Clear Sky Science · ru
Гибридная модель ResNet50-vision transformer с механизмом внимания для классификации аэрофотоснимков
Почему «умные» глаза в небе важны
Аэрофотоснимки с дронов и спутников сегодня служат ориентиром при реагировании на катастрофы, планировании городов, ведении сельского хозяйства и даже управлении движением. Но научить компьютеры правильно интерпретировать эти сложные, загруженные видом сверху изображения всё ещё непросто. В исследовании представлены две новые модели искусственного интеллекта, которые объединяют разные способы «видения» изображений, чтобы распознавать десять типов объектов на снимках с дронов — например, здания, автомобили, деревья и дороги — с большей точностью, чем предыдущие методы. Их подход может сделать автоматический мониторинг с воздуха более быстрым, надёжным и проще внедряемым в реальных условиях.
Трудности при взгляде сверху
Аэрофотоснимки отличаются от повседневных фотографий, которые мы делаем на телефоны. Объекты на них мельче, могут выглядеть под неожиданными углами и часто расположены в плотных скоплениях. Машину, частично скрытую деревом, узкую тропинку или завалы после оползня бывает трудно заметить даже человеку быстро. Тем не менее правительства, спасательные службы и экологические организации всё чаще полагаются на снимки с дронов и спутников, чтобы отслеживать наводнения, лесные пожары, рост городов и повреждения инфраструктуры. С массивным увеличением числа спутников на орбите и бурно растущим рынком аэрофотосъёмки объём данных растёт слишком быстро, чтобы люди могли просматривать их вручную, что усиливает потребность в более точной и эффективной автоматической классификации.
Смешение двух способов машинного «видения»
Большинство успешных систем распознавания изображений сегодня опираются на глубинное обучение. Одна группа — сверточные нейронные сети — превосходно выделяет локальные паттерны, такие как границы, текстуры и мелкие формы. Другая, более новая — vision transformers — рассматривает изображение как последовательность патчей и особенно хорошо улавливает дальнодействующие связи, например, как дорога, группа крыш и соседнее открытое поле соотносятся в сцене. В этой работе объединены оба подхода: известная сверточная модель ResNet-50 и vision transformer. Каждая из них обрабатывает одно и то же аэрофото и извлекает собственный набор числовых признаков — компактных сводок того, что сеть «поняла» о сцене. Эти два потока информации затем объединяются и передаются в модуль «внимания», который обучается определять, какие признаки наиболее важны при выборе одной из десяти целевых категорий.
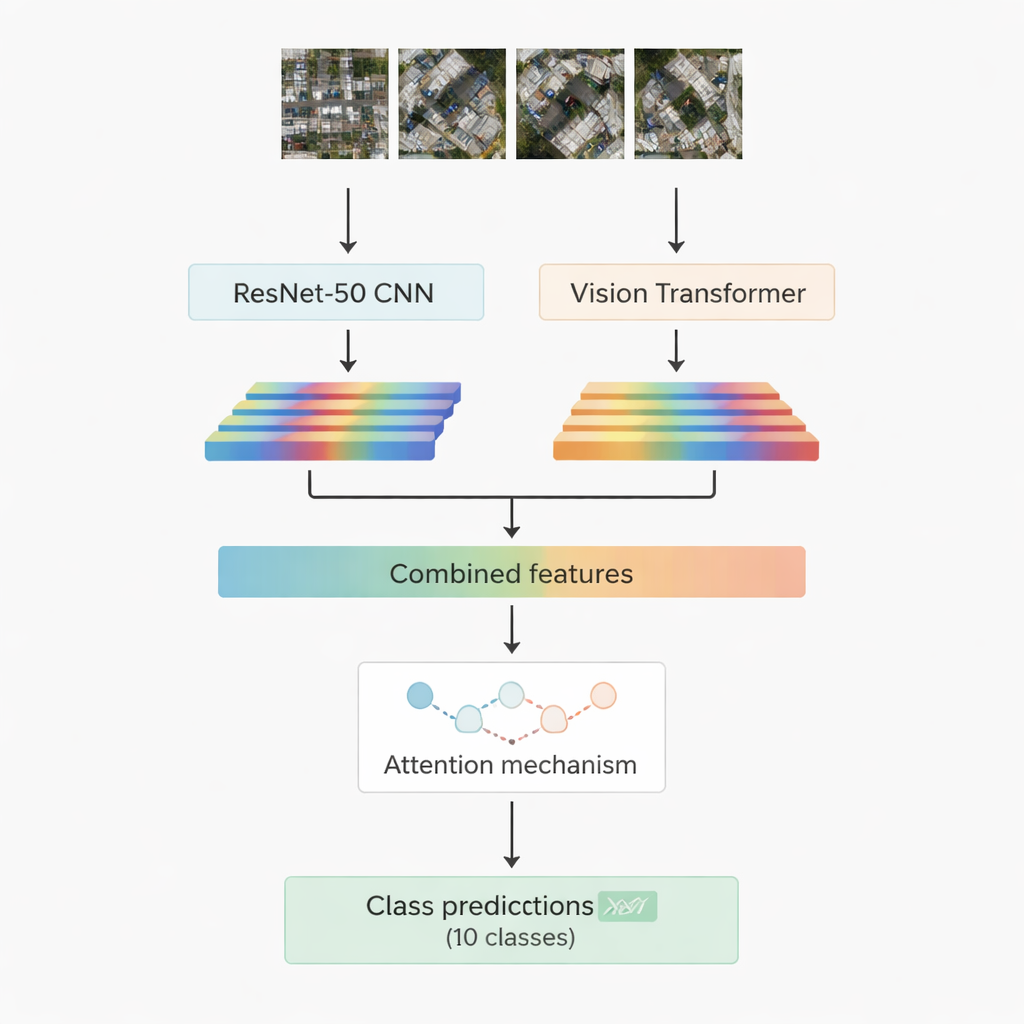
Две стратегии внимания, чтобы сосредоточиться на главном
