Clear Sky Science · ru
Интеллектуальное распознавание поведения учащихся для интеллектуальных учебных сред
Почему умным классам нужно «видеть», что делают ученики
Во многих классах учителям приходится догадываться, кто внимательно следит за уроком, кто растерялся, а кто тихо отвлечён. В этой статье рассматривается, как искусственный интеллект может автоматически распознавать действия учащихся — например чтение, письмо или поднятую руку — по обычным фотографиям из классов. Преобразуя необработанные изображения в надёжные показатели активности в классе, система призвана предоставить учителям оперативную обратную связь об уровне вовлечённости без длительных наблюдений или навязливого мониторинга.
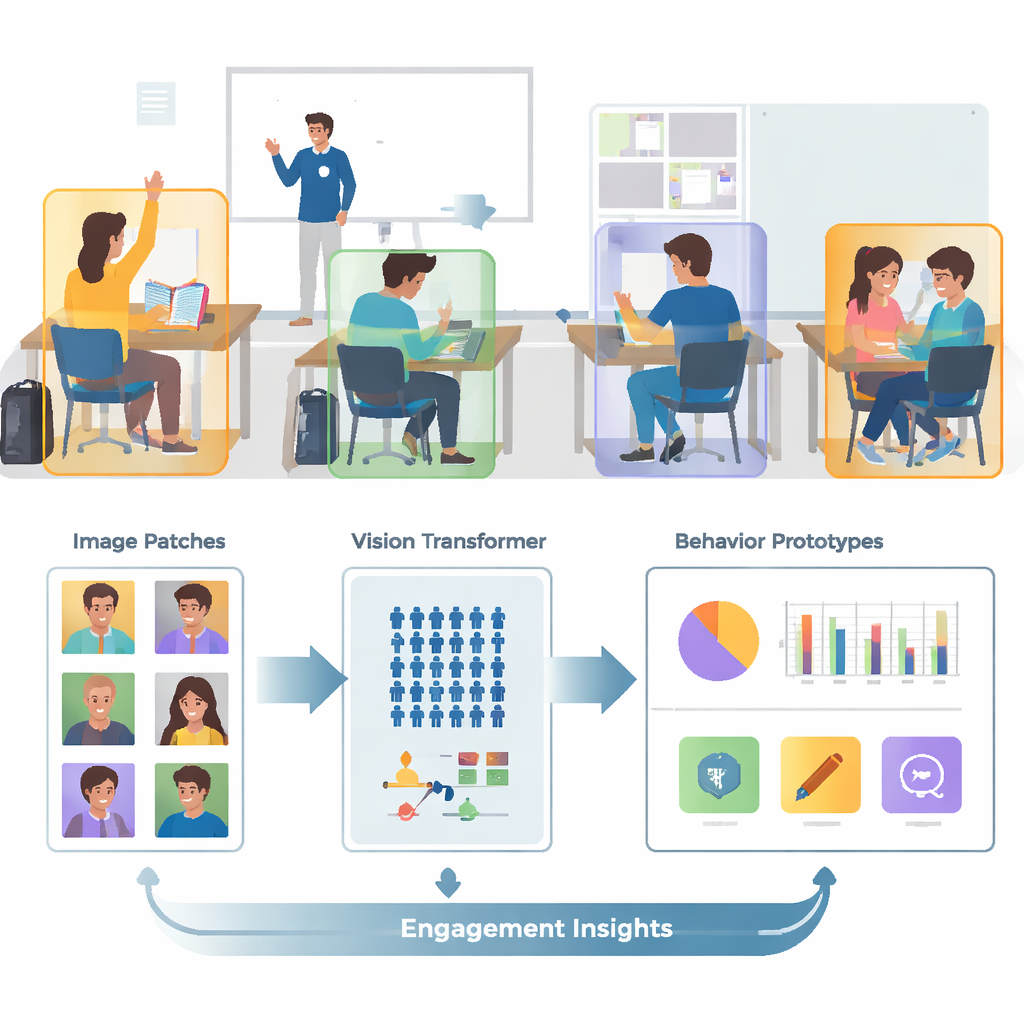
От шумных снимков к сфокусированным кадрам
Реальные классы многолюдны, заняты и визуально запутаны. На одном снимке может быть десятки учеников, перекрывающиеся тела и отвлекающие фоновые детали — стены, экраны и плакаты. Авторы опираются на публичную коллекцию изображений SCB‑05, содержащую тысячи фотографий классов с пометками конкретных действий — таких как поднятие руки, чтение, письмо, стояние, разговор или работа у доски. Вместо того чтобы подавать на вход модели целые сцены, система сначала использует файлы разметки, чтобы вырезать области вокруг каждого ученика или учителя. Этот шаг предобработки устраняет большую часть визуального шума, позволяя модели сосредоточиться на позе, положении рук и других подсказках, отличающих одно поведение от другого.
