Clear Sky Science · ru
Повышение устойчивости к атакам в семантическом кэше для защищённых систем восстановления с генерацией
Почему умная «память» ИИ важна
По мере того как чат-боты и AI‑помощники проникают в рабочие места, аудитории и даже больницы, они все больше опираются на трюк с «помнением» предыдущих вопросов, чтобы быстрее и дешевле отвечать на похожие запросы. Такая память, называемая семантическим кэшем, может существенно сокращать затраты и задержки — но при этом открывает заднюю дверь для злоумышленников, которые могут заставить систему раскрыть секреты или выдать неверные ответы. В этой статье исследуются скрытые риски и предлагается новая архитектура SAFE-CACHE, призванная сохранить скорость работы «памяти» ИИ и одновременно сделать её гораздо сложнее для злоупотребления.
Как современные помощники повторно используют прошлые ответы
Современные большие языковые модели (LLM) часто работают в схеме, называемой retrieval-augmented generation (RAG). Когда вы задаёте вопрос, система сначала ищет релевантные документы, а затем LLM формирует ответ на их основе. Поскольку многие люди задают по сути одинаковые вопросы, но перефразируя их, компании добавляют семантический кэш: хранилище старых вопросов и ответов и математических отпечатков их смысла. При поступлении нового запроса система проверяет, достаточно ли «близок» его отпечаток к уже имеющемуся в кэше; если да, она просто переиспользует старый ответ, не выполняя весь процесс поиска и генерации заново. Эта идея, реализованная в инструментах вроде GPTCache и облачных платформах Microsoft и Google, экономит деньги и ускоряет ответы в службах поддержки, корпоративных чатах и других высоконагруженных AI‑сервисах. 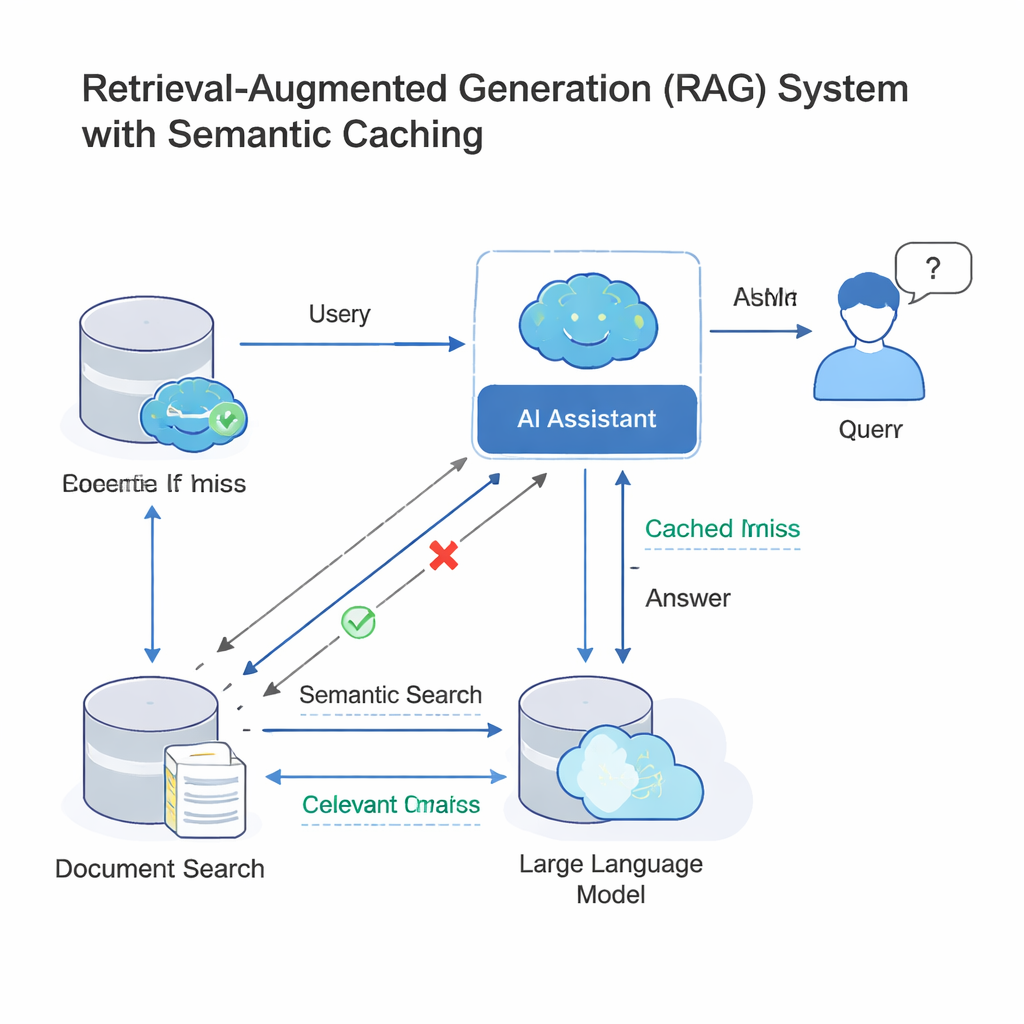
Когда искусная формулировка превращается в брешь безопасности