Исследователи разрабатывают и тестируют две версии гибридной системы. В первой они просто объединяют признаки ResNet-50 и трансформера и подают их в модуль мультоголового внимания. Такой механизм можно представить как множество небольших прожекторов, каждый из которых смотрит на признаки с немного отличного угла, а затем объединяет свои выводы. Во второй версии используется кросс-внимание: признаки сверточной сети выступают в роли запроса, который «спрашивает» признаки трансформера, куда смотреть, позволяя одному потоку направлять другой. В обоих случаях выход внимания проходит через стандартные слои, которые в конце присваивают изображению один из десяти классов, включая здания, автомобили, завалы, тропинки, металлические дороги, открытые поля, тени, танки, деревья и крыши.
Тестирование на реальных снимках с дронов
Чтобы оценить работу моделей, авторы используют публичный набор данных из индийского штата Сикким, собранный дроном, летевшим на высоте 60–120 метров над землёй. Данные охватывают реки, леса, холмы и застроенные территории, нарезанные на маленькие патчи так, чтобы каждое изображение относилось к одной из десяти категорий. Набор данных сбалансирован — одинаковое число обучающих и тестовых изображений для каждого класса, что делает его честной тестовой площадкой. Исследователи обучают обе гибридные модели в одинаковых условиях, а затем сравнивают их по общепринятым метрикам: точности, точности положительных срабатываний (precision), полноте (recall), F1-мере, матрицам ошибок и ROC-кривым. Они также сопоставляют свои результаты с рядом известных сетей и более свежих методов на базе трансформеров из недавней литературы.

Более чёткая классификация и потенциал для практики
Обе гибридные модели превосходят предыдущие системы на этом наборе данных, достигая общей точности 95,52% и 95,80%, причём версия с мультоголовым вниманием немного лидирует. Их показатели остаются высокими и стабильными для всех десяти типов объектов, а детальный анализ показывает, что даже более слабые классы распознаются с хорошими показателями. Это указывает на то, что сочетание сверточных сетей, vision transformers и механизмов внимания — мощный рецепт для понимания сложных аэрофотосцен. Для неспециалиста вывод прост: компьютеры становятся значительно лучше в ответах на вопросы вроде «Где дороги?» или «Какие участки содержат завалы или здания?» в больших коллекциях снимков с дронов. По мере того как такие модели дорабатываются и применяются к новым наборам данных, они могут лечь в основу более умного реагирования на катастрофы, мониторинга окружающей среды и сервисов «умного» города, которые зависят от быстрого и надёжного интерпретирования изображений сверху.
Цитирование: Aboghanem, A., Abd Elfattah, M., M. Amer, H. et al. A hybrid ResNet50-vision transformer model with an attention mechanism for aerial image classification. Sci Rep 16, 5940 (2026). https://doi.org/10.1038/s41598-026-36492-4
Ключевые слова: классификация аэрофотоснимков, съёмка с дронов, глубокое обучение, vision transformer, дистанционное зондирование