Clear Sky Science · ru
Оптимизированный каскадный шифрующийся долговременный сеть с вниманием: анализ производительности адаптивного электронного обучения среди IT‑специалистов
Более умный онлайн‑тренинг для работающих технарей
Для многих специалистов в области информационных технологий (IT) онлайн‑курсы сегодня — основной способ поддерживать навыки в актуальном состоянии. Но большинство платформ для обучения по‑прежнему оценивают людей грубыми методами, такими как суммарные баллы за тесты или бейджи о завершении. В этом исследовании предложен более тонкий способ считывания цифровых «следов», которые оставляют обучающиеся, и превращения их в точные, оперативные выводы о том, насколько каждый человек действительно усваивает материал.
Почему одинаковый подход в онлайн‑курсах не работает
Традиционное электронное обучение обращается с большинством учащихся одинаково: все видят одни и те же модули, проходят одни и те же тесты и оцениваются по одинаковым фиксированным критериям. Такой подход игнорирует, как по‑разному продвигаются специалисты, особенно в быстро меняющихся областях, таких как кибербезопасность или облачные вычисления. Ранее исследования пытались исправить это с помощью машинного обучения — сочетая баллы за тесты, время, проведённое за заданиями, и кликовые данные для прогнозирования успеха — но многие модели испытывали трудности с шумными или неполными данными, не могли масштабироваться до реальных платформ или не отслеживали, как обучение развивается в течение недель и месяцев. В результате получалась часто запоздалая, грубая обратная связь, которая не могла эффективно направлять персонализированный контент или своевременное вмешательство.
Превращая сырые журналы курса в чистые, справедливые данные
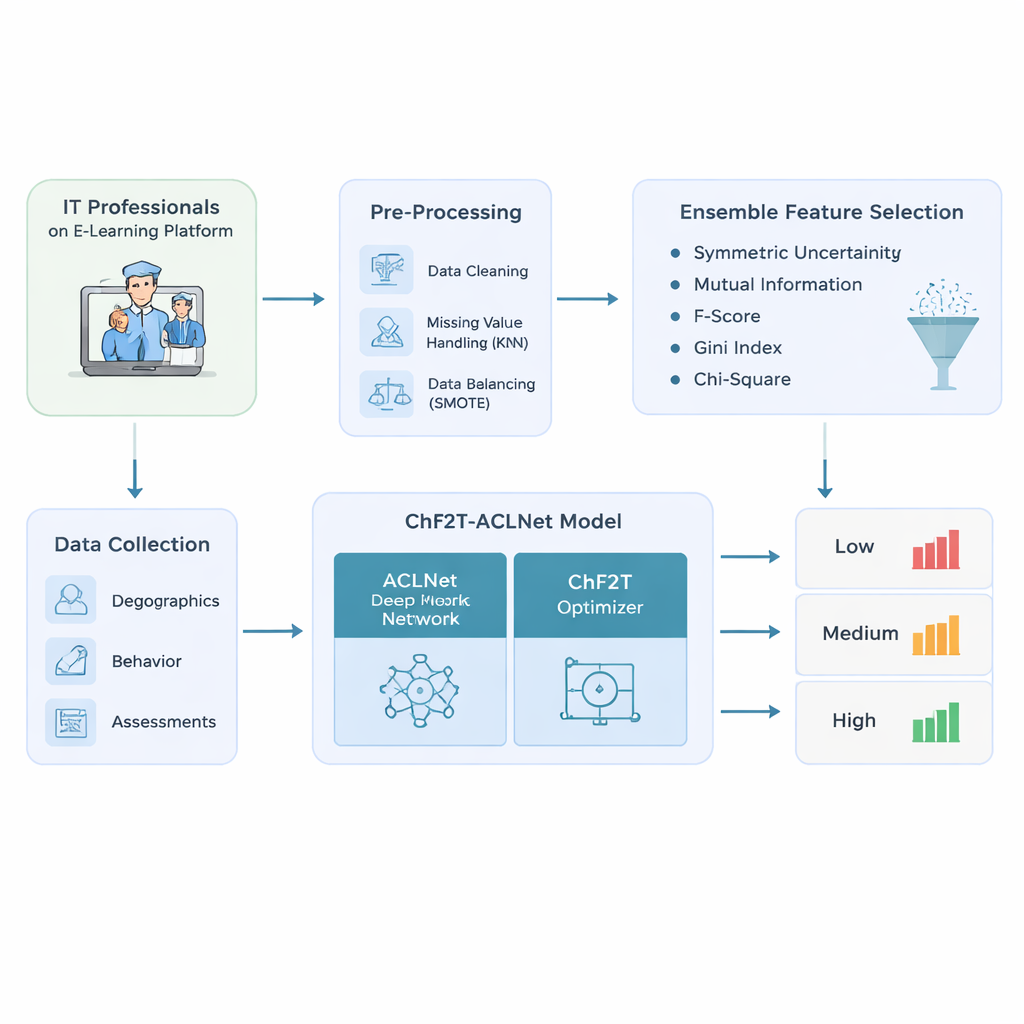
Авторы начинают с разработки тщательного конвейера обработки данных для IT‑специалистов, использующих адаптивные платформы электронного обучения. Они собирают богатый набор информации: базовые профильные данные, такие как возраст и должность; поведенческие следы — время, даты доступа и активные дни; и показатели эффективности — баллы тестов, попытки, сертификаты и оценки обратной связи. До моделирования данные очищают: удаляют дубликаты записей, оценивают пропуски, опираясь на похожих