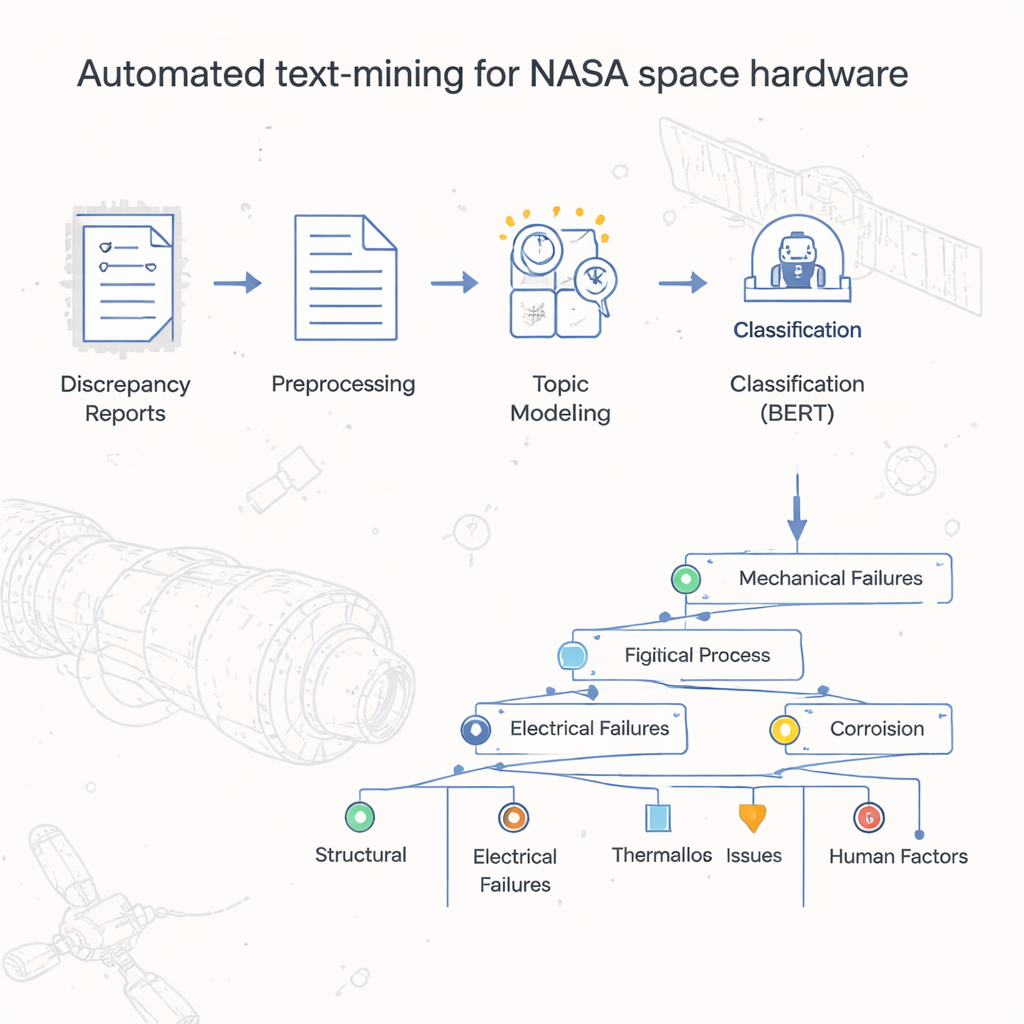
От груды отчетов к организованным выводам
Десятилетиями в Исследовательском центре Джонсона NASA хранили отчеты о сбоях и несоответствиях оборудования в виде цифровых документов, по сути сканов старых бумажных форм. Простая сводка в таблицах показывала, какие официальные коды дефектов встречаются чаще всего, но реальная картина — конкретные причины, шаги и условия, приведшие к проблемам — была зарыта в полях свободного текста. Просмотреть и классифицировать вручную более 54 000 записей было бы чрезмерно затратно по времени. Авторы поставили задачу создать автоматизированный способ классификации и группировки этих отчетов, построив своего рода «карту» или таксономию, отражающую, как на практике действительно происходят отказы космического оборудования.
