Clear Sky Science · ru
Метод разрешения неоднозначных сущностей в коротких текстах на основе модели BERT и алгоритма кратчайшего пути
Почему важно распутывать запутанные имена
Каждый день мы ищем, листаем и общаемся, используя короткие, зачастую неаккуратные фрагменты текста — твиты, поисковые запросы, чат‑сообщения. В этих фрагментах встречаются имена людей, мест, компаний и вещей, которые могут иметь более одного значения, например «Apple» — фрукт или «Apple» — компания. Компьютерам приходится угадывать, какое значение мы имели в виду, и когда они ошибаются, результаты поиска, рекомендации и онлайн‑сервисы теряют полезность. В этой статье предложен новый подход, помогающий машинам правильно интерпретировать такие неоднозначные имена в коротких текстах, особенно в китайских социальных сетях и поисковых запросах, сочетая современные языковые модели с эффективным графовым алгоритмом.
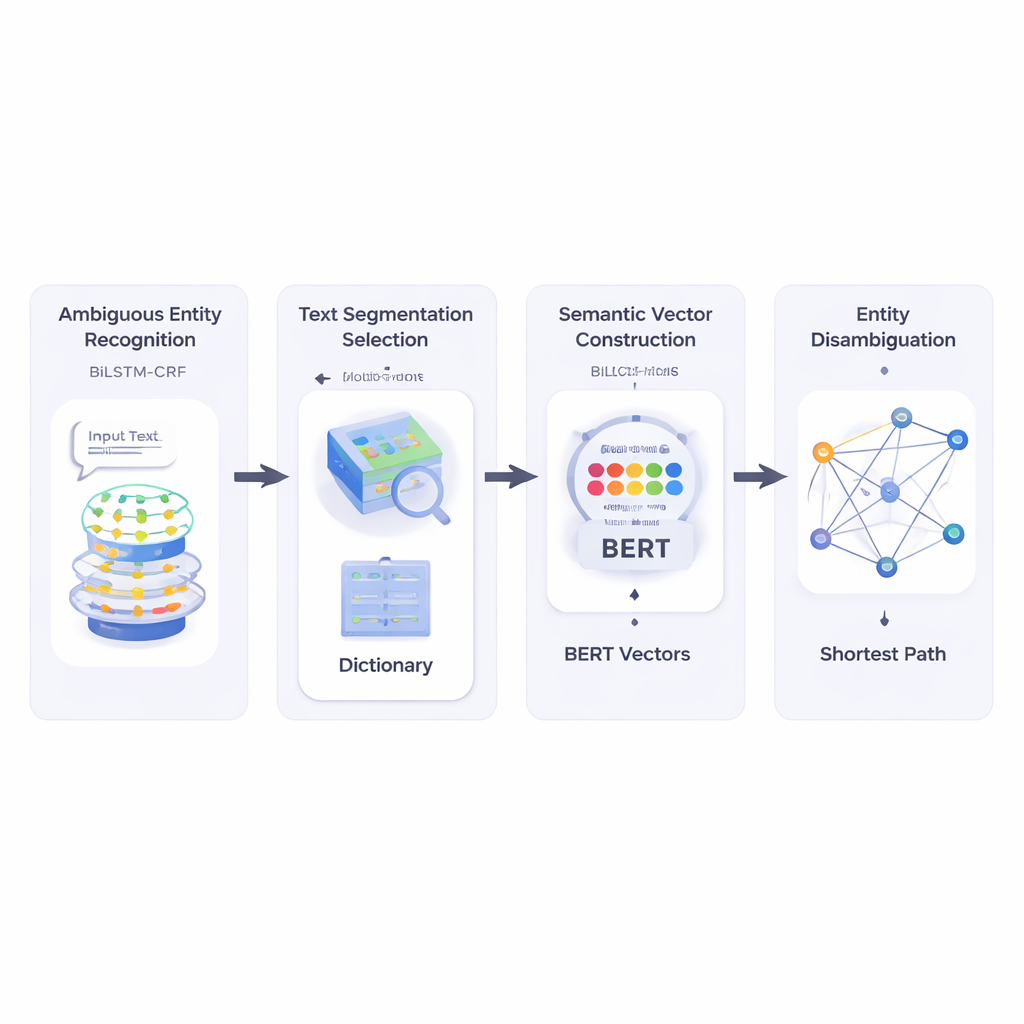
От неуклюжих коротких текстов к понятным целям
Короткие тексты неожиданно сложны для машин. В отличие от длинных статей, они содержат очень мало контекста и полны жаргона, сокращений и неполных предложений. Традиционные методы пытались сопоставить имя в тексте с записями в базе знаний или использовали вручную составленные правила и более простые модели машинного обучения. Эти подходы часто трактуют каждое слово как имеющее одно фиксированное значение, что плохо работает, когда то же слово может означать должность, компанию или песню в зависимости от употребления. В результате часто возникает путаница, к какому реальному объекту относится слово в твите или запросе.
