Clear Sky Science · ru
Сопоставление средних в ядре улучшает оценку риска при пространственных сдвигах распределения
Почему важно оценивать риск при меняющейся карте
Модели машинного обучения всё чаще применяют для прогнозирования места обитания видов, организации опухолей в ткани или распространения загрязнений. При этом данные для обучения часто собирают в очень конкретных местах — плотная выборка около городов, больниц или доступных полевых участков — тогда как модели используются на куда более широких и иных территориях. Такое несоответствие между тем, откуда берутся данные, и тем, где делаются прогнозы, может создавать иллюзию большей безопасности и точности моделей, чем есть на самом деле. Статья «Kernel mean matching enhances risk estimation under spatial distribution shifts» задаёт кажущеся простым вопрос: когда мир отличается от ваших тренировочных данных, насколько модель может ошибаться и как это выявить?
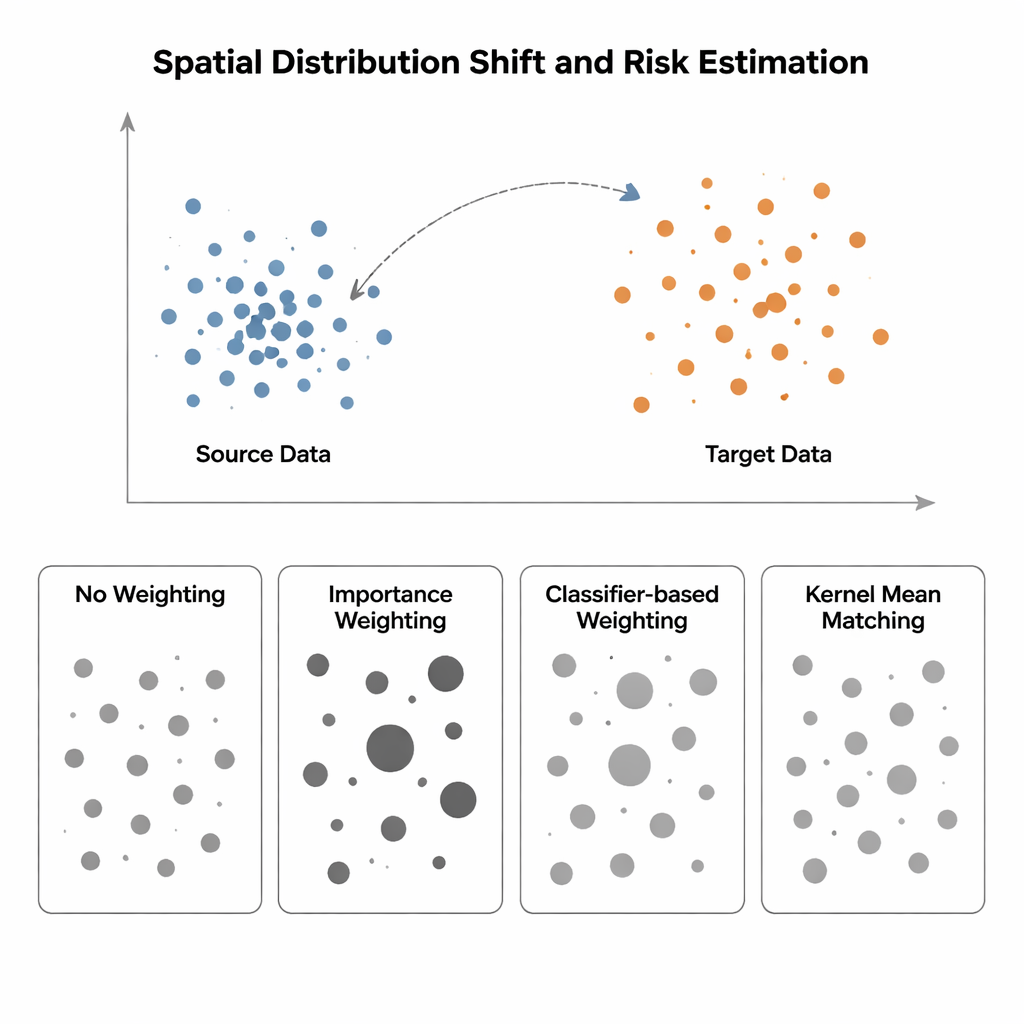
Когда обучение и тестирование происходят в разных мирах
В статистике «риск» модели — это её ожидаемая ошибка на новых, невиданных данных. Стандартные приёмы оценки — например, кросс-валидация или удержание случайного тестового набора — молча предполагают, что тренировочные и тестовые данные извлечены из одного и того же распределения. Пространственные данные нарушают это предположение. Экологические градиенты, кластерная выборка и изменение климата означают, что условия, в которых мы тренируем модель, могут сильно отличаться от условий её применения. Например, наблюдения видов часто сосредоточены возле дорог, тогда как решения по сохранению природы касаются удалённых районов; образцы опухолей могут браться из одной части ткани, а прогнозы требоваться в другой. В таких случаях традиционные оценки риска склонны быть чрезмерно оптимистичными, скрывая, насколько плохо модель может работать в новых местах.
