Clear Sky Science · ru
Идентификация факторов риска для крупномасштабных аттракционов с использованием смеси экспертов и объединения нескольких моделей
Почему для безопасности парков развлечений нужно «умнее» читать тексты
Каждый год сотни миллионов людей садятся в американские горки, падающие башни и вращающиеся аттракционы, рассчитывая, что сложные механизмы и занятые операторы обеспечат их безопасность. За кулисами регуляторы и инженеры генерируют огромные объемы отчетов, записей об инцидентах и публичных жалоб — но большая часть этой информации представлена в виде текста, через который трудно быстро пройтись. В этом исследовании рассматривается, как продвинутые методы искусственного интеллекта могут «читать» эти документы в масштабе, раньше выявлять опасные закономерности и давать властям более ясное представление о том, где аттракционы склонны выходить из строя.
От разрозненных отчетов к единой картине рисков
В Китае сейчас эксплуатируется более 25 000 крупных аттракционов и принимается свыше 700 миллионов посетителей в год. Несмотря на общие улучшения в области безопасности, редкие, но серьёзные аварии всё ещё происходят, зачастую после того, как проверки не заметили ранние предупреждающие признаки, скрытые в технических описаниях или жалобах пользователей. Авторы утверждают, что традиционный надзор — основанный на периодических ручных проверках, экспертных суждениях и журналах обслуживания — слишком медлителен и субъективен для такой динамичной среды. Они собирают большой реальный корпус текстов, включающий отчёты об авариях, законы и стандарты, записи инспекций и обслуживания, а также онлайн-жалобы, связанные с объектами развлечений. После тщательной очистки и фильтрации этот многопроисхождений корпус становится сырьём для автоматизированной системы мониторинга рисков, управляемой данными. 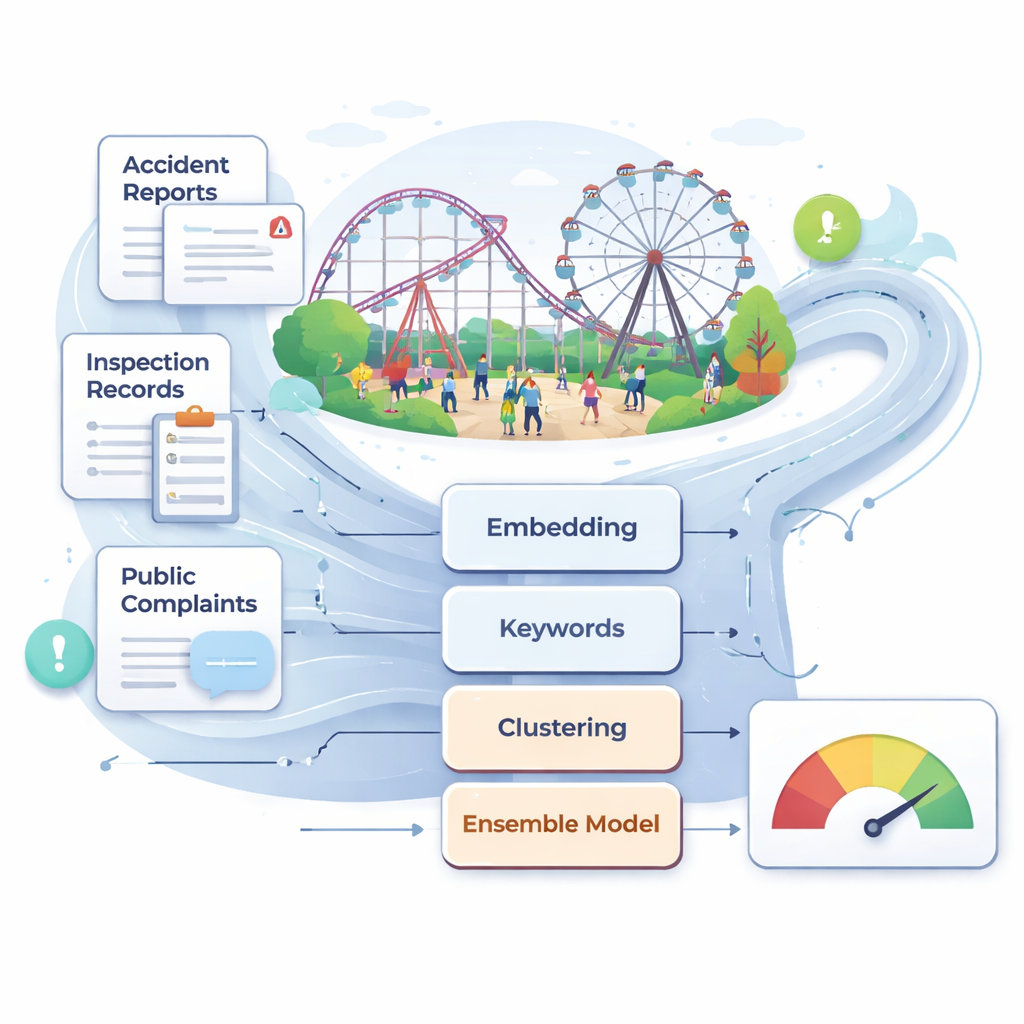
Обучение компьютеров понимать язык риска
