Clear Sky Science · ru
Улучшение дальнего оценивания глубины через гетерогенное кодирование CNN‑трансформером и сквозное семантическое слияние
Видеть глубину одним оком
Современные роботы, беспилотные автомобили и дроны часто полагаются на дорогие 3D‑датчики, чтобы понять, насколько далеко расположены объекты. В этом исследовании показано, как обычные цветные камеры, такие как в смартфонах, можно использовать гораздо шире: авторы предлагают новый способ, с помощью которого компьютер восстанавливает глубину по одной фотографии, сосредоточившись на самой сложной части сцены — дальнем плане, где препятствия малы, размыты и легко ошибочно интерпретируются.
Почему удалённые объекты так трудно оценить
Определение глубины по одному изображению, или моноокулярная оценка глубины, — это своего рода визуальная хитрость. Близкие объекты занимают много пикселей и имеют чёткие текстуры, поэтому современные нейронные сети уже хорошо справляются на коротких и средних дистанциях. Однако дальше машины уменьшаются до нескольких пикселей, а дорожная разметка теряется в дымке. Стандартные сверточные нейронные сети хорошо улавливают локальные тонкости, но испытывают трудности с восприятием общей картины улицы. Новые модели‑трансформеры лучше захватывают глобальный контекст, но хуже реагируют на тонкие края и текстуры. В результате обе семьи методов нередко ошибаются именно там, где для безопасной навигации нужны надёжные оценки: на больших расстояниях.
Смешивание двух способов «видеть»
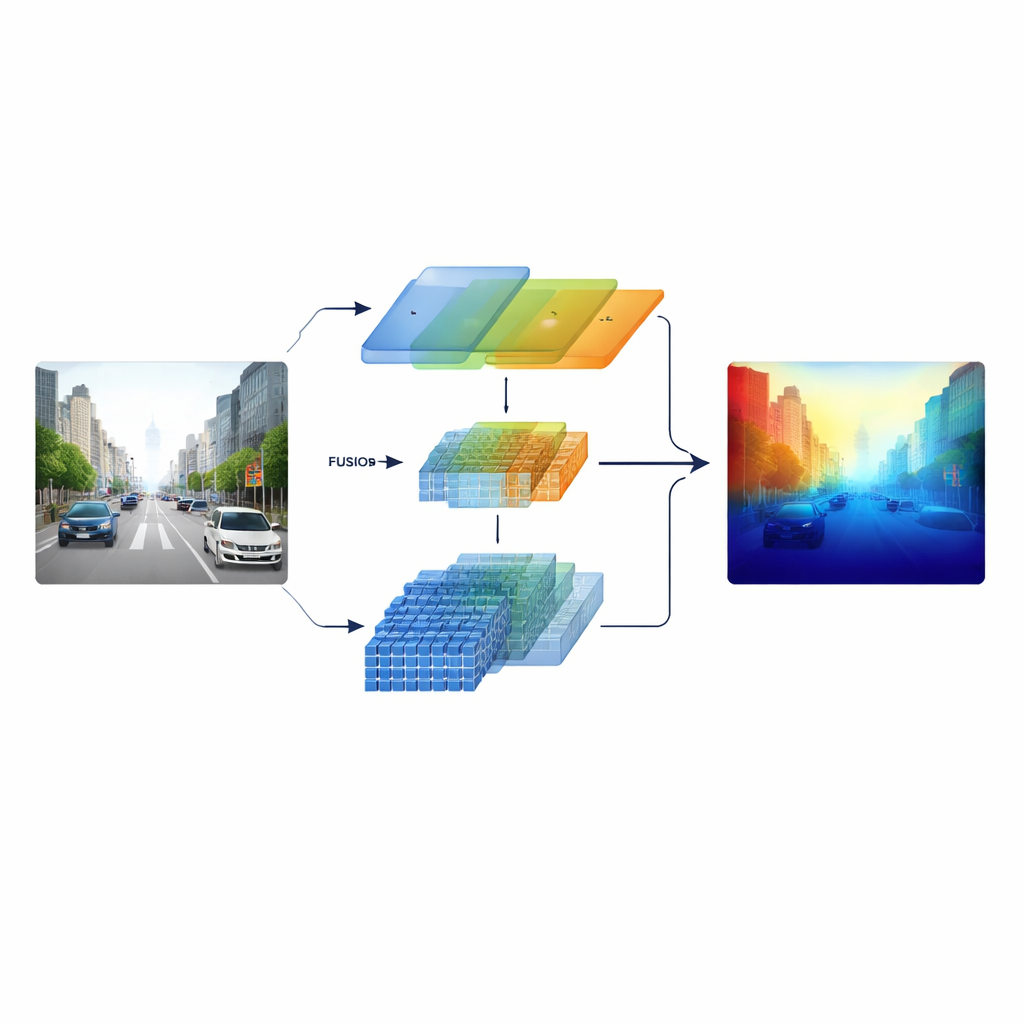
Исследователи решают эту проблему, построив «гетерогенный» энкодер, который параллельно запускает два разных типа визуальной обработки. Одна ветвь основана на классической сверточной сети в стиле ResNet и специализируется на чётких локальных паттернах — дорожной разметке, столбах и краях объектов. Другая ветвь использует Swin Transformer, предназначенный для захвата дальних взаимосвязей по всему