Clear Sky Science · ru
Разделение содержания и стиля для многостилевой генерации изображений с использованием архитектуры латентной диффузии
Почему более «умные» стили изображений имеют значение
От киноафиш и игрового арта до фильтров в социальных сетях — мы всё чаще ожидаем, что изображения будут одновременно впечатляющими и персонализированными. Но за кулисами многие системы переноса стиля по-прежнему испытывают трудности: они могут искажать лицо человека, деформировать здания или требовать серьёзного аппаратного обеспечения. В этой статье представлен новый ИИ-модуль, обещающий более богатые художественные стили при сохранении исходной картины и достаточной эффективности для повседневных устройств.
Отделение «что это» от «как это выглядит»
В основе работы лежит модель под названием Dual-Condition Lightweight Style Diffusion Model (DCLSDM). Её ключевая идея — рассматривать содержание изображения — объекты, композицию и сцену — как один «канал», а художественную обработку — цвета, текстуры, мазки — как другой, управляя ими отдельно. Вместо того чтобы позволять одной сети смешивать эти два аспекта, DCLSDM использует два выделенных пути: один для содержания, другой — для стиля. Путь содержания сосредоточен на понимании форм и смысла в исходном изображении или текстовом описании, тогда как путь стиля изучает визуальный характер выбранного произведения или описания стиля.
Как устроена новая модель
DCLSDM опирается на диффузионные модели — ту же семью методов, что стоит за многими современными генераторами изображений. Вместо работы с полноразмерными картинками напрямую, она функционирует в сжатом «латентном» пространстве, что значительно эффективнее. Модуль под названием Perceiver IO извлекает содержание: он принимает изображение или подпись и сводит геометрию и семантику сцены в компактное представление. Отдельный модуль стиля читает одно или несколько изображения стиля или тексты и превращает их в векторы признаков стиля. Эти признаки стиля можно смешивать с помощью схемы взвешенной интерполяции, позволяя плавно переходить, например, между импрессионизмом и минимализмом без обычного «грязного» усреднения.
Сохранение структуры при смене стиля