Обучение компьютеров чтению инженерного языка
Команда сначала очистила текст в каждом отчете, чтобы компьютеры могли эффективно с ним работать. Они удалили посторонние символы и цифры, добавлявшие шум, разбили предложения на отдельные слова и привели их к более простой базовой форме (например, «leaked» и «leaking» к «leak»). Распространенные слова, не несущие значимой информации, такие как «the» или «and», были отфильтрованы. После стандартизации текста исследователи преобразовали его в числа, с которыми работают алгоритмы машинного обучения, используя проверенные методы, учитывающие частоту слов и степень, в которой слова характеризуют документ. Эта подготовка позволила применить мощные инструменты, разработанные для общих задач обработки языка, к специализированному набору отчетов о космическом оборудовании.
Построение дерева типов отказов
В основе проекта лежит двухэтапная модель, которую авторы называют LDA-BERT. Первый этап, Latent Dirichlet Allocation (LDA), автоматически обнаруживает темы — или топики — путем поиска шаблонов слов, которые часто встречаются вместе в тысячах отчетов. Один отчет может сочетать несколько тем, что отражает реальность, где одна аппаратная проблема может иметь несколько сопутствующих причин. Второй этап использует BERT, современную языковую модель, для проверки и уточнения того, насколько хорошо эти темы разделяют отчеты. Рассматривая LDA-темы как предварительные метки и обучая BERT предсказывать их, исследователи могли определить число и комбинацию тем, дающих стабильную и точную классификацию. Затем они дополнительно разделили каждую тему на подтемы с помощью кластеризации и статистических проверок, чтобы построить разветвляющуюся таксономию, которая организует отчеты об отказах — от общих кодов дефектов до детальных меток на уровне процессов.
Превращение таксономий в практические тренды
После создания таксономии команда визуализировала ее с помощью панелей управления и интерактивных инструментов. Каждую ветвь и подветвь дерева можно было связать с другой информацией в отчетах: когда проблема была впервые зафиксирована, сколько времени потребовалось на ее закрытие, какая организация отвечала и какое было принято окончательное решение. Временные графики показывали, становятся ли некоторые типы проблем — например, упущения при инспекции или ошибки в данных по допускам — более или менее частыми с течением лет. Карты слов давали быстрое представление о языке, используемом в каждом кластере, без чтения всех отчетов. Эти представления помогают менеджерам сосредоточиться на процессных сбоях с высокой динамикой и значительным воздействием, направляя обучение, изменение процедур или обновления дизайна туда, где они принесут наибольшую пользу.
Ограничения автоматического поиска первопричин
Исследователи также изучали инструменты, которые пытаются пойти дальше маркировки и поиска трендов и вывести прямые причинно-следственные связи из текста. Они тестировали системы вроде INDRA-Eidos и пользовательские правила, созданные с использованием библиотеки spaCy. Хотя эти инструменты могли извлечь некоторые пары «причина—следствие» и визуализировать их в виде интерактивных сетей, многие предложенные связи оказались слишком расплывчатыми или сбивающими с толку, чтобы быть полезными. На практике модели испытывали трудности, потому что в исходных отчетах часто не были явно указаны коренные причины; инженеры их подразумевали или отложили для последующего расследования. Исследование делает вывод, что надежная автоматизация обнаружения первопричин потребовала бы как более полно структурированного ввода данных — например, явных полей для вероятной причины, — так и более дорогой, сильно настроенной подготовки моделей, что не оправдано для одноразового анализа.
Почему это важно для будущих миссий
Преобразовав большой неструктурированный архив отчетов об отказах в ясную, многоуровневую таксономию, эта работа дает NASA практический инструмент для мониторинга того, как и почему возникают проблемы с оборудованием со временем. Несмотря на то что методы пока не могут заменить человеческое суждение для глубокого анализа первопричин, они превосходны в сканировании огромного объема текста, чтобы выделить места скопления проблем и типы вовлеченных процессов. Такое раннее предупреждение и структурированная аналитика помогают инженерным командам целенаправленно распределять внимание, уточнять процедуры и проектировать более надежные системы — конкретные шаги к более безопасным и устойчивым миссиям на Луну, Марс и дальше.
Цитирование: Palacios, D., Hill, T.R. Taxonomical modeling and classification in space hardware failure reporting. Sci Rep 16, 5868 (2026). https://doi.org/10.1038/s41598-026-36813-7
Ключевые слова: сбои космического оборудования, обработка естественного языка, темное моделирование, анализ инженерных рисков, отчеты NASA о несоответствиях