Чтобы разбирать этот неструктурированный текст, исследователи опираются на современные языковые модели, которые преобразуют предложения в числовые векторы, отражающие их смысл. В основном они используют китайскую модель BGE, представляющую каждый фрагмент текста как точку в 1024-мерном пространстве, а также компактный набор из 30 признаков на основе ключевых слов, ориентированных на термины вроде «обслуживание», «инспекция» и «устранение неисправностей». Такое двойное представление — глубокий семантический контекст плюс вручную подобранные фразы риска — помогает системе различать тонкие различия, например между плановыми проверками и серьёзными неисправностями. Команда также экспериментирует с другой современной моделью эмбеддингов Qwen3, чтобы проверить, улучшится ли работа при смене языковой базы; на практике BGE показывает несколько лучшее качество на этой задаче безопасности.
Поиск скрытых закономерностей и уязвимых мест
Прежде чем классифицировать тексты по конкретным категориям риска, авторы используют методы безнадзорного обучения, чтобы выявить естественные группировки. Они применяют k-средних к эмбеддингам и используют метод визуализации UMAP, чтобы показать, что отчёты делятся на несколько отчётных тематических кластеров. Затем они строят семантический граф, где каждая вершина — ключевое слово, связанное с безопасностью, а ребра указывают на сильную со-встречаемость и семантическое сходство. Алгоритм обнаружения сообществ группирует эти вершины в кластеры, соответствующие широким темам, таким как безопасность оборудования и конструкции, повседневная эксплуатация и обслуживание, реагирование на чрезвычайные ситуации, а также управление и надзор. В этой сети некоторые слова — например «обслуживание», «инспекция» и «ответственность» — действуют как мосты между кластерами, подчёркивая сквозные слабости, которые могут вызвать аварии разными способами. Из этой структуры они выделяют 31 ключевой фактор риска, охватывающий четыре основные измерения — от мониторинга оборудования в реальном времени до ясности распределения обязанностей. 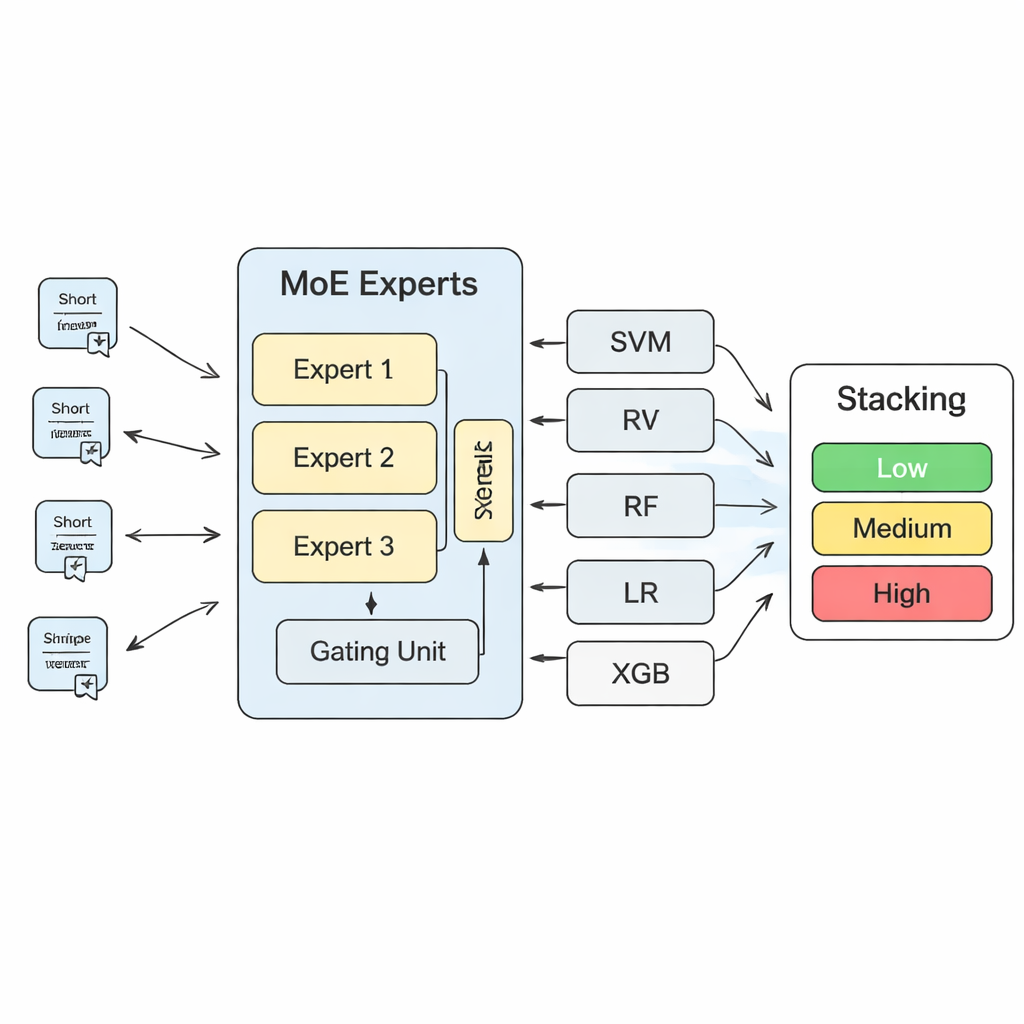
Смешение многих моделей в одного более сильного судью безопасности
