Clear Sky Science · ru
Многоуровневый метод фильтрации сетевых оповещений на основе алгоритма DBSCAN и вывода правил Rete
Почему важны более умные оповещения
Современные организации — от больниц и банков до поставщиков облачных услуг и городской инфраструктуры — зависят от сетей, которые работают круглосуточно. За этими сетями наблюдают средства безопасности, генерирующие тысячи оповещений в день — значительно больше, чем аналитики успевают просмотреть. Среди этого потока скрываются отдельные сигналы о реальных взломах или серьёзных уязвимостях. В статье предложен новый способ отделять такие критические сигналы от шума: он сокращает число ложных тревог, точнее обнаруживает реальные атаки и требует при этом очень небольших вычислительных ресурсов.
От неструктурированных логов к чистым, удобным данным
Оповещения сети поступают от множества устройств и производителей в различных форматах и с разной степенью детализации. Авторы сначала устраняют этот хаос с помощью аккуратной очистки и стандартизации. Все входящие оповещения приводятся к общей структуре и очищаются от дубликатов, пропусков полей и явных ошибок. Например, повторяющиеся предупреждения от разных устройств об одной и той же атаке в течение нескольких секунд объединяются в одну, более полную запись. В результате формируется упорядоченная база оповещений, которая сохраняет главное — что произошло, когда и какие системы были задействованы — и одновременно удаляет «мусор», замедляющий дальнейший анализ.
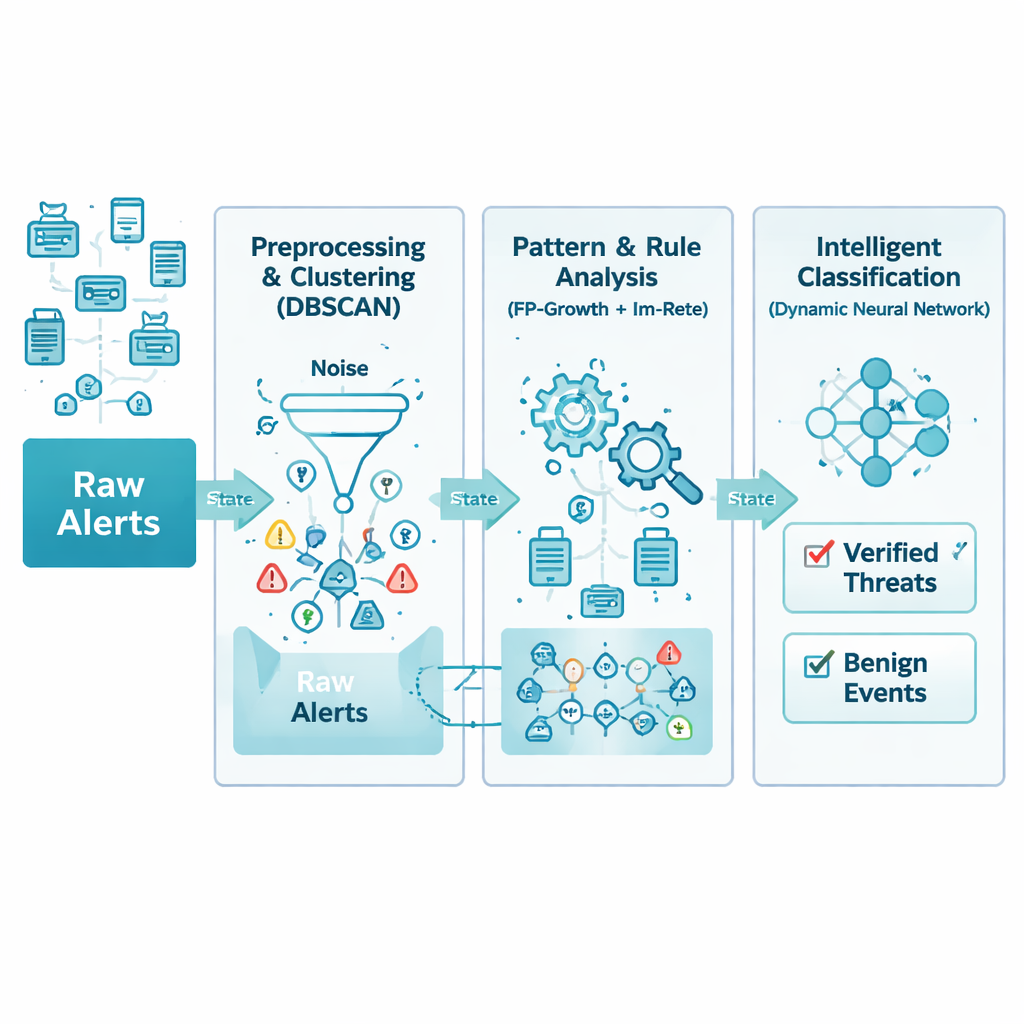
Разрешая временным шаблонам выявлять настоящие проблемы
Даже после очистки объём данных может оставаться огромным, поэтому следующий уровень анализа ищет естественные группировки по времени. Метод опирается на технику плотностного кластеризации, которая фактически ищет периоды, когда связанные оповещения появляются близко во времени, одновременно рассматривая разрозненные или случайные сигналы как шум. Это избавляет