Clear Sky Science · ru
Рамочная модель обучения с подкреплением для компьютеризированного адаптивного тестирования с использованием подхода многоруких бандитов
Более умные тесты для цифрового класса
Кому приходилось сидеть на длинном едином экзамене, знакомо ощущение скуки и несправедливости. Одни вопросы слишком просты, другие — совершенно неподъёмны, и итоговый балл не всегда отражает реальные знания. В этой статье предложен новый способ построения компьютерных тестов, которые в реальном времени адаптируются к ответам каждого человека. Заимствуя идеи из современной искусственной интеллекта, авторы стремятся сделать экзамены короче, точнее и лучше соответствующими истинной способности каждого тестируемого.
Почему фиксированные тесты не дотягивают
Традиционные экзамены задают всем студентам одинаковый набор вопросов. Это упрощает подготовку теста, но теряется много информации: сильные обучающиеся просиживают над множеством слишком простых заданий, а слабые быстро перегружаются. Компьютеризированное адаптивное тестирование пытается исправить это, выбирая следующий вопрос на основе предыдущих ответов, но большинство современных систем по‑прежнему опираются на десятилетиями проверявшиеся статистические модели и вручную разработанные правила. Эти устаревшие подходы с трудом улавливают сложные закономерности в ответах и часто не способны полноценно учесть большую разницу между учащимися в современных масштабных онлайн‑средах.
Внедрение современных методов ИИ в тестирование
Авторы предлагают новую архитектуру, которая сочетает глубокое обучение и обучение с подкреплением для управления адаптивным экзаменом от начала до конца. Система работает в повторяющихся циклах. Сначала одномерная сверточная нейронная сеть (1D‑CNN) анализирует недавние ответы человека, сложность вопросов и другие сводные статистики. Из этого потока данных сеть выдает одно