Clear Sky Science · ru
Чувствительная к конфиденциальности сегментация тромбоза глубоких вен с использованием многомодельной федеративной обучающей рамки и алгоритма федеративного усреднения
Почему важны тромбы в крови и защита данных
Тромбы, образующиеся глубоко в венах ног и известные как тромбоз глубоких вен (ТГВ), могут бесшумно попасть в легкие и вызвать угрозу для жизни. КТ‑снимки могут выявлять эти тромбы, но превратить тысячи оттенков серого в надежные автоматические обнаружения — сложная задача для компьютеров. В то же время больницы вправе с осторожностью относиться к передаче чувствительных данных пациентов. В этом исследовании изучается, как несколько медицинских учреждений могут объединиться для обучения мощной системы искусственного интеллекта (ИИ) по обнаружению тромбов — не объединяя и не раскрывая при этом исходные снимки пациентов.
Обмен мозгами, а не телами
В основе работы лежит техника, называемая федеративным обучением, которая позволяет нескольким учреждениям совместно обучать модели ИИ, сохраняя данные на местах. Вместо отправки КТ‑изображений на центральный сервер каждая больница обучает локальную модель на своих собственных снимках. На центральный сервер передаются лишь параметры модели — по сути то, что она «выучила» о распознавании тромбов. Там подход федеративного усреднения комбинирует разные наборы параметров в одну, улучшенную глобальную модель, которая затем рассылается обратно всем участникам. Таким образом каждое учреждение выигрывает от коллективного опыта, при этом ни одно изображение пациента не покидает исходную организацию. 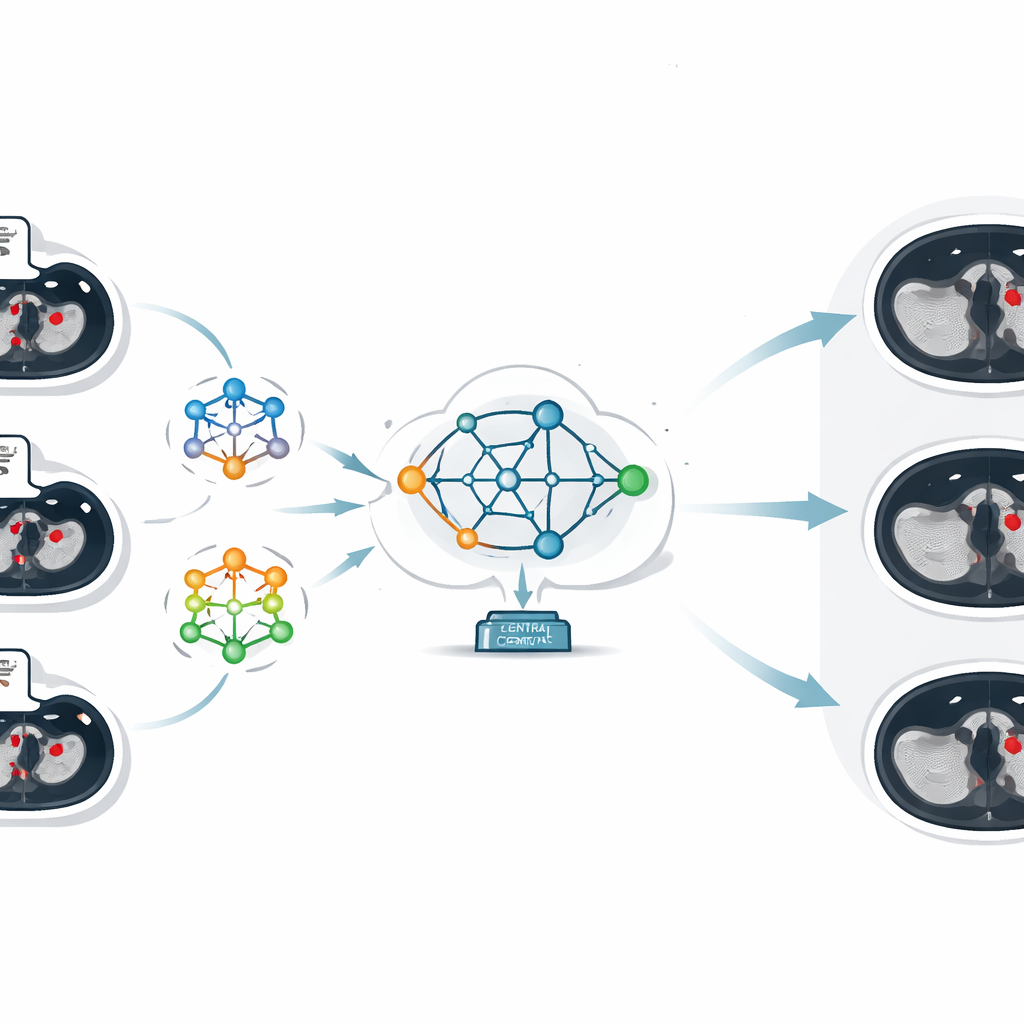
Множество типов ИИ смотрят на одни и те же вены