Обучение системы распознавать неоднозначные имена
Авторы сначала строят систему, которая читает короткий текст и определяет, какие фрагменты являются именами сущностей и какие из них могут быть неоднозначными. Они используют комбинацию нейросетей BiLSTM‑CRF, хорошо подходящую для разметки последовательностей, так как учитывает контекст слева и справа. После того как потенциальные сущности отмечены, система обращается к большому лексическому ресурсу HowNet. Если HowNet перечисляет несколько значений для слова, это слово помечается как неоднозначное; если указано только одно значение, слово считается однозначным. Этот шаг даёт системе сфокусированный список имен, которые действительно требуют разрешения неоднозначности.
Преобразование значений в точки в пространстве
Далее метод разбивает короткий текст на кандидаты‑сегменты слов и выбирает лучшее разбиение, проверяя, насколько каждое возможное разрезание согласуется по смыслу с однозначно понятыми эталонными словами в том же предложении. Для этой оценки авторы полагаются на BERT — мощную предварительно обученную языковую модель, которая для каждого употребления слова формирует числовой «семантический вектор», фиксирующий значение в контексте. Вычисляя косинусную схожесть между этими векторами, система находит сегментацию, чьи части наиболее семантически совместимы с однозначными опорными терминами. Это позволяет модели представлять каждое возможное значение каждого слова как точку в многомерном пространстве.
Поиск кратчайшего пути к правильному значению
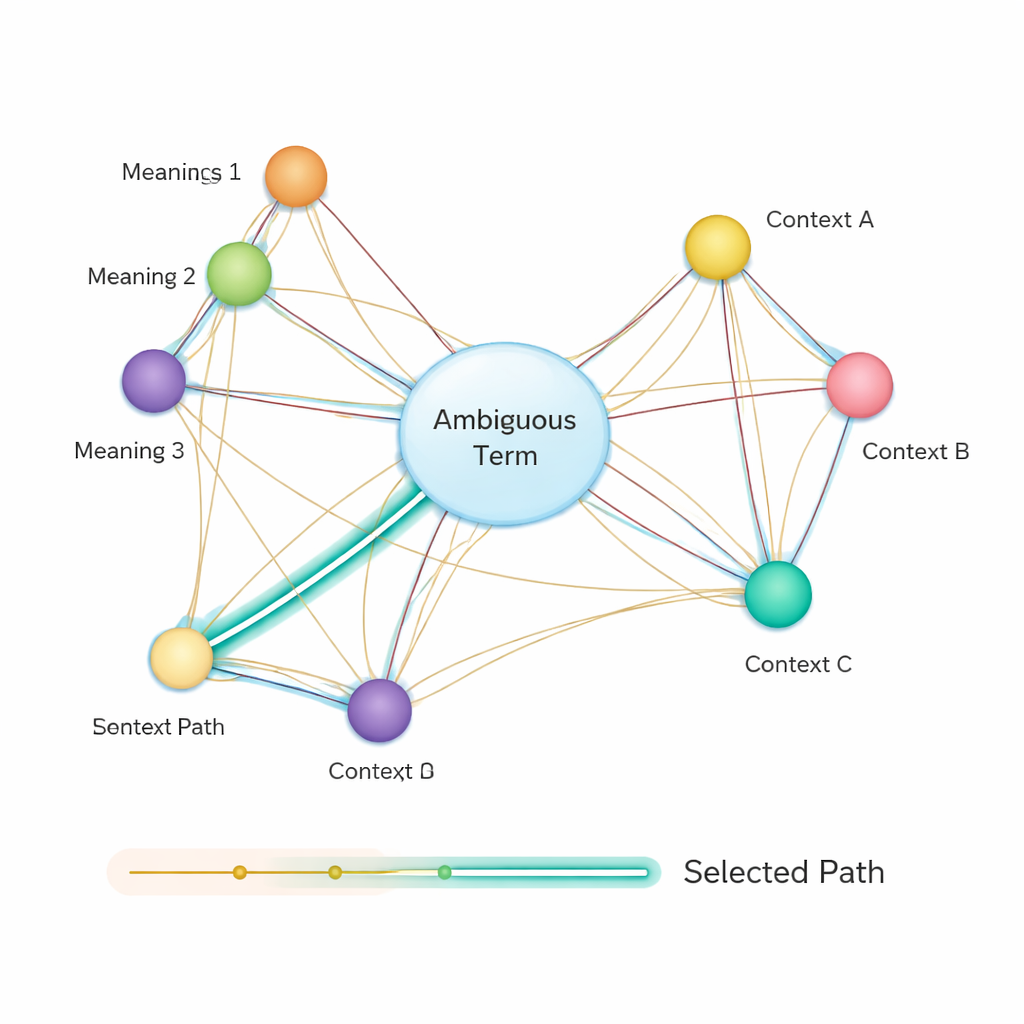
После этого метод строит семантическую сеть: граф, где каждая возможная трактовка каждого термина — это узел, а ребра соединяют значения, которые могут сосуществовать в одном предложении. Вес каждого ребра основан на степени схожести значений, снова вычисляемой с помощью векторов на базе BERT. Чтобы определить, какое значение неоднозначного слова лучше всего вписывается в предложение, авторы применяют классический алгоритм Дейкстры для