от необходимости заранее угадывать число типов инцидентов. Система также использует скользящие временные окна с перекрытием, чтобы быстродвижущиеся атаки не разбивались на разные пакеты. При тщательной настройке этот этап сохраняет наиболее информативные всплески активности и отбрасывает до трети вводящего в заблуждение фонового шума в исходных потоках.
Обучение правил работать с неполными данными
Реальные сети далеки от идеала: пакеты теряются, устройства работают некорректно, некоторые оповещения вообще не доходят. Традиционные движки правил ожидают полной информации и обычно терпят неудачу, если какой‑то фрагмент отсутствует. Авторы переработали классическую систему правил Rete так, чтобы каждое условие в правиле имело вес, отражающий его значимость. Вместо требования точного совпадения всех деталей движок проверяет, выстраивается ли достаточное число важных признаков во времени. Такой «нечёткий» подход позволяет системе распознать шаблон атаки даже если, скажем, раннее сканирование или незначительное срабатывание датчика не были зафиксированы. Одновременно редко используемые или долгое время неактивные ветви правил отсечены, чтобы снизить расход памяти.
Нейросеть, которая перестраивает себя
После того как шаблоны и правила преобразуют оповещения в более содержательные признаки, на финальном этапе нейросеть решает, какие события представляют реальную угрозу, а какие безопасны. В отличие от многих моделей машинного обучения, фиксированных после проектирования, эта сеть может увеличивать или сокращать свои скрытые слои в процессе обучения. Она начинает с небольшой архитектуры, добавляет элементы, когда это явно улучшает показатели, и убирает те части, которые не приносят пользы. Такая адаптивная конструкция помогает модели подстраиваться как под простые, так и под сложные наборы данных без необходимости ручного подбора, снижает риск переобучения и сокращает время обучения при сохранении высокой точности.