То же самое упрощение, которое ускоряет работу, может быть обращено против системы. Злоумышленники могут составлять запросы, похожие по структуре, но имеющие иное значение — изменять дату, подставлять другое лицо или место, или переворачивать смысл вопроса. Поскольку современные кэши в основном опираются на числовое сходство эмбеддингов (этих отпечатков смысла), злонамеренный запрос может «столкнуться» с безобидным в векторном пространстве, хотя намерение изменилось. Такое столкновение может привести к возврату кэшем неправильного ответа, потенциально раскрывая конфиденциальную информацию или позволяя сохранить вредные данные для последующего переиспользования. Предыдущие исследования уже показали, что векторные базы данных и семантические кэши можно отравить таким образом, особенно когда многие пользователи разделяют один и тот же кэш в мультиарендных системах.
Преобразование разрозненных вопросов в устойчивые кластеры намерений
Авторы утверждают, что корень проблемы — в рассмотрении каждого запроса по отдельности. Их решение, SAFE-CACHE, группирует прошлые пары «вопрос–ответ» в кластеры, представляющие базовые намерения — например «кто выиграл гонку в 2022 году за сенат штата Аризона?» или «какова цена программного обеспечения Full Self-Driving у Tesla?». Вместо сопоставления новых запросов напрямую с отдельными старыми, SAFE-CACHE сравнивает их с центром, или центроидом, каждого кластера. Для построения этих кластеров система сначала создаёт эмбеддинги полного вопроса вместе с ответом (а не только вопроса), чтобы различия в ответах — например отказ раскрыть чувствительную информацию — также влияли на группировку. Затем используется алгоритм обнаружения сообществ для нахождения естественных кластеров и статистические тесты для пометки шумных групп, которые могут смешивать разные намерения или содержать враждебные записи. Эти подозрительные кластеры очищаются и разделяются с помощью специально обученного би‑энкодера, который научился сближать честные примеры и раздвигать отравленные.
Обучение небольшой модели для укрепления «памяти» ИИ