Как ИИ обучается новым действиям по очень малому числу примеров
Главная проблема в том, что некоторые действия в классе часто встречаются в данных (например, чтение), тогда как другие редки (например, краткие выступления на сцене). Сбор достаточного числа размеченных изображений для каждого возможного поведения дорогостоящ и вызывает вопросы конфиденциальности. Чтобы обойти это, авторы применяют стратегию, называемую «few‑shot обучением», при которой модель учат распознавать новые классы по лишь нескольким примерам. Обучение организовано как множество небольших задач, каждая из которых содержит всего несколько типов поведения и по несколько образцов на тип. Для каждой задачи система формирует простой «прототип» поведения, усредняя внутреннее представление этих примеров. Новые изображения классифицируются по ближайшему прототипу, что позволяет модели быстро адаптироваться даже при скудных данных.
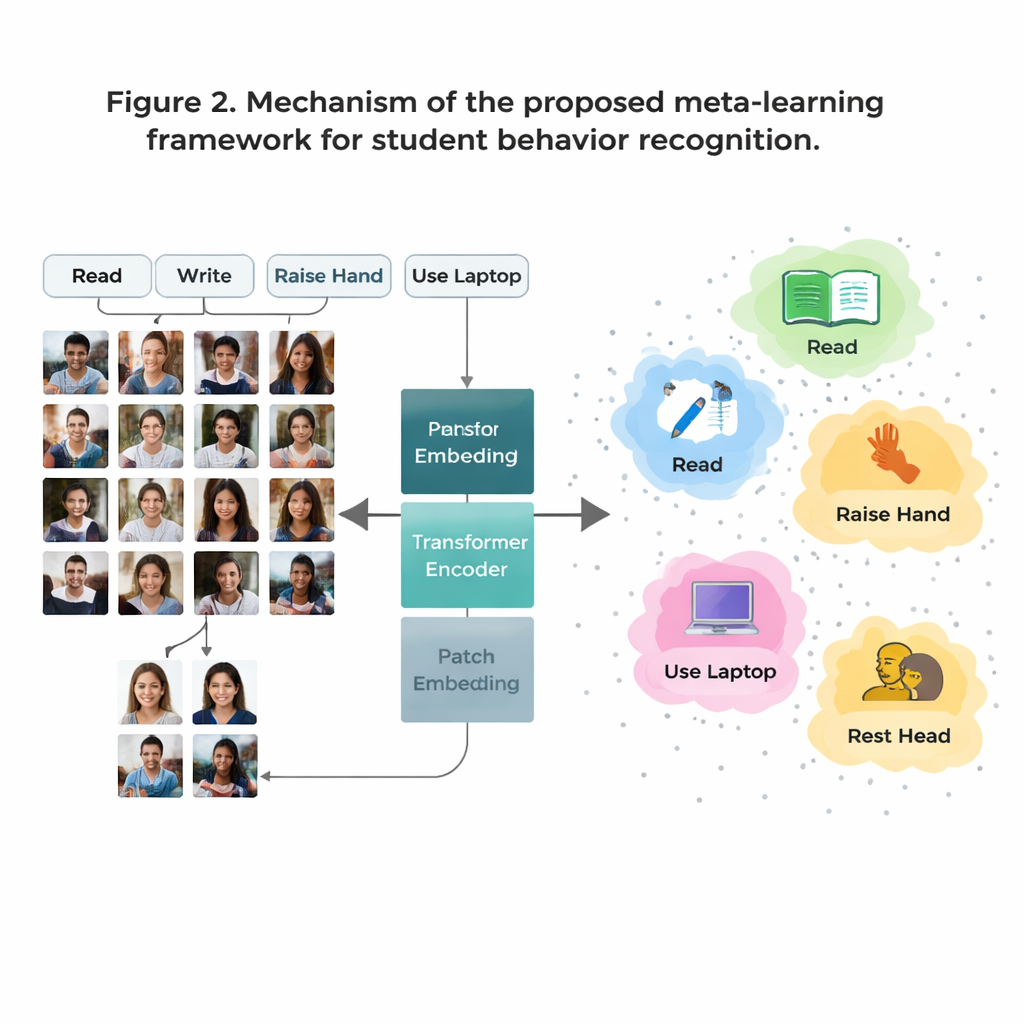
Видеть весь класс, а не только мелкие детали
Традиционные системы обработки изображений, называемые сверточными нейронными сетями, склонны фокусироваться на локальных паттернах — краях или текстурах. Это ограничение становится заметным, когда два поведения, например чтение и письмо, выглядят очень похоже вблизи. В этой работе такие сети заменены Vision Transformer — моделью, которая разбивает изображение на фрагменты (патчи) и учится учитывать взаимосвязи между всеми фрагментами. Такой глобальный взгляд помогает системе улавливать тонкие различия в позах и дальние контексты — например связь между поднятой рукой и учителем у передней части класса. Команда дополнительно улучшает модель, обучая её сближать изображения одного и того же поведения и раздвигать похожие, но разные случаи, с особым акцентом на «трудные» запутанные примеры. Это делает внутреннее представление действий более чистым и легче разделимым.