Ключевое новшество исследования — отказ от опоры на единую архитектуру нейронной сети. Авторы собрали семь разных конструкций моделей, каждая из которых хорошо улавливает разные аспекты КТ‑изображений. Более простые модели, такие как базовые сверточные сети и последовательные модели, работают быстрее и легче запускаются на ограниченном оборудовании. Более продвинутые архитектуры, включая U‑Net, VGG‑19 и две кастомные сети с остаточными (residual), inception, attention и многомасштабными блоками обработки, лучше прослеживают тонкие границы сосудов, обнаруживают мелкие тромбы и справляются с зашумленными изображениями. Позволяя каждой больнице использовать модель, наиболее соответствующую её данным и вычислительным ресурсам, система отражает реальную, разнородную клиническую среду, вместо предположения, что все сайты одинаковы.
Обучение на неравномерных и несовершенных данных
В медицине данные из одной больницы редко полностью совпадают с данными другой. Сканеры, протоколы визуализации и популяции пациентов различаются, поэтому в исследовании сознательно работали с «non‑IID» данными — наборами, которые неравномерны и не идентично распределены. Обычно это делает обучение менее стабильным. Здесь авторы приняли это разнообразие и показали, что объединение знаний через несколько моделей с разной структурой фактически улучшает способность глобальной системы к обобщению. Они провели три экспериментальные фазы: сначала с тремя клиентами, затем с пятью и, наконец, с семью, используя датасеты из 1 000, 2 000 и 3 000 КТ‑изображений. На каждом этапе они отслеживали не только частоту правильной сегментации тромбов глобальной моделью, но и объем необходимой коммуникации, длительность обучения, степень различия данных каждого клиента и эффективность защиты приватности.
Лучшее обнаружение тромбов — ценой вычислительных затрат