Старые методы испытывают трудности при пространственной смещённости
В работе сравнивают четыре подхода к оценке риска модели, когда входное распределение смещается от «источника» (где известны метки) к «целевому» региону (где метки редки или отсутствуют). Самый простой метод, без взвешивания (No Weighting), просто измеряет среднюю ошибку на доступных данных и предполагает сходство источника и цели — предположение, которое рушится при пространственном смещении. Importance Weighting пытается это исправить, масштабируя каждый исходный образец в зависимости от того, насколько часто такие точки встречаются в целевом по сравнению с источником. Теоретически это восстанавливает корректный риск, но на практике требует оценки многомерных плотностей вероятности. Когда данные источника сильно сконцентрированы, а данные цели более разбросаны — типичная ситуация в пространственной экологии или медицинской визуализации — такие оценки плотностей становятся ненадёжными, и несколько образцов получают астрономические веса, делая оценку риска крайне нестабильной. Подходы на основе классификаторов, которые обучают классификатор отличать точки источника от точек цели и преобразуют его вероятности в веса, избегают явной оценки плотностей, но часто дают некалиброванные оценки риска, потому что оптимизируют точность классификации, а не выравнивание распределений.
Другой путь: прямое сопоставление распределений
Авторы предлагают Kernel Mean Matching (KMM) — метод, обходящий оценку плотностей вообще. Вместо того чтобы пытаться вычислить, насколько вероятна каждая точка при источнике и цели, KMM ищет веса для образцов источника, которые делают их среднюю «подпись» в гибком пространстве признаков, определяемом ядром, похожей на подпись целевых образцов. Интуитивно это растягивает или сжимает влияние каждого исходного образца так, чтобы взвешенное облако источника в целом походило на облако цели. После нахождения таких весов риск оценивают как взвешенное среднее ошибок на источнике. Дополняющий инструмент, локальная корреляционная функция, количественно оценивает, насколько данные скло́нны к кластеризации в пространстве; она служит диагностикой, показывающей, когда сдвиги распределения достаточно сильны, чтобы перенастройка весов могла помочь.
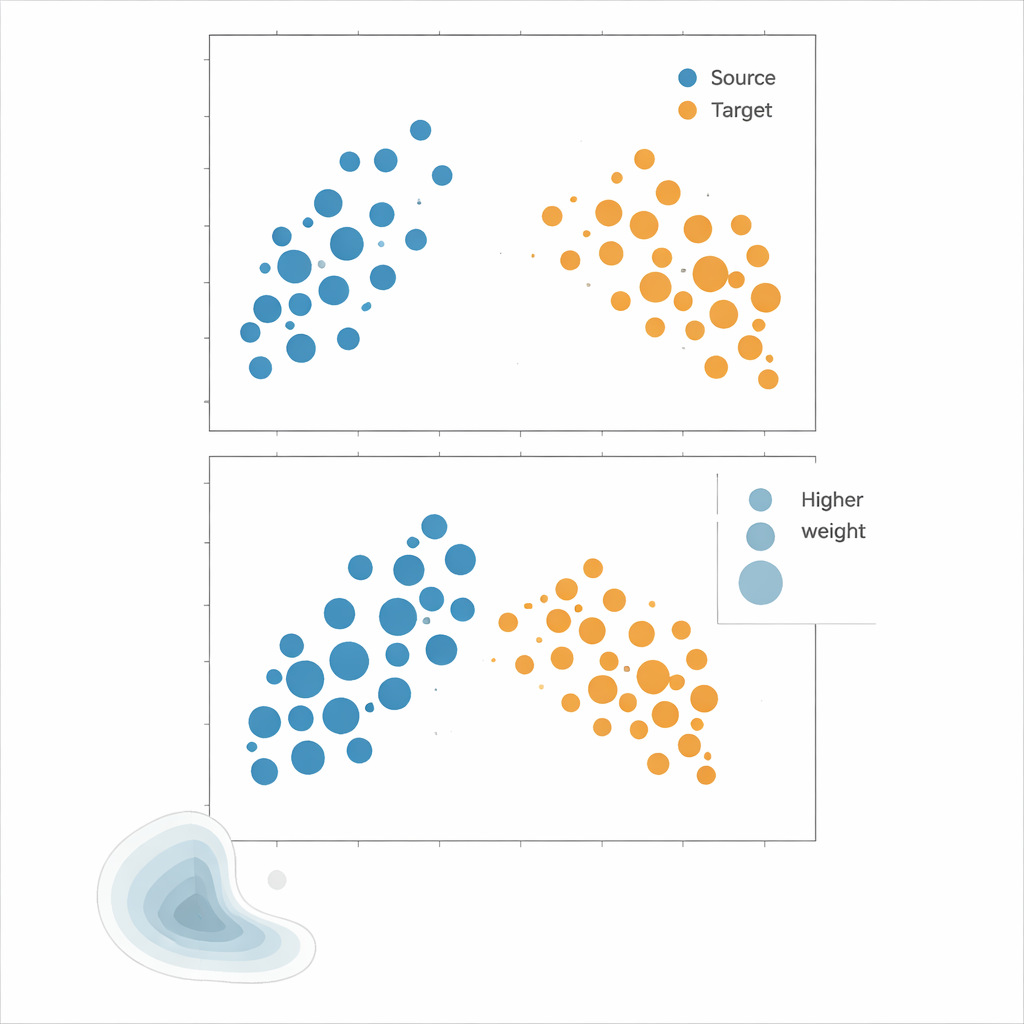
Испытание методов на практике