Насколько это работает и почему это важно
На бенчмарке SCB‑05 предложенный метод достигает примерно 91% общей точности и показывает высокие результаты по более требовательным метрикам, учитывающим несбалансированные данные. Распространённые поведения, такие как чтение и поднятие руки, распознаются особенно хорошо, тогда как более редкие, например письмо на доске, остаются сложнее, но показывают улучшение по сравнению с предыдущими системами. Визуальная проверка внутренних кластеров модели показывает, что разные поведения образуют плотные, хорошо разделённые группы, что свидетельствует о том, что ИИ выучил отличительные «подписи» действий в классе. При тестировании на другом датасете с иными углами камер и планировкой помещений производительность снизилась лишь незначительно, что говорит о том, что полученное представление не привязано к одной комнате или школе.
Что это значит для преподавания и обучения
Проще говоря, исследование показывает, что компьютеры способны надёжно обнаруживать многие ключевые поведения учащихся по статическим изображениям, даже если для каждого из них имеется лишь несколько примеров. Такие системы не призваны заменить учителей; они могут ненавязчиво суммировать, кто вовлечён, кто часто просит помощи или какие активности теряют внимание — и всё это без отслеживания личностей учащихся. При дальнейшем решении вопросов приватности, справедливости и анализа видео во времени подобный поведенчески‑ориентированный ИИ может стать мощным помощником для преподавателей, помогающим проектировать более отзывчивые и инклюзивные образовательные среды.
Цитирование: Abozeid, A., Alrashdi, I. & Al-Makhlasawy, R.M. Intelligent recognition of students’ behavior for smart learning environments. Sci Rep 16, 5674 (2026). https://doi.org/10.1038/s41598-026-36633-9
Ключевые слова: умный класс, поведение учащихся, компьютерное зрение, few-shot обучение, vision transformer