Clear Sky Science · ru
Миграция сервисов в мобильных периферийных вычислениях с учётом задержки и энергопотребления
Почему важно приближать приложения к пользователю
Каждый раз, когда вы играете в онлайн‑игру в машине, транслируете AR‑навигацию на телефон или датчик в умном городе отправляет данные, эти цифровые задачи должны где‑то вычисляться. Мобильные периферийные вычисления (MEC) перемещают эту работу из удалённых центров обработки данных на небольшие серверы рядом с базовыми станциями, уменьшая задержку и делая приложения более отзывчивыми. Но чтобы поддерживать такие сервисы рядом с перемещающимися пользователями, приходится часто «перемещать» (мигрировать) запущенное приложение между близлежащими периферийными серверами. Чрезмерные миграции тратят энергию и деньги; редкие — вызывают задержки и раздражение. В этой работе исследуется, как найти разумный баланс с помощью современных методов машинного обучения.
Баланс между скоростью и потребляемой электроэнергией
Большая часть предыдущих исследований по миграции сервисов в MEC сосредоточивалась главным образом на одной цели: минимизации замечаемой пользователем задержки. Это обычно означает «гоняться» за пользователем по мере его движения и постоянно переносить приложение на ближайший сервер. Однако каждая миграция требует дополнительных коммуникационных ресурсов и добавляет собственную задержку. Многие предыдущие методы также предполагали избыточную вычислительную ёмкость серверов и стабильные условия, игнорируя реальность: периферийные серверы ограничены по ресурсам, конкурируют за множество пользователей и сталкиваются с быстро меняющейся загрузкой и качеством беспроводных каналов. Авторы утверждают, что энергию миграции следует рассматривать как равноправный с задержкой показатель, а политика миграций должна адаптироваться в режиме онлайн к перемещению пользователей, загрузке серверов и колебаниям сети.
От математической задачи к агенту‑обучению
Исследователи сначала строят подробную математическую модель MEC‑системы с несколькими базовыми станциями, соразмещёнными периферийными серверами и мобильными пользователями. Каждый пользователь передаёт вычислительные задачи на близлежащие серверы по беспроводным каналам. Общая задержка сервиса разбивается на три части: время передачи задачи к базовой станции, время её выполнения на сервере и время, затрачиваемое при перемещении сервиса между серверами по магистральной сети. Энергия миграции моделируется преимущественно через объём данных, который нужно передать при перемещении сервиса. Общая цель — минимизировать и задержку, и энергию миграции при соблюдении ограничений на вычислительную ёмкость каждого сервера и сроки выполнения каждого сервиса. Точное решение этой смешанной целочисленной нелинейной задачи в реальном времени вычислительно непрактично, поэтому команда обращается к глубокому усиленному обучению, где агент учится принимать хорошие решения, взаимодействуя с имитируемой средой.
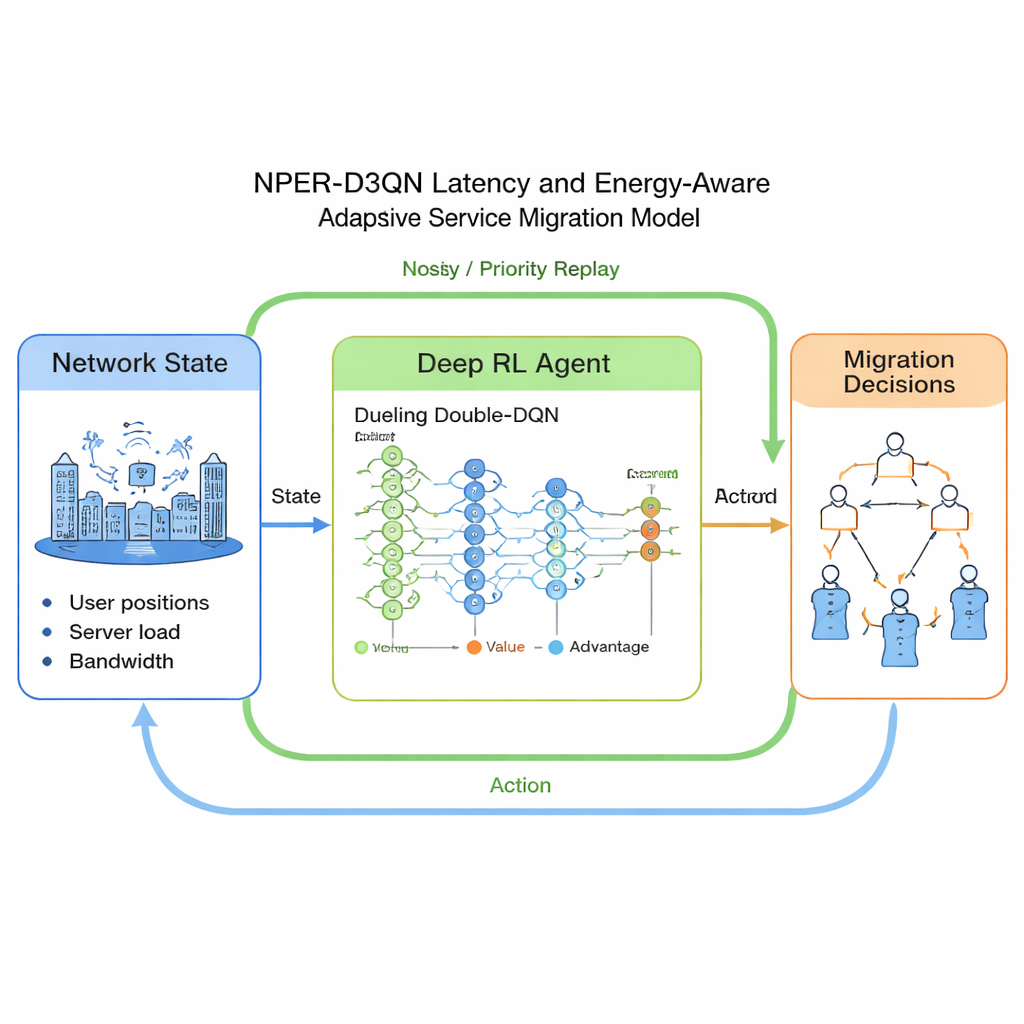
Как работает адаптивный «мозг» миграций