число, представляющее текущий уровень навыка человека на нормированной шкале — аналогично тому, как традиционные теории тестирования описывают способность, но усвоенное напрямую из данных. Сеть обучается распознавать тонкие паттерны, такие как устойчивые успехи на более сложных вопросах или неожиданные ошибки на простых. 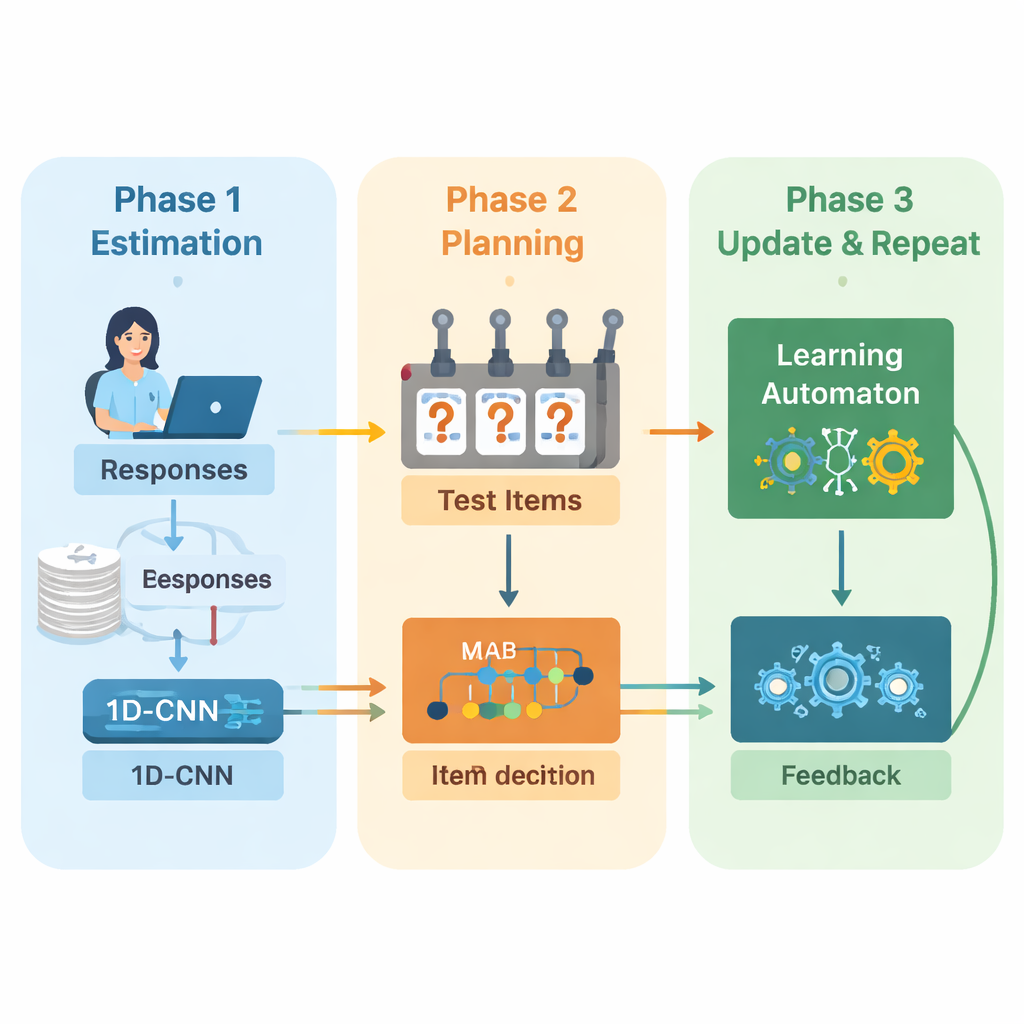
Выбор следующего вопроса
После обновления оценки способности системе нужно решить, что спросить далее. Здесь авторы применяют стратегию «многорукого бандита» — классический инструмент теории принятия решений, где каждое возможное действие рассматривается как рычаг игрового автомата. В этом контексте каждый вопрос в банке предметов — это рукав. Алгоритм отбирает вопросы, сложность которых примерно соответствует текущей оценке навыка, и затем выбирает те, которые ожидаются наиболее информативными. Он балансирует две цели: подобрать подходящую сложность, чтобы ответы не были ни слишком простыми, ни слишком трудными, и охватить как можно больше разных тем, чтобы тест не игнорировал важные разделы. Процесс выбора направляется функцией вознаграждения, которая сочетает эти две цели.
Обучение на собственных решениях
Чтобы продолжать улучшаться по ходу теста, система добавляет еще один обучающий компонент — автомат обучения (learning automaton). Этот модуль отслеживает, как меняется оценка способности между раундами и улучшается ли точность ответов человека или снижается. Он корректирует небольшой набор вероятностей, суммирующих ожидания модели относительно того, повысится ли способность, останется на том же уровне или упадет. Эти вероятности затем возвращаются в нейросеть в качестве дополнительного входа в следующем раунде. Так движок тестирования не только узнает о студенте, но и учится на собственных прошлых решениях — поощряя тенденции, которые вели к точным оценкам, и наказывая те, что не оправдались. 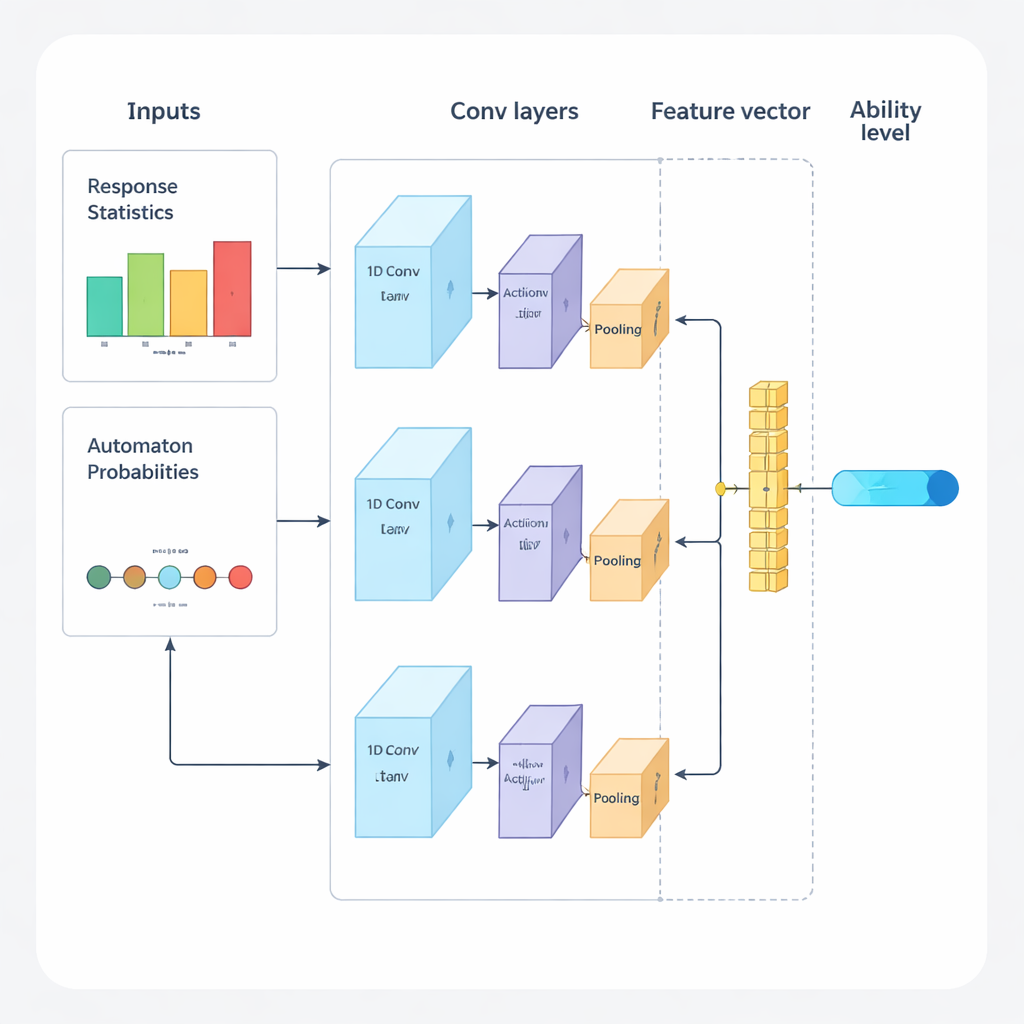
