Clear Sky Science · ru
Оптимизация нескольких задач и устойчивость сходимости при иерархическом обучении признаков для самонаправляемой оптимизации
Более умный ИИ, который может одновременно решать множество задач
Современные приложения всё чаще полагаются на искусственный интеллект, которому нужно решать несколько задач одновременно — например, одновременно понимать изображения и текст, поддерживать медицинские решения или помогать автомобилям воспринимать дорогу. Но когда одна модель ИИ пытается освоить слишком много навыков одновременно, обучение может стать неустойчивым, а навыки начинают мешать друг другу. В этой работе предлагается новая архитектура глубокого обучения — Unified Multitask and Multiview Deep Architecture (UMDA) — спроектированная так, чтобы одна модель могла учиться на разных типах данных и решать множество задач без путаницы и потери устойчивости.
Почему многозадачный ИИ сегодня часто испытывает трудности
Большинство современных систем, которые обучаются нескольким задачам (multitask learning) или объединяют несколько типов данных, например изображения и текст (multiview learning), сталкиваются с тремя крупными проблемами. Во‑первых, разные задачи могут конфликтовать в процессе обучения: улучшение по одной задаче невольно вредит другой — это явление называется негативным переносом. Во‑вторых, простое объединение или усреднение информации из разных источников часто теряет тонкие, но важные связи между ними. В‑третьих, сам процесс обучения может стать шатким, с резкими колебаниями направлений обновления параметров модели. Эти проблемы особенно критичны в реальных приложениях, таких как медицинская диагностика или промышленный контроль, где данные сложны, а решения должны быть надёжными.
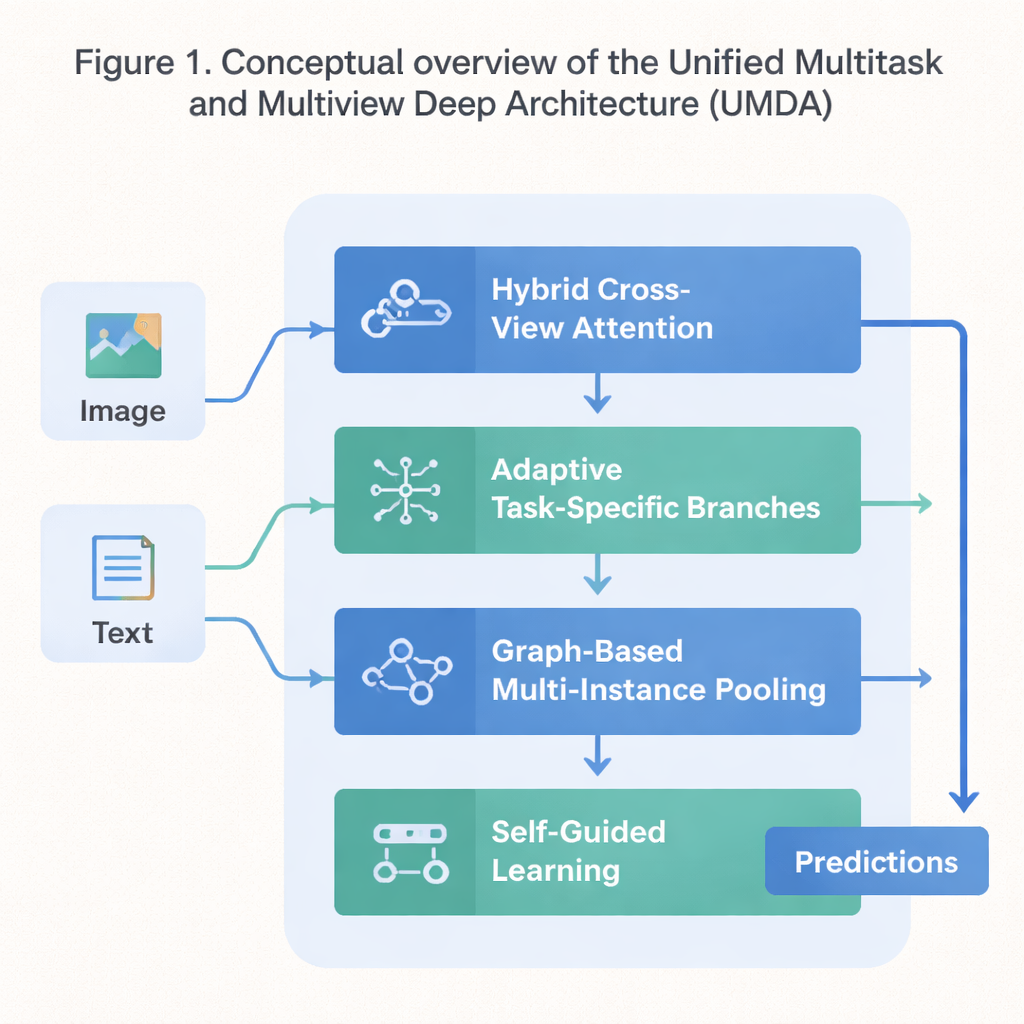
Четырёхступенчатая схема для кооперативного обучения
UMDA устраняет эти слабые стороны, разбивая процесс обучения на четыре тесно связанные части, которые обмениваются информацией контролируемым образом. Первая часть, называемая Hybrid Cross‑View Attention, анализирует разные представления одних и тех же данных — например, текст и изображение, описывающие фильм — и учится определять, какое представление должно влиять на другое на каждом шаге. Она использует математические приёмы, которые побуждают модель не полагаться чрезмерно на одно представление, сохранять различие между представлениями и в то же время поддерживать их общее согласие. Проще говоря, это учит модель прислушиваться ко всем своим «чувствам», не давая одному заглушить остальные.