Чтобы превратить эти наблюдения в конкретные прогнозы рисков, исследование строит многоуровневую систему машинного обучения. В её основе лежит модель «смесь экспертов» (Mixture of Experts, MoE): несколько нейронных сетей — экспертов — обучаются специализироваться на разных типах паттернов риска, а управляющий (gating) компонент решает, каким экспертам доверять больше для каждого нового текста. Выходы этой MoE-модели затем комбинируются с прогнозами более традиционных алгоритмов, таких как опорные векторы, случайные леса, логистическая регрессия и градиентный бустинг. Финальный слой «Stacking» — ещё одна модель машинного обучения — обучается взвешивать все эти мнения, чтобы прийти к окончательному решению. Через обширную кросс-валидацию авторы выяснили, что использование трёх экспертов в слое MoE обеспечивает оптимальный баланс между ёмкостью модели и её стабильностью.
Что эти достижения означают для реального надзора
По сравнению с любой одной моделью, система MoE плюс Stacking значительно улучшает точность, точность положительных прогнозов (precision), полноту (recall) и меру надёжности, называемую LogLoss. На практике это означает меньше пропущенных предупреждений и меньше ложных срабатываний при скрининге больших объёмов текстов о безопасности. Модель может запускаться на обычной рабочей станции и быстро выдавать оценки риска для новых отчётов об инспекциях или жалоб, что делает её инструментом поддержки принятия решений, а не заменой человеческого суждения. Авторы подчёркивают, что их подход может быть адаптирован не только для аттракционов, но и для другого специального оборудования, такого как лифты или канатные дороги. Для неспециалистов главный вывод таков: обучив компьютеры «читать» язык безопасности — в технических документах, регламентах и повседневных жалобах — регуляторы смогут раньше обнаруживать признаки опасности, умнее нацеливать проверки и сделать поход в парк немного безопаснее для всех.
Цитирование: Hao, S., Xing, L. & Zhang, M. Risk factor identification for large scale amusement facilities using mixture of experts and fusion of multiple models. Sci Rep 16, 6804 (2026). https://doi.org/10.1038/s41598-026-36377-6
Ключевые слова: безопасность аттракционов, текстовый анализ рисков, машинное обучение, смесь экспертов, мониторинг общественной безопасности