изображению, таких как планировка дорожного коридора или силуэт отдалённых зданий. Вместо того чтобы объединять эти два представления только в конце, система сохраняет многоуровневые признаки из обеих ветвей и подаёт их на продуманную стадию слияния, так что тонкая структура и широкий контекст взаимодействуют на всех этапах обработки.
Перекрёстно по каналам, пространству и масштабам
В основе модели лежит модуль Cross‑dimensional Semantic Fusion, который функционирует как интеллектуальная переговорная для двух потоков информации. Сначала он решает, какие каналы — разные типы выученных визуальных паттернов — заслуживают большего внимания, уравновешивая сигналы от детализированных текстур и высокоуровневых сценических подсказок. Затем он отдельно анализирует горизонтальное и вертикальное направления, что особенно важно в сценах с дорогами, зданиями и деревьями, чтобы выделить протяжённые структуры. Наконец, он смешивает поверхностные, богатые деталями признаки с более глубокими абстрактными представлениями на нескольких масштабах. Обучаемая степень важности позволяет сети решать, насколько доверять каждой ветви в каждой области, чтобы мелкие удалённые объекты не терялись на фоне близких сцен.
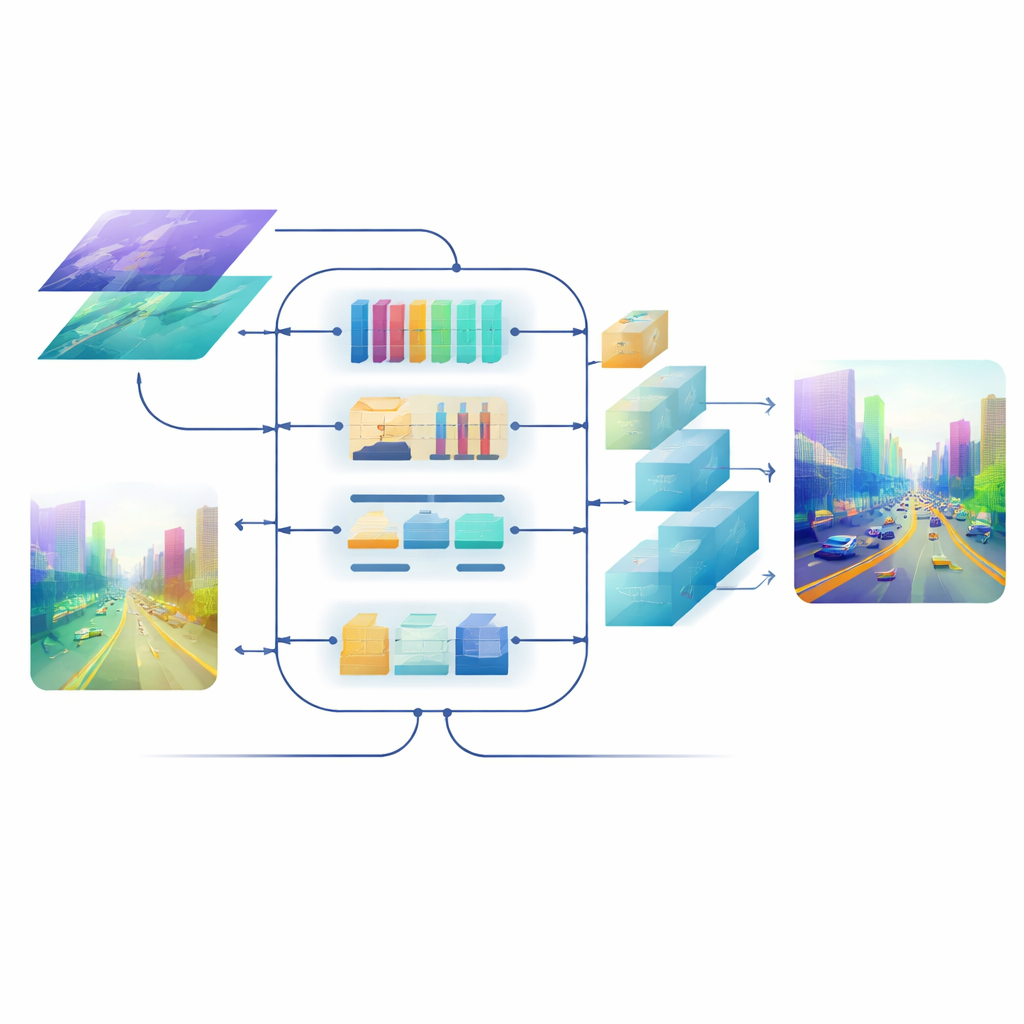
Уточнение конечной карты глубины
Даже при хорошем слиянии признаков их преобразование в полноразмерную карту глубины может размывать края и терять тонкие структуры. Чтобы этого избежать, команда разработала декодер с механизмом внимания. Его блоки апсэмплинга используют лёгкие глубинно‑разделяемые свёртки для увеличения карты без потери контекста, а многоуровневый механизм самовнимания группирует каналы признаков так, чтобы внимание вычислялось эффективно. Этот шаг уточняет предсказания глубины на каждом масштабе, сохраняя при этом разумные вычислительные затраты. В результате получается гладкое, согласованное поле глубины, где границы объектов — например контур удалённого велосипедиста или лестницы двухъярусной кровати — остаются чёткими.
