Clear Sky Science · ru
Распознавание намёков в китайской и российской дипломатической речи с помощью больших языковых моделей
Чтение между строк
Когда дипломаты выступают публично, то, что они не говорят, может иметь такое же значение, как и выбранные слова. В этом исследовании изучается, может ли современный искусственный интеллект улавливать тонкие намёки и завуалированные послания на пресс‑конференциях министерств иностранных дел Китая и России — сигналы, которые часто ускользают от человеческих слушателей, но способны влиять на международные отношения.
Почему намёки важны в международных делах
Дипломатическая речь спроектирована так, чтобы быть осторожной и вежливой. Государствам нужно отстаивать свои интересы, не провоцируя открыто соперников и не пугая общественность. Поэтому официальные лица нередко прибегают к намёкам — фразам, которые на поверхности звучат нейтрально, но скрытно критикуют, предупреждают или сигнализируют о политической позиции. Неправильная интерпретация таких намёков в прошлом способствовала кризисам и недоверию между государствами. Понимать эти косвенные послания особенно трудно через языковые и культурные границы, где общий фон знаний не может считаться само собой разумеющимся.
От классической теории к умным машинам
Десятилетиями лингвисты и философы изучали, как говорящие подразумевают больше, чем говорят буквально. Ранние теории сосредотачивались главным образом на намерениях говорящего и предполагали, что рациональный слушатель способен восстановить скрытый смысл. Поздние работы в области «когнитивной прагматики» подчёркивали, что понимание намёков также зависит от умственных процессов слушателя, его культурного фона и контекста. Авторы описывают намёки как многослойные: видимая формулировка (вербально‑семантический уровень), культурно сформированные способы мышления за ней (лингвистико‑когнитивный уровень) и мотивы и стратегии говорящего, такие как критика, предупреждение или сохранение лица (мотивционно‑прагматический уровень).
Как была построена система ИИ
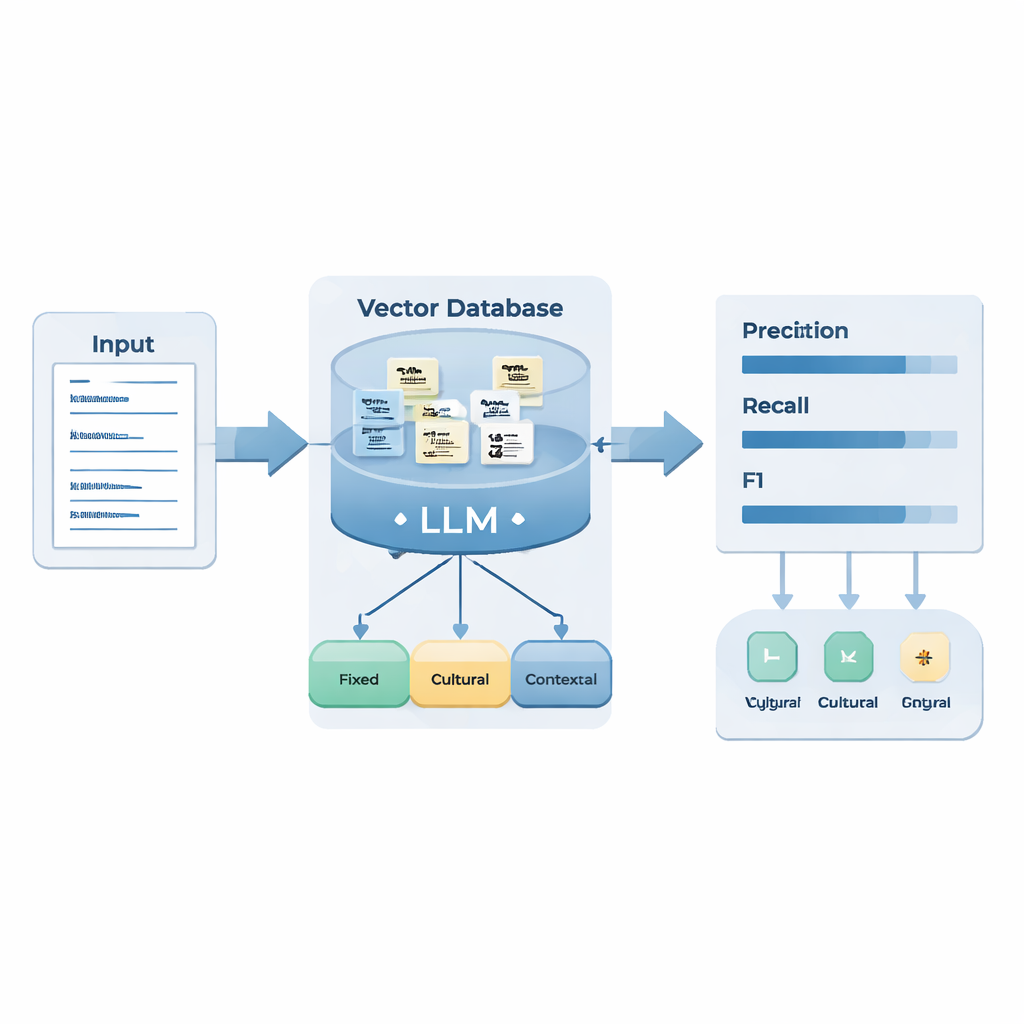
Исследователи собрали почти 1400 сегментов «вопрос–ответ» с официальных пресс‑конференций министерств иностранных дел Китая и России, проведённых в 2024 году. Экспертные лингвисты вручную аннотировали 498 случаев, где представители говорили намёком, а не прямо. Эти случаи были сгруппированы в три типа: «фиксированные намёки» со стабильной, повторяющейся формулировкой (например, стандартные дипломатические формулы), «культурные намёки», значение которых опирается на общий культурный багаж и метафоры, и «контекстуальные намёки», которые можно распознать лишь при внимательном учёте конкретной ситуации и мотивов. Эти примеры использовались для создания внешней базы знаний и разработки набора правил рассуждения для большой языковой модели.
Обучение модели пошаговому мышлению
Команда сочетала две техники ИИ. Retrieval‑Augmented Generation (RAG) позволяет модели извлекать релевантные примеры из специальной базы намёков при обработке нового ответа с пресс‑конференции. Chain‑of‑Thought (CoT)‑побуждение заставляет модель рассуждать пошагово: определить язык, разбить ответ на предложения, проверить известные шаблоны намёков, решить, выражает ли предложение определённый мотив (например, критику или предупреждение) через распознанную стратегию (например, фактическое утверждение, контраст или ирония), и в конце пометить его как фиксированный, культурный, контекстуальный намёк или «нет намёка». Система также выполняет самопроверку, чтобы убедиться, что подразумеваемый смысл действительно отличается от буквальной формулировки.
Насколько хорошо это сработало?
Для проверки системы авторы использовали новые данные с пресс‑конференций 2025 года на обоих языках. В целом улучшенная модель убедительно справилась с выявлением скрытых сообщений: она улавливала большинство подлинных намёков (высокая полнота) и добивалась достойного баланса между обнаружением и ложными срабатываниями (F1‑score 0.83 для русского и 0.76 для китайского). Особенно хорошо модель справлялась с фиксированными намёками в обеих языках, что подтверждает идею о том, что стабильные шаблоны легче всего усваиваются машинами. Однако модель испытывала большие трудности с китайскими культурными и контекстуальными намёками, чем с российскими. Авторы связывают этот разрыв со стилевыми различиями: российская дипломатическая речь часто использует яркие метафоры и резкие контрасты, которые чётко сигнализируют критику или предупреждение, в то время как китайский дискурс больше опирается на нейтральные формулы, идиомы и зависящую от контекста вежливость, которые сложнее отличить от буквальных высказываний.
Что показывают ошибки — и как улучшить
При внимательном разборе ошибок авторы выявили три повторяющиеся проблемы. Иногда модель «читала слишком много», выдумывая скрытые смыслы там, где их не было. Иногда она обнаруживала намёк, но присваивала неверный тип, размывая границу между фиксированными и контекстуальными случаями. А иногда она просто принимала обычную формулировку за намёк из‑за наличия определённых чувствительных слов или знакомых паттернов. Чтобы устранить эти слабые места, в статье предлагается добавить множество явных «без‑намёка» дипломатических фраз в качестве негативных примеров, обязать систему жёстче привязывать выводы к реальному вопросу и окружению, сопоставлять предложения с базой знаний несколько раз с переформулировками и ввести предварительный фильтр и шаг самопроверки, который спрашивает: это уже явно сказано или действительно подразумевается?
Почему это важно для остальных
Для неспециалистов главный вывод таков: большие языковые модели уже могут помогать аналитикам просеивать большие объёмы официальных заявлений и отмечать места, где правительства могут говорить между строк. В то же время исследование подчёркивает, насколько дипломатия зависит от культуры, истории и стиля — факторов, которые остаются трудными даже для продвинутого ИИ. Объединяя лингвистическую теорию с современными инструментами ИИ, эта работа указывает путь к более надёжным системам отслеживания тонких сигналов в мировой политике, одновременно подчёркивая, что человеческое суждение и кросс‑культурная экспертиза по‑прежнему необходимы для интерпретации того, что остаётся неудобно высказанным.
Цитирование: Guo, Y., Wang, X. Hint recognition in Chinese and Russian diplomatic discourse using large language models. Sci Rep 16, 5751 (2026). https://doi.org/10.1038/s41598-026-36338-z
Ключевые слова: дипломатический язык, косвенный смысл, большие языковые модели, кросс-лингвистический анализ, генерация с поддержкой поиска