Что показывают тесты на практике
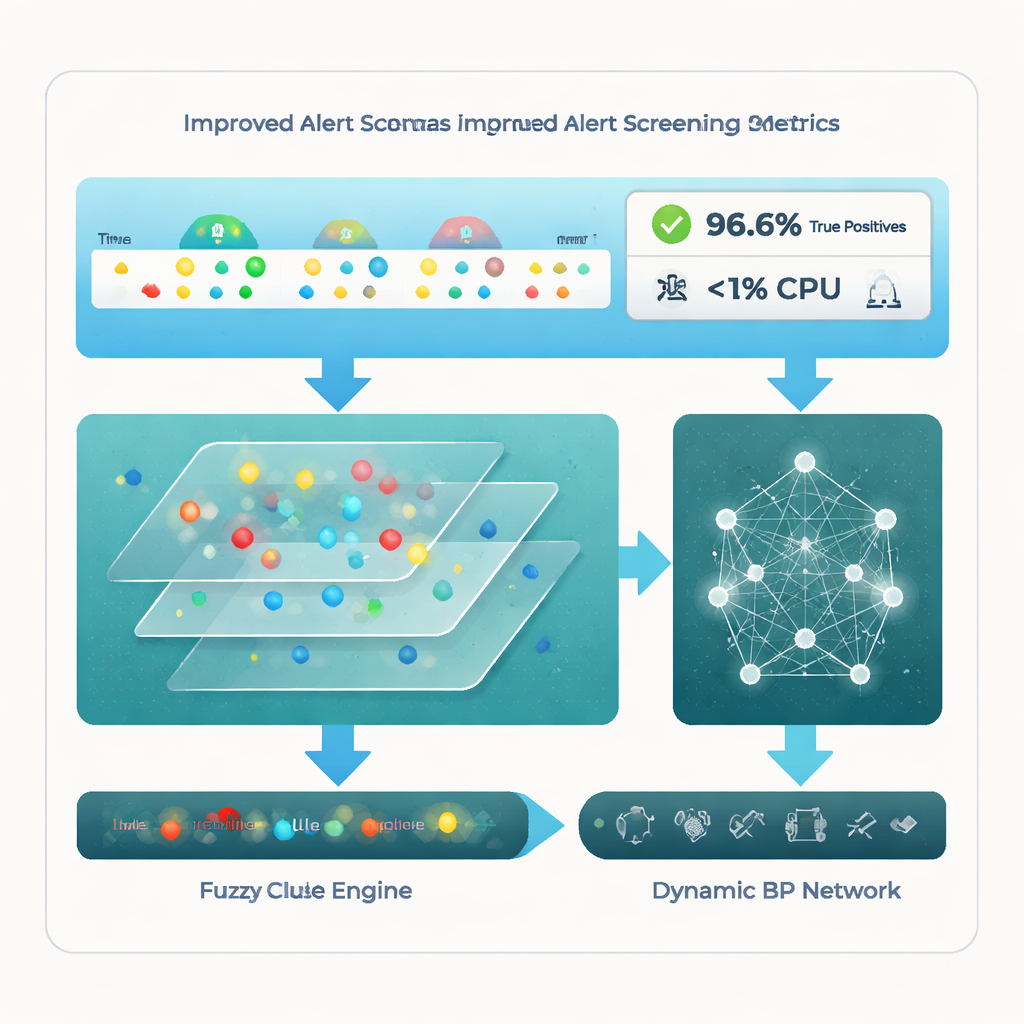
Команда оценила свою архитектуру на известных публичных наборах данных по вторжениям и на большой реальной коллекции корпоративных оповещений. В сравнении с четырьмя современными методами — включая чистую кластеризацию, специализированные решения для IoT и настроенные нейросети — новая многоуровневая цепочка выделяется. Она достигает доли истинных срабатываний примерно 96,6 %, то есть корректно отмечает почти все реальные атаки, удерживая долю шумных или нерелевантных оповещений примерно на уровне 18,7 %. Не менее примечательно, что при этом система использует менее 1 % CPU, что значительно ниже конкурентов. Статистические тесты подтверждают, что эти преимущества не случайны, а следуют из сочетания кластеризации, логического вывода по правилам и адаптивного обучения.
Что это значит для повседневной работы команд безопасности
Для аналитиков по безопасности, которые ежедневно тонут в потоке оповещений, эта работа указывает путь к инструментам, одновременно более точным и менее требовательным к железу. Очищая данные, группируя их по времени осмысленно, допуская неполноту сведений и применяя самонастраивающуюся нейросеть, фреймворк помогает выделить относительно небольшое множество оповещений, заслуживающих реального внимания. Это означает более быструю реакцию на настоящие атаки, меньше потраченных часов на ложные следы и эффективное использование имеющегося оборудования. По мере роста и усложнения сетей такая многоуровневая фильтрация может стать ключевым элементом защиты цифровой инфраструктуры без перегрузки людей, которые её охраняют.
Цитирование: Ni, L., Zhang, S., Huang, K. et al. Multi-level screening method for network security alarms based on DBSCAN algorithm and rete rule inference. Sci Rep 16, 5632 (2026). https://doi.org/10.1038/s41598-026-36369-6
Ключевые слова: сетевой безопасность, обнаружение вторжений, фильтрация оповещений, машинное обучение, обнаружение кибератак