Внутри диффузионной сети, которая фактически генерирует изображение, два типа информации вводятся через независимые маршруты. Сигналы содержания направляют слои сети, отвечающие за структуру — где должны располагаться контуры, объекты и компоновка. Сигналы стиля подаются через выделенные слои внимания, которые формируют в основном текстуры, цвета и манеру мазка. Сверху компонент под названием ControlNet добавляет дополнительное структурное руководство с помощью карт краёв или глубины, извлечённых из исходного содержания. Такое сочетание позволяет перерисовать летний пейзаж в зимней палитре или отдать фото в стиле Ван Гога, сохранив при этом горы, деревья и здания на нужных местах без искажений.
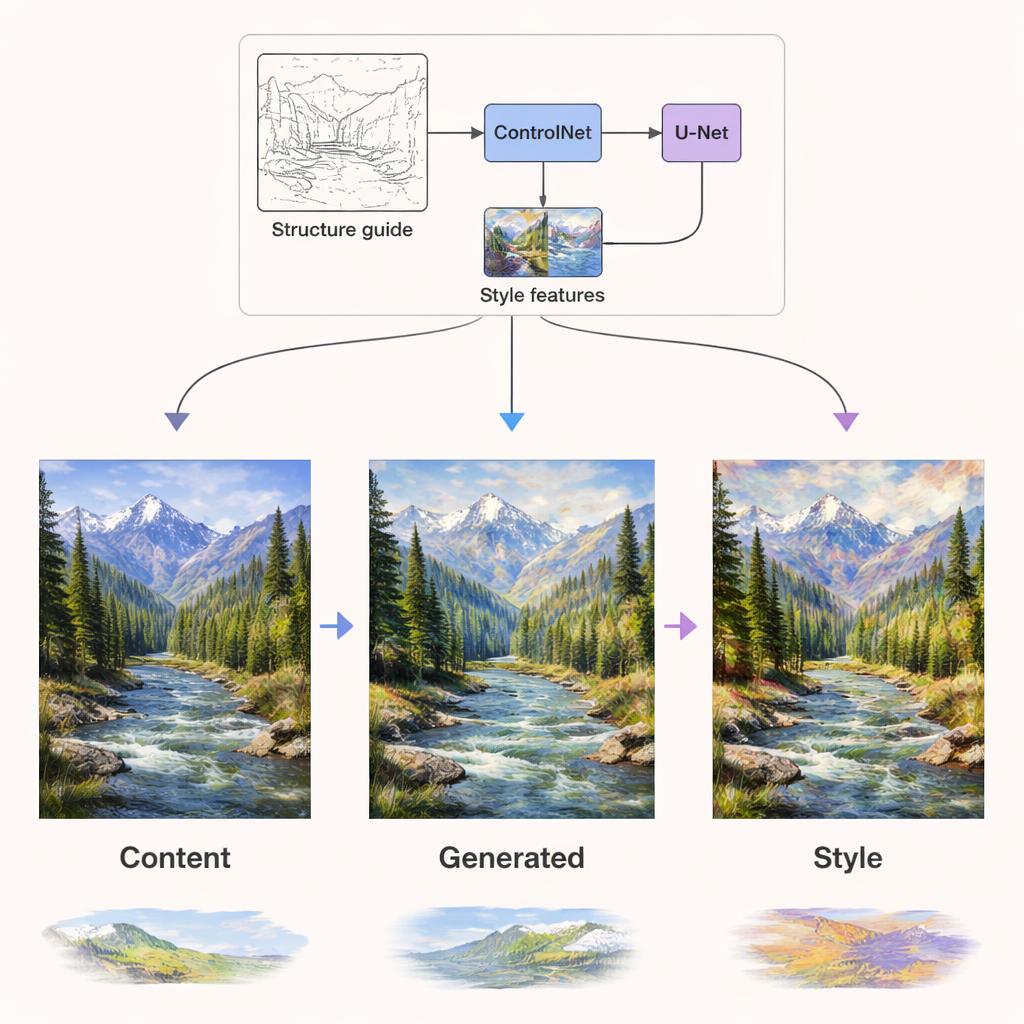
Лучшее качество, больше стилей, меньше вычислений
Авторы тщательно протестировали DCLSDM на двух публичных наборах данных: WikiArt, охватывающем десятки художественных направлений, и Summer2Winter Yosemite, посвящённом сезонным изменениям ландшафта. Они сравнили свою модель с рядом передовых систем, используемых в науке и индустрии. По показателям структурного сходства, воспринимаемого качества и тому, насколько сгенерированные изображения похожи на реальные произведения, DCLSDM стабильно получает высшие оценки. Она также работает быстрее, использует меньше памяти и содержит меньше параметров, чем многие конкуренты, при этом предлагая гибкое смешение нескольких стилей и поддерживая как стиль на основе изображений, так и на основе текста.
Что это значит для повседневного творчества
Практически это означает, что пользователям можно предоставить тонкий контроль над тем, как выглядит изображение, не жертвуя при этом его содержанием — и делать это на более скромном оборудовании. Дизайнеры смогут быстро исследовать множество художественных обработок одной и той же компоновки, мобильные приложения смогут предложить более насыщенные фильтры, которые не деформируют лица или сцены, а проекты по сохранению культурного наследия смогут реставрировать старые фотографии, сохраняя важные структурные детали. Чётко разделив содержание и стиль внутри современной диффузионной архитектуры, DCLSDM указывает на будущее, где творческие инструменты для изображений будут одновременно мощнее и надёжнее для повседневного использования.
Цитирование: Chu, K., Shang, Y., Zhang, L. et al. Content style decoupling for multi style image generation using latent diffusion architecture. Sci Rep 16, 6642 (2026). https://doi.org/10.1038/s41598-026-36407-3
Ключевые слова: перенос стиля изображения, диффузионные модели, разделение содержания и стиля, генерация цифрового искусства, эффективная генерация изображений