Во всех фазах комбинированная глобальная модель постоянно превосходила любую отдельную локальную модель. По мере увеличения числа изображений и присоединения более сложных моделей точность сегментации выросла примерно с 91% до более чем 96%, а сбалансированная мера качества F1‑score — с примерно 0,89 до 0,95. Одновременно ошибка (loss), ориентированная на погрешности, снизилась более чем вдвое, что указывает на более чистые и надежные контуры тромбов. Эти улучшения не были бесплатными: объем обмена между клиентами и сервером вырос от нескольких десятков мегабайт до нескольких гигабайт, а среднее время обучения увеличилось от секунд до многих часов по мере усложнения архитектуры. Тем не менее система сохранила сильную формальную гарантию приватности, показывающую, что разделяемые обновления просачивают очень мало информации о конкретном пациенте. 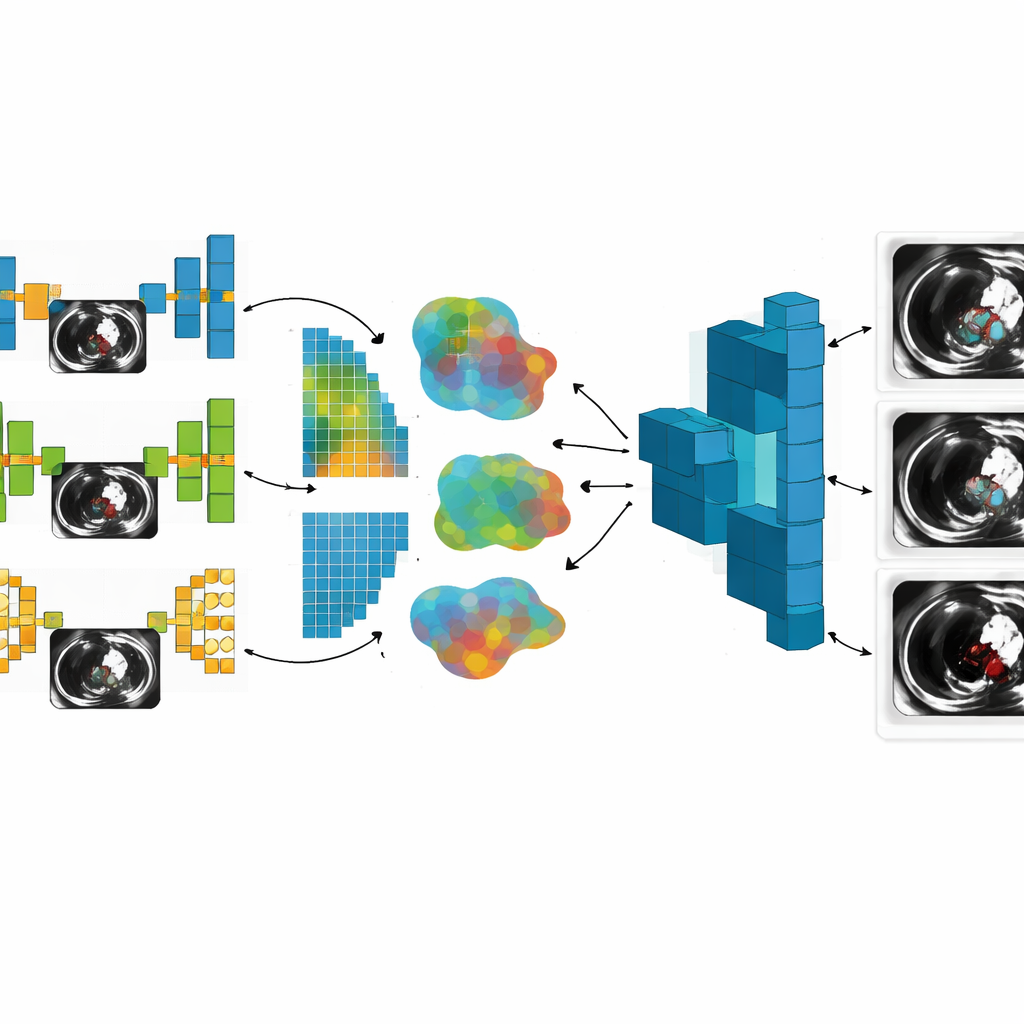
Что это значит для пациентов и больниц
Для непрофессионала итог прост: работа демонстрирует, как больницы могут совместно обучить общий ИИ для более точного обнаружения опасных тромбов, не отдавая контроль над своими чувствительными данными. Смешивая несколько дополняющих друг друга архитектур и аккуратно агрегируя то, чему каждая из них научилась, авторы создают систему сегментации тромбов, которая одновременно мощная и внимательная к приватности. Хотя подход требует существенных вычислительных ресурсов и пропускной способности сети, он указывает на будущее, в котором медицинские центры регулярно сотрудничают над созданием более умных диагностических инструментов, улучшая уход за пациентами с риском ТГВ и сопутствующих состояний, при этом сохраняя их личные снимки в стенах учреждений.
Цитирование: B, P.L., S, V. Privacy-aware deep vein thrombosis segmentation using a multi-model federated learning framework with the federated averaging algorithm. Sci Rep 16, 11333 (2026). https://doi.org/10.1038/s41598-026-36432-2
Ключевые слова: тромбоз глубоких вен, федеративное обучение, сегментация медицинских изображений, защита конфиденциальности ИИ, КТ‑визуализация