Предложенный метод, названный NPER‑D3QN, представляет собой усовершенствованную разновидность Deep Q‑Networks (DQN). Входное «состояние» агента суммирует местоположение пользователей, расстояние до обслуживающей базовой станции, загрузку каждого периферийного сервера, доступную вычислительную мощность, скорости беспроводной передачи данных и объём и требовательность по вычислениям каждого сервиса. «Действия» — это выбор, какой периферийный сервер будет хостить сервис каждого пользователя в следующем временном слоте. Функция вознаграждения поощряет низкую задержку относительно дедлайна сервиса и штрафует за энергию миграции, заставляя агента искать компромисс между скоростью и потреблением энергии. Технически модель объединяет три идеи: дуэльную сеть, отдельно оценивающую ценность состояния и преимущество каждого действия; «двойную» структуру Q‑обучения, снижающую избыточно оптимистичные оценки; и два механизма для ускорения обучения — шумовые сети и приоритетный реплей опыта, которые помогают быстрее и надёжнее учиться в сложных и меняющихся условиях.
Проверка метода на практике
Чтобы оценить эффективность NPER‑D3QN, авторы моделируют сетку, похожую на город, с десятками базовых станций и до сотен мобильных пользователей, случайным образом перемещающихся и отправляющих задачи разного размера. Периферийные серверы имеют ограниченную вычислительную мощность и могут размещать лишь фиксированное число виртуальных машин, что создаёт реалистичные очереди и конкуренцию за ресурсы. Метод сравнивают с шестью современными базовыми подходами, включая классический DQN, улучшенные double‑dueling варианты и схемы, которые либо всегда перемещаются к ближайшему серверу, либо фокусируются только на минимизации задержки. В разных сценариях NPER‑D3QN сходится к хорошим стратегиям быстрее и последовательно обеспечивает меньшую среднюю задержку сервиса, более низкое энергопотребление, связанное с миграциями, и меньшее число отклонённых миграций при заполненных серверах. В крупном тесте с 720 пользователями и 96 серверами задержку удаётся сократить примерно до двух третей, а энергию миграций — более чем на 90% по сравнению с некоторыми альтернативами, при этом время расчёта решения остаётся в практических пределах.
Что это значит для будущих подключённых сервисов
Для неспециалистов вывод прост: простое приближение приложений к пользователю недостаточно — нужен ещё и интеллектуальный контроль того, когда и куда перемещать запущенные сервисы. Работа показывает, что контроллер на основе обучения может «жонглировать» конкурентными целями отзывчивости, экономии энергии и ограниченной периферийной ёмкости без ручного проектирования правил. Если подобные системы будут внедрены в реальных сетях, они помогут операторам обеспечивать более плавный опыт для приложений вроде автономного вождения, иммерсивной AR и промышленных IoT, одновременно снижая счета за электроэнергию и нагрузку на инфраструктуру. Авторы отмечают, что их исследование выполнено в симуляции и опускает некоторые детали реального мира, такие как полное энергопотребление серверов и несовершенное мониторирование, но оно представляет собой многообещающий шаг к более экологичным и адаптивным периферийным вычислениям.
Цитирование: Li, L., Lv, J., Wang, S. et al. Latency and energy-aware adaptive service migration in mobile edge computing. Sci Rep 16, 6178 (2026). https://doi.org/10.1038/s41598-026-36711-y
Ключевые слова: мобильные периферийные вычисления, миграция сервиса, глубокое усиленное обучение, оптимизация задержки, энергоэффективность