Clear Sky Science · ru
Проверка подлинности новостей на урду с помощью глубокого обучения и объединённых встраиваний BERT и GloVe
Почему важно выявлять фейковые новости на урду
В Пакистане и во всём мире всё больше людей получают новости с веб‑сайтов и в социальных сетях, а не из газет или телевидения. Эта смена формата упростила распространение ложных историй, особенно на национальных языках, таких как урду, где цифровые инструменты ограничены. В этом исследовании ставится простой, но срочный вопрос: может ли современный искусственный интеллект автоматически отличать подлинные новости на урду от фейковых, помогая обычным читателям, журналистам и платформам защищаться от вводящей в заблуждение информации?
Растущая проблема онлайн‑дезинформации
Авторы начинают с описания того, как сфабрикованные заголовки и искажённые материалы могут формировать общественное мнение, разжигать политическую напряжённость и даже наносить вред здоровью и финансам людей. Хотя многие сайты проверки фактов и исследовательские проекты сосредоточены на английском языке, региональные языки, такие как урду, часто остаются в стороне. Существующие ресурсы на урду включают лишь несколько тысяч материалов, многие из которых переведены с английского и посвящены узким темам, например политике. Это затрудняет обучение надежных компьютерных систем, которые могли бы распознавать подозрительный контент на языке, который читают большинство пакистанцев.
Создание большой коллекции новостей на урду
Чтобы сократить этот разрыв, исследователи собрали то, что они описывают как самый объёмный на сегодняшний день датасет фейковых новостей на урду: 14 178 статей, собранных в период с 2017 по 2023 годы с авторитетных пакистанских новостных сайтов и онлайн‑платформ. Материалы охватывают пятнадцать сфер повседневной жизни, включая