Некоторые намерения встречаются в реальном трафике лишь несколько раз, из‑за чего их кластеры остаются хрупкими. Чтобы стабилизировать их, SAFE-CACHE использует дообученную лёгкую языковую модель (вариант Gemma‑3 на 1 миллиарде параметров) для генерации парафразов, сохраняющих то же намерение, но изменяющих формулировку. Эти дополнительные примеры делают кластеры плотнее, а их центроиды — надёжнее, без необходимости вручную размечать тысячи вариантов. Во время работы каждый новый запрос превращается в эмбеддинг и сравнивается с этими центроидами. Если его сходство с лучшим центроидом выше тщательно настроенного порога, возвращается сохранённый ответ; в противном случае система переключается на полный RAG‑конвейер и позже решает, как кластеризовать новую пару. В экспериментах с мощными методами атак, основанными на метаморфическом переписывании и GPT‑4.1, SAFE-CACHE снизил успешные попытки отравления примерно на две трети — три четверти по сравнению с архитектурой в стиле GPTCache, при этом сохранив скорость ответа практически без изменений. 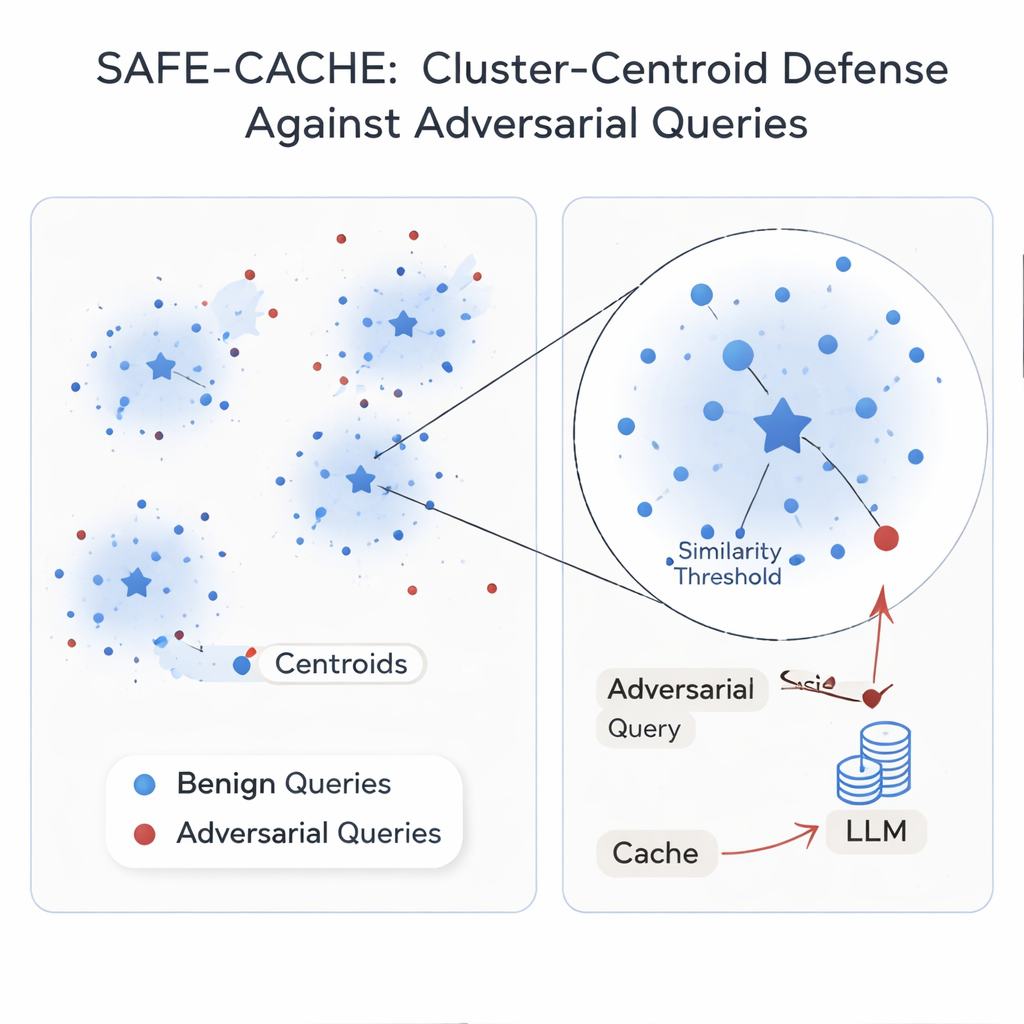
Что это значит для повседневных пользователей AI
Для неспециалистов вывод таков: предоставление «памяти» системам ИИ не даётся даром — наивные решения могут привести к утечке секретов или к тому, что система будет распространять неправильные ответы. SAFE-CACHE демонстрирует, что, организовав «память» вокруг более глубоких, уровня намерений шаблонов и укрепив эти шаблоны целевыми парафразами, можно сохранить преимущества скорости и экономии семантического кэша и одновременно резко снизить риск атак. По мере того как AI‑помощники становятся входной точкой к чувствительным данным — от корпоративных записей до персональной информации — подходы вроде SAFE-CACHE станут ключом к тому, чтобы то, что ИИ помнит, было трудно обратить против нас.
Цитирование: Afiffy, M., Fakhr, M.W. & Maghraby, F.A. Enhancing adversarial resilience in semantic caching for secure retrieval augmented generation systems. Sci Rep 16, 5936 (2026). https://doi.org/10.1038/s41598-026-36721-w
Ключевые слова: семантический кэш, восстановление с расширенной генерацией, враждебные атаки, защита на основе кластеров, безопасность больших языковых моделей