Насколько это работает на практике?
Исследователи оценили предложенную архитектуру на большом многоязычном наборе экзаменационных данных и тысячах смоделированных тестируемых с известными истинными уровнями навыка. Они сравнили свой подход с несколькими ведущими методами адаптивного тестирования. По ряду показателей ошибки и корреляции новая система давала более точные оценки способностей при меньшем числе вопросов. Ее ошибки — измеренные общепринятыми статистиками, такими как среднеквадратичная ошибка и средняя абсолютная ошибка — были заметно ниже, чем у конкурирующих методов. Одновременно система равномернее распределяла использование вопросов по банку заданий, снижая риск чрезмерной экспозиции и утечки отдельных вопросов.
Что это значит для будущих экзаменов
Проще говоря, работа указывает на то, что будущие компьютерные тесты могут ощущаться скорее как персонализированная репетиторская сессия, чем как жесткий экзамен. Вопросы будут быстро подстраиваться под правильную сложность для каждого человека, охватывать полный набор важных тем и завершаться, когда система уверена в определении уровня — часто после меньшего числа заданий, чем в нынешних тестах. Хотя метод по‑прежнему зависит от хороших обучающих данных и вычислительных ресурсов и пока проверен лишь на одном наборе данных, он указывает направление к новому поколению более умных, более справедливых и более эффективных оцениваний, естественно адаптирующихся к отдельным учащимся.
Цитирование: Tang, B., Li, S. & Zhao, C. Reinforcement learning framework for computerized adaptive testing using multi armed bandit approach. Sci Rep 16, 7441 (2026). https://doi.org/10.1038/s41598-026-36394-5
Ключевые слова: компьютеризированное адаптивное тестирование, образовательная оценка, глубокое обучение, обучение с подкреплением, многорукий бандит