Clear Sky Science · ru
Сравнение эффективности крупных языковых моделей при оценке знаний по бор-нейтронной терапии захвата
Умные репетиторы для нового вида лучевой терапии рака
Бор-нейтронная терапия захвата, или BNCT, — это развивающийся тип лучевой терапии, направленный на уничтожение опухолей при минимальном повреждении окружающих здоровых тканей. По мере того как эта сложная методика переходит из исследовательских лабораторий в клиники, врачам и стажерам требуется освоить большое количество новой, специализированной информации. В этом исследовании задается своевременный вопрос: могут ли современные популярные чат‑боты на базе искусственного интеллекта помогать в обучении и поддержке BNCT, и если да — насколько им можно доверять?
В чем отличие BNCT от обычной лучевой терапии?
BNCT работает совсем иначе, чем стандартные рентгеновские или протонные методы. Пациентам вводят препараты с особой формой бора, которая накапливается в опухолевых клетках. Когда эти клетки затем облучают потоком нейтронов, атомы бора проходят небольшую ядерную реакцию, высвобождая частицы с коротким радиусом действия, которые убивают раковую клетку изнутри, практически не затрагивая соседние ткани. Такой высокоцелевой подход особенно перспективен для трудноизлечимых или бедных кислородом опухолей. До недавнего времени BNCT зависела от ядерных реакторов как источников нейтронов, что ограничивало её клиническое применение. Одобрение ускорительно‑основанных BNCT‑установок в Японии в 2020 году и появление новых центров в таких странах, как Китай, сделали BNCT реальной опцией для большего числа пациентов и создали острую необходимость в целенаправленном обучении и сертификации.
Испытание четырех ведущих ИИ
Чтобы оценить, как универсальные чат‑боты справляются с темами BNCT, исследователи разработали тест из 47 вопросов, охватывающих базовые концепции, последние исследования, клиническую практику, а также задачи на расчеты и рассуждения. Вопросы были составлены на китайском и английском языках и включали простые факты (например, определения) и более сложные задачи, требующие логики или вычислений. Четыре крупных семейства ИИ — представленные широко используемыми системами от разных компаний — тестировали в течение пяти отдельных периодов, на двух языках и в двух форматах подачи (прямые вопросы и вопросы в контексте короткого клинического сценария). Ответы оценивали специалисты по онкологической помощи по эталонному ключу, а также фиксировали, как часто ИИ признавали неопределенность, говоря что-то вроде «я не знаю».
Кто ответил лучше и на какие вопросы?