Чтобы выяснить, какая стратегия работает лучше, авторы проводят обширные эксперименты на синтетических и реальных данных. Синтетические «ландшафты» строятся из смесей гауссовских кластеров с контролируемым разбросом, формой и покрытием области, что даёт возможность проводить структурированные тесты: усечение части домена, изменение корреляций между признаками или переключение между сильно кластерной и почти равномерной схемой точек. Реальные наборы данных включают встречи северных растений, описанные климатом и местоположением, и пространственные расположения иммунных клеток в опухолях. В этих сценариях модели обучаются на кластерных данных источника и оцениваются на менее кластерных данных цели, имитируя типичные смещения выборки. Производительность оценивают по нескольким метрикам ошибки, фокусируясь на том, насколько точно оценённый каждым методом риск отражает истинную ошибку на цели.
Более надёжная оценка риска в шумных высокоразмерных пространствах
Во всех почти синтетических настройках и на реальных данных KMM даёт самые точные и стабильные оценки риска. Он уменьшает среднюю абсолютную процентную ошибку примерно на 12–87 процентов по сравнению с альтернативами и, что важно, избегает «взрыва весов», который преследует importance weighting в высоких измерениях. В сложных раскладках клеток опухолей, например, importance weighting может приводить к ошибкам, превышающим несколько тысяч процентов, тогда как KMM остаётся в управляемых пределах. Перевзвешивание на основе классификаторов обычно улучшает ситуацию по сравнению с наивными методами, но всё же отстаёт от KMM, что отражает его фокус на дискриминации, а не на достоверном выравнивании распределений. Эти результаты показывают, что для пространственных приложений — где данные кластеризованы, смещены и высокоразмерны — KMM предлагает принципиально обоснованный способ оценить, насколько можно доверять предсказаниям модели.
Что это означает для принятия реальных решений
Для неспециалистов, использующих машинное обучение в экологии, прикладной экологии или биомедицине, посыл прост: стандартные тестовые оценки могут вводить в заблуждение, когда область применения отличается от области, из которой пришли данные. Сопоставление средних в ядре даёт способ скорректировать это, перебалансируя влияние обучающих образцов так, чтобы они статистически напоминали места или ткани, которые вам важны. Исследование показывает, что этот подход последовательно даёт более честные оценки ошибки модели, даже при сильном пространственном смещении и большом числе входных переменных. На практике это означает более надёжные рекомендации при выборе между моделями и более ясную картину того, где предсказания заслуживают доверия и где требуется осторожность.
Цитирование: Serov, E., Koldasbayeva, D. & Zaytsev, A. Kernel mean matching enhances risk estimation under spatial distribution shifts. Sci Rep 16, 6921 (2026). https://doi.org/10.1038/s41598-026-36740-7
Ключевые слова: сдвиг распределения, пространственное моделирование, сопоставление средних в ядре, оценка риска модели, экологические и биомедицинские данные