поиска кратчайшего пути. Интуитивно система ищет путь по этому графу значений, который минимизирует суммарное семантическое «расстояние». Выбранный путь соответствует согласованной интерпретации всех терминов, а значение неоднозначной сущности, лежащее на этом пути, выбирается как окончательный ответ.
Насколько это лучше работает?
Исследователи протестировали свой метод на публичном китайском датасете из бенчмарка CLUE, имитирующем реальные сценарии коротких текстов, такие как посты в соцсетях и запросы. Они сравнили четыре подхода: версии с традиционными эмбеддингами Word2Vec, с языковой моделью ELMo, систему на базе BERT без шага кратчайшего пути и их полный конвейер BiLSTM‑CRF‑BERT‑SPA. На тысячах текстов их полный метод улучшил точность, полноту и F1‑меру примерно на одну четверть в среднем по сравнению с остальными. На практике система лучше определяла правильные сущности и делала это более последовательно при разных объёмах данных.
Что это значит для повседневных технологий
Для неспециалистов вывод простой: сочетая мощную модель понимания языка (BERT) с поиском кратчайшего пути в графе, авторы дают компьютерам более надёжный способ выяснить, на какую реальную сущность ссылается неоднозначное имя в коротких, шумных текстах. Это может сделать поисковые системы умнее, помочь платформам социальных сетей лучше понимать посты и улучшить такие инструменты, как рекомендательные системы и графы знаний. Хотя метод сейчас ориентирован на китайский язык и всё ещё требует оптимизации по эффективности, он демонстрирует, как сочетание современных ИИ‑технологий с классическими алгоритмами может значительно сократить путаницу в том, как машины интерпретируют наш повседневный язык.
Цитирование: Liu, X., Zhang, D., Xiao, T. et al. A short text entity disambiguation method based on BERT model and shortest path algorithm. Sci Rep 16, 5720 (2026). https://doi.org/10.1038/s41598-026-36411-7
Ключевые слова: разрешение сущностей, короткий текст, BERT, граф знаний, обработка естественного языка