обучающихся, и корректируют искажённое распределение классов так, чтобы низкие, средние и высокие ученики были представлены более равномерно. Этот шаг по уравновешиванию предотвращает ситуации, когда модель слишком уверена лишь для самых типичных «средних» учащихся и слепа к тем, кто испытывает трудности или добивается выдающихся результатов.
Выбор только наиболее значимых сигналов
Из очищенного набора данных система не просто подаёт все доступные столбцы в «чёрный ящик». Вместо этого используется ансамбль из пяти простых методов ранжирования, чтобы определить, какие признаки действительно важны для прогнозирования результатов обучения. Каждый метод анализирует связь между кандидатным признаком — например, количеством попыток в тестах или затраченным временем — и итоговой меткой успеваемости. Объединяя их ранги с помощью медианного показателя, подход отфильтровывает шумные или избыточные сигналы и сохраняет только самые информативные. Это не только сокращает объём вычислений для последующей модели, но и помогает ей сосредоточиться на закономерностях, которые действительно отличают низких, средних и высоких учащихся.
Гибридная сеть, обучаемая как спортивная команда
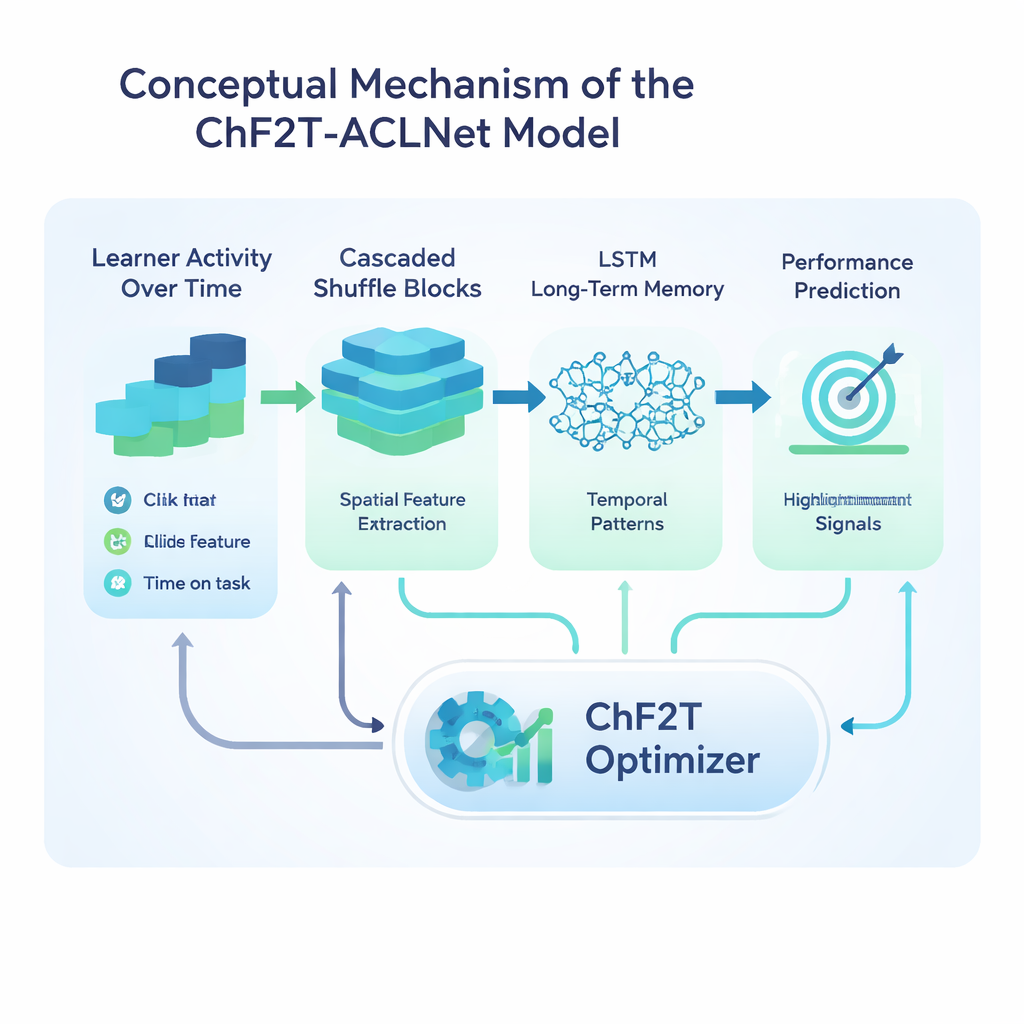
Суть исследования — гибридная модель глубокого обучения под названием ACLNet, сопровождаемая нетрадиционной стратегией обучения, вдохновлённой командными видами спорта. Сначала ACLNet использует лёгкие «shuffle»‑блоки для эффективной компрессии и перемешивания входных сигналов, затем передаёт их в модуль памяти, который отслеживает, как поведение обучающегося меняется со временем. Слой внимания сверху выделяет наиболее влиятельные каналы — например резкие падения активности или постоянно высокие баллы — прежде чем сделать окончательный прогноз класса успеваемости. Чтобы настроить многочисленные внутренние параметры сети, авторы вводят алгоритм Chaotic Football Team Training (ChF2T). Здесь виртуальные «игроки» исследуют разные настройки параметров, подражают сильным исполнителям, избегают слабых и иногда совершают большие хаотичные скачки, помогающие выйти из плохих локальных решений. Такое сочетание структуры и контролируемой случайности ускоряет сходимость и снижает переобучение.
Насколько хорошо система работает на практике