Сохраняя задачи отдельными, но всё же кооперативными
Вторая часть, Adaptive Task‑Specific Branching, отделяет общие знания, которые разделяют многие задачи, от той специализированной информации, которая необходима каждой задаче в отдельности. Вместо того чтобы заставлять все задачи использовать ровно одинаковые признаки, UMDA строит отдельные «ветви» для каждой задачи, которые при этом могут взаимодействовать через тщательно взвешенные соединения.Дополнительные штрафные члены в целевой функции обучения стимулируют эти ветви быть достаточно различными для специализации, но не настолько разделёнными, чтобы перестать сотрудничать. Этот баланс помогает снизить вредное вмешательство между задачами, сохраняя при этом выгоды от общего обучения.
Видеть структуру в наборах примеров
Многие реальные наборы данных состоят из коллекций связанных объектов — например, нескольких фрагментов изображения с одного медицинского слайда или множества кадров из видео. Третья часть UMDA, называемая Graph‑Based Multi‑Instance Pooling, явно моделирует отношения между такими объектами, рассматривая их как узлы в сети. Она соединяет похожие элементы, позволяет информации течь по этим связям, а затем сводит всю коллекцию в единое компактное представление. Дополнительная регуляризация подталкивает соседние элементы к согласию, сохраняя при этом достаточное разнообразие, что позволяет модели захватывать структурные закономерности, которые простое усреднение упустило бы.
Самонастраиваемое обучение для ровного прогресса
Заключительная часть, Self‑Guided Learning, сосредоточена на процессе обучения модели, а не на её внутренней структуре. Она непрерывно измеряет силу и схожесть сигналов обучения для каждой задачи и автоматически подстраивает скорость обучения для каждой из них. Также она сглаживает и пере‑взвешивает градиенты — сигналы, которые показывают модели, как изменять параметры — так, чтобы задачи с близкими целями усиливали друг друга, а задачи, тянущие в сильно разные стороны, не дестабилизировали обучение. На стандартном наборе данных, сочетающем сюжеты фильмов и постеры, UMDA показала более высокую среднюю точность по сравнению с дюжиной современных конкурентов, лучше сохранила согласованность между представлениями и сократила ключевую меру нестабильности обучения более чем вдвое.
Что это значит для реальных систем ИИ
Для неспециалистов главное послание в том, что UMDA предлагает подход к созданию единой модели ИИ, способной надёжнее работать с несколькими типами данных и целями. Обучая модель тому, когда стоит делиться информацией, а когда — держать знания раздельно, и позволяя ей автоматически настраивать процесс обучения, эта архитектура обеспечивает более точные прогнозы, согласованные внутренние представления и более плавное обучение. Это делает её перспективным элементом для будущих систем в медицине, автономном вождении и других сложных приложениях, где ИИ должен одновременно интерпретировать множество сигналов, не теряя устойчивости.
Цитирование: Mahmood, K., Althobaiti, M.M., Hassan, M.U. et al. Multitask optimization and convergence stability with hierarchical feature learning for self guided optimization. Sci Rep 16, 6414 (2026). https://doi.org/10.1038/s41598-026-36622-y
Ключевые слова: обучение для нескольких задач, мультимодальный ИИ, устойчивость глубокого обучения, сети внимания, графовые нейронные сети