политику, здравоохранение, образование, бизнес, преступность, спорт и экологию. С помощью источников проверки фактов, таких как PolitiFact и FactCheck, а также специализированных новостных API, каждая запись была помечена как настоящая или фейковая; материалы с частичной правдой были отнесены к реальным новостям, чтобы учесть более нюансированное отражение информации. Команда затем очистила тексты: убрала дубликаты, веб‑адреса и лишние знаки препинания, разбила предложения на слова и исключила очень распространённые служебные слова.
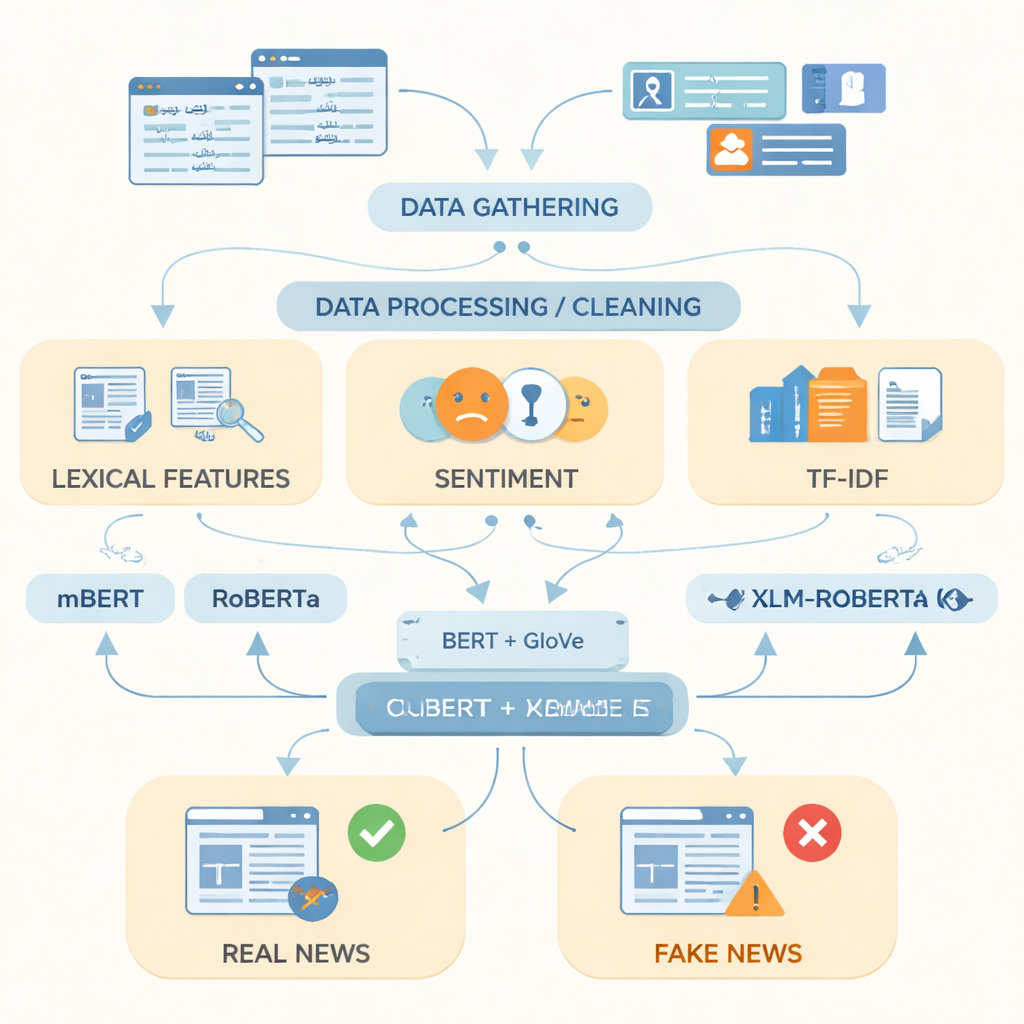
Обучение компьютеров распознавать фейковые новости
После подготовки данных авторы сосредоточились на том, как лучше представить текст на урду для компьютера. Они объединили простые признаки, такие как часто используемые слова, эмоциональную окраску языка и показатели частоты терминов, с двумя мощными техниками представления слов. Одна, называемая GloVe, представляет каждое слово как фиксированный числовой вектор, основанный на том, как часто оно встречается вместе с другими словами во всём корпусе. Другая, основанная на моделях типа BERT, учитывает слово в контексте предложения и присваивает ему контекстно-зависимое значение. Объединив эти два представления языка в одно, более богатое, система может уловить как общие закономерности, так и тонкие изменения в формулировках, которые часто отличают фейковые истории от реальных.
Тестирование продвинутых языковых моделей
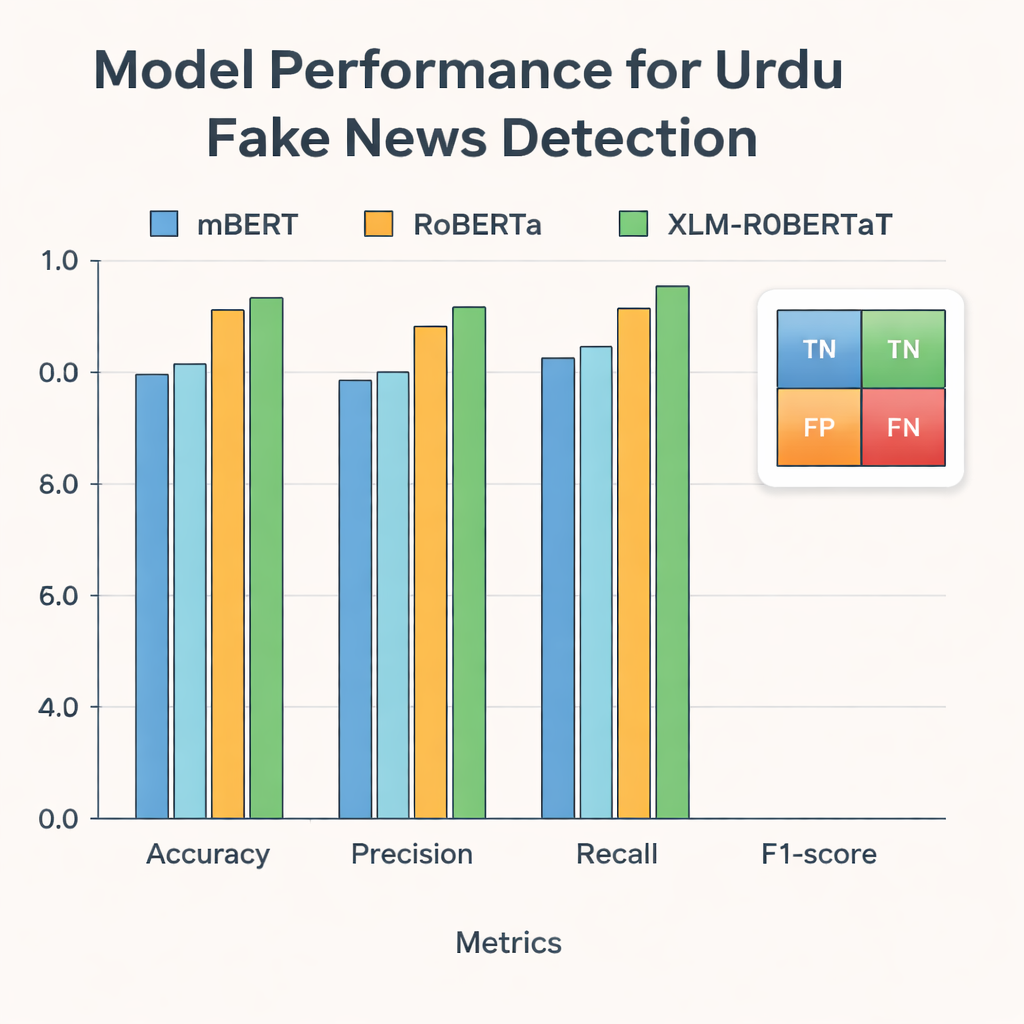
Затем исследователи подали эти представления в три современных модели глубокого обучения, натренированные на текстах многих языков: mBERT, RoBERTa и XLM‑RoBERTa. Все три были дообучены на датасете на урду для предсказания, является ли статья настоящей или фейковой. Их работу оценивали по стандартным метрикам: точности (как часто модель права), точности позитивных предсказаний (насколько часто помеченные как фейк материалы действительно фейковые), полноте (сколько из всех фейковых историй удалось поймать) и F1‑мере, которая уравновешивает точность и полноту. Все модели показали высокие результаты, но XLM‑RoBERTa в сочетании с объединёнными встраиваниями BERT и GloVe занял первое место, правильно классифицировав около 96 % тестовых статей и достигнув F1‑счёта 0,956 — лучше, чем предыдущие системы для урду, использовавшие меньшие датасеты или более простые методы.
Что это означает для обычных читателей
Для неспециалистов вывод прост: при наличии достаточно качественных данных на урду и правильных методов ИИ теперь возможно создать инструменты, которые автоматически помечают вероятно фейковые материалы с высокой надёжностью. Исследование показывает, что более богатые представления языка и многоязычные модели дают компьютерам куда лучшее представление о том, как урду фактически пишут в разных регионах и по разным темам. Хотя текущее исследование сосредоточено только на тексте и пока не анализирует изображения или поведение в социальных сетях, оно закладывает прочную основу для будущих систем, которые могли бы работать перекрёстно по языкам и типам медиа. Практически это приближает Пакистан к появлению расширений для браузеров, панелей для редакций или фильтров в соцсетях, которые помогут людям отличать факты от фикции на языке, которым они пользуются ежедневно.
Цитирование: Feroz, A., Abbasi, W., Babar, M.Z. et al. Verifying Urdu news authenticity using deep learning with concatenated BERT and GloVe embedding. Sci Rep 16, 7352 (2026). https://doi.org/10.1038/s41598-026-36771-0
Ключевые слова: обнаружение фейковых новостей, язык урду, глубокое обучение, BERT и GloVe, онлайн-дезинформация