Исследователи тестируют свой конвейер на синтетическом, но реалистичном наборе данных из 1200 IT‑специалистов, созданном так, чтобы отражать записи систем управления обучением с преднамеренно неравномерным распределением классов. Они сравнивают свою модель ChF2T‑ACLNet с несколькими сильными базовыми подходами, включая решения на основе федеративного обучения, продвинутые нейросети, адаптированные под образовательную задачу, и другие глубокие или ансамблевые модели. В разных схемах кросс‑валидации предложенный метод достигает примерно 98,9% точности, с сопоставимо высокими показателями точности (precision), полноты (recall) и F‑меры. Он также показывает почти идеальную скорректированную согласованность, учитывающую случайность, и высокие значения площади под кривой, что означает надёжное разделение уровней успеваемости при различных порогах. Несмотря на сложность, система работает быстрее конкурентов благодаря тщательной отборке признаков, эффективной архитектуре сети и быстрой сходимости оптимизатора.
Что это значит для повседневного онлайн‑обучения
Простыми словами, эта работа показывает, что можно наблюдать за тем, как специалисты продвигаются по онлайн‑курсам, и с высокой уверенностью выявлять, кто испытывает трудности, кто идет легко, а кто усваивает материал — не дожидаясь итогового экзамена. Такая система могла бы запускать ранние подсказки, рекомендовать другие упражнения или оповещать наставников задолго до того, как обучающийся окажется в отставании. Авторы отмечают оставшиеся вызовы, включая масштабирование до очень крупных платформ, адаптацию к быстро меняющимся дизайнам курсов и повышение объяснимости решений модели. Тем не менее, их подход — весомый шаг в сторону систем электронного обучения, которые ведут себя скорее как внимательные персональные тренеры, а не как статичные цифровые учебники.
Цитирование: Yuvapriya, P., Subramanian, P. & Surendran, R. Optimized attention-based cascaded shuffle long-term dependent network based performance analysis of adaptive e-learning among IT professionals. Sci Rep 16, 6245 (2026). https://doi.org/10.1038/s41598-026-36470-w
Ключевые слова: адаптивное электронное обучение, аналитика обучения, глубокое обучение, обучение IT‑специалистов, прогнозирование успеваемости студентов