Как это работает в реальных условиях
Метод протестирован на нескольких стандартных наборах данных. На KITTI, большом наборе сцен вождения, модель достигает передовой точности по большинству распространённых метрик и, что важно, даёт наименьшую ошибку в выделенных областях дальнего действия. Она также формирует более чистые границы глубины вокруг объектов по сравнению с конкурентами. На NYU Depth V2, содержащем интерьерные сцены, и на бенчмарке SUN RGB‑D та же модель успешно обобщается, восстанавливая мебель и планировку помещений в правдоподобные 3D‑облака точек. Абляционные исследования — систематические тесты с удалением или заменой компонентов — показывают, что каждая предложенная часть, от гибридного энкодера до модуля слияния и блока внимания в декодере, ощутимо улучшает результаты, особенно в отдалённых зонах с низкой текстурностью.
Что это значит для повседневных технологий
Проще говоря, эта работа учит нейросеть одновременно пользоваться увеличительным стеклом и широкоугольным объективом и грамотно их комбинировать. За счёт лучшего баланса локальных деталей и глобального понимания сцены предлагаемая архитектура существенно повышает способность одной камеры оценивать глубину далеко по дороге или по комнате. Это делает более практичным оснащение роботов, транспортных средств и дронов более дешёвыми датчиками, сохраняя при этом богатое 3D‑восприятие мира — важный шаг к более безопасным, функциональным и доступным автономным системам.
Цитирование: Chen, Y., Yin, Q., Zhao, L. et al. Enhancing long-range depth estimation via heterogeneous CNN-transformer encoding and cross-dimensional semantic fusion. Sci Rep 16, 9396 (2026). https://doi.org/10.1038/s41598-026-36755-0
Ключевые слова: оценка глубины по моноокулярному изображению, компьютерное зрение, слияние трансформера и CNN, автономное вождение, восстановление 3D‑сцены