Clear Sky Science · ru
Глубокая сеть Inception с остаточными связями для распознавания рукописных символов тамильского языка
Сохранение рукописного наследия в цифровую эпоху
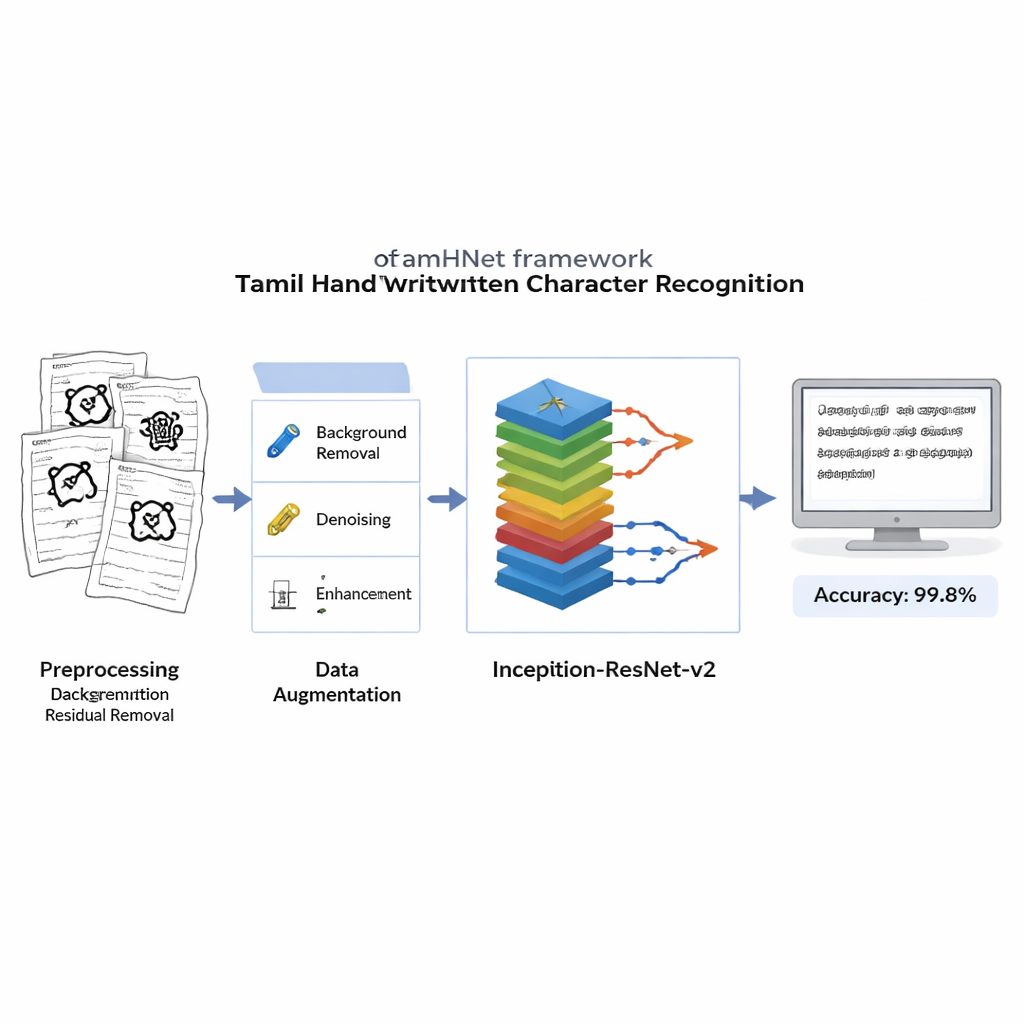
От старых листов пальмовых деревьев до повседневных заметок — значительная часть письменного наследия тамильского языка по-прежнему находится на бумаге. Преобразование этого богатого массива рукописных страниц в оцифрованный, индексируемый текст жизненно важно для сохранения культуры, поддержки образования и создания лучших языковых технологий. В этой статье представлена новая система компьютерного зрения под названием TamHNet, которая с почти идеальной точностью читает тамильские рукописи, даже когда буквы выглядят сбивающе похоже друг на друга.
Почему тамильские буквы сложны для компьютеров
Тамильским языком пользуются более 80 миллионов человек, и в нём используется письмо, включающее 247 символов: гласные, согласные и многочисленные их сочетания. Многие буквы различаются лишь крошечными завитками или дополнительными штрихами, к тому же писатели сильно различаются по стилю формирования символов. Пары, таких как எ/ஏ или ஒ/ஓ, на первый взгляд могут выглядеть практически одинаково, а символы вроде ல и வ легко перепутать. Ранние компьютерные программы и даже современные системы машинного обучения часто испытывали трудности с этими нюансами, что приводило к ошибочному чтению слов и ненадёжной оцифровке документов.
Создание реального набора рукописных данных
Чтобы обучить и протестировать систему в реалистичных условиях, исследователи собрали новый набор данных Tamil Isolated Character Dataset, включающий рукописные образцы от 1000 студентов университета. Вместо использования синтетических или сгенерированных компьютером изображений они собрали подлинные символы, написанные пером по бумаге, охватывающие 12 гласных, 18 согласных и 214 распространённых сочетаний. Команда тщательно разметила эти образцы и сделала набор данных общедоступным, чтобы другие исследователи могли сравнивать методы и развивать эту работу. Организовав алфавит в 104 базовых символа, которые охватывают все 247 знаков, они сократили избыточность, сохранив при этом полный диапазон форм, встречающихся в реальной рукописи.
Очистка, деформация и обучение изображений
Прежде чем начать обучение, каждое отсканированное изображение очищают от шумного фона, пятен и неравномерного освещения, при этом сохраняют тонкие штрихи, определяющие символ. Изображения преобразуют в чёрно‑белый формат и приводят к стандартному размеру, чтобы компьютер видел каждый пример одинаково. Чтобы сделать систему устойчивой к различным почеркам, авторы применяют контролируемые искажения: они слегка смещают ключевые точки на изображении и выполняют плавные деформации, генерируя новые версии каждого символа, которые для человека всё ещё выглядят как та же буква. Этот расширенный учебный набор помогает модели правильно распознавать символы даже если они наклонены, сжаты или написаны с необычными пропорциями.
Глубокая сеть, которая учится улавливать тонкие различия
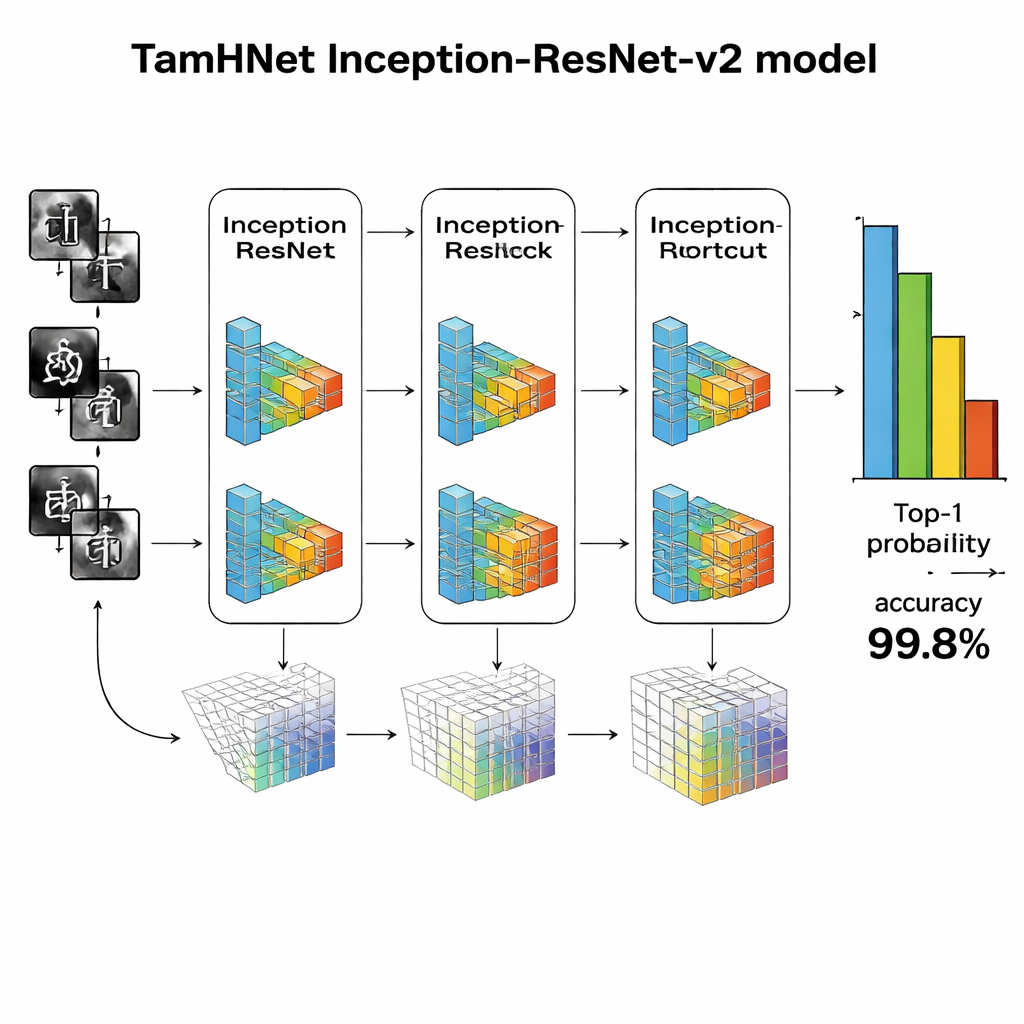
В основе TamHNet лежит мощная архитектура глубокого обучения Inception-ResNet-v2, изначально созданная для распознавания общих объектов. Авторы адаптируют и донастраивают эту сеть специально для задач тамильской рукописи. Модель пропускает каждое изображение через множество слоёв, которые постепенно преобразуют сырые пиксели в более высокоуровневые паттерны, такие как края, кривые и части символов. Особые «короткие» пути, известные как остаточные соединения, стабилизируют обучение и помогают сети сфокусироваться на небольших, но ключевых различиях между похожими буквами. Вместо того чтобы сразу настраивать все внутренние параметры, команда выборочно «размораживает» наиболее полезные слои и настраивает их для этой задачи. Они используют метод оптимизации Adam, который автоматически подстраивает скорость изменения каждого параметра, позволяя сети эффективно обучаться на сложных и иногда нерегулярных рукописных данных.
Насколько хорошо система читает рукопись
Исследователи оценили TamHNet на новом наборе данных, используя стандартные метрики качества распознавания. Система достигает примерно 99,8% точности по 104 классам символов, превосходя широкий спектр предыдущих методов на основе опорных векторов, традиционных сверточных сетей и других современных конструкций глубокого обучения. Детальные тесты показывают, что даже символы с чрезвычайно похожими формами в большинстве случаев различаются правильно, а статистические кривые подтверждают, что модель очень редко путает один символ с другим. По сравнению с предыдущими работами это представляет собой явный шаг вперёд в надёжности распознавания рукописных символов тамильского языка.
Что это означает для читателей и архивов
Для неспециалистов основная мысль такова: компьютеры заметно лучше научились читать тамильский рукописный текст. Система вроде TamHNet может стать основой инструментов, превращающих стопки тетрадей, исторические рукописи и рукописные формы в индексируемый цифровой текст с минимальной потребностью в ручной корректировке. Хотя текущая модель ещё не обрабатывает некоторые символы с точками и древние варианты письма, авторы намечают планы расширить её на древние стили письма. Практически это исследование приближает нас к масштабной и точной оцифровке тамильских документов, помогая сохранять культурное наследие и облегчая доступ к письменным знаниям для будущих поколений.
Цитирование: Periyasamy, H., Natarajan, S. & Amirtharajan, R. Deep inception neural network with residual connections for Tamil handwritten character recognition. Sci Rep 16, 6053 (2026). https://doi.org/10.1038/s41598-026-36330-7
Ключевые слова: распознавание рукописных символов тамильского языка, оптическое распознавание символов, глубокое обучение, Inception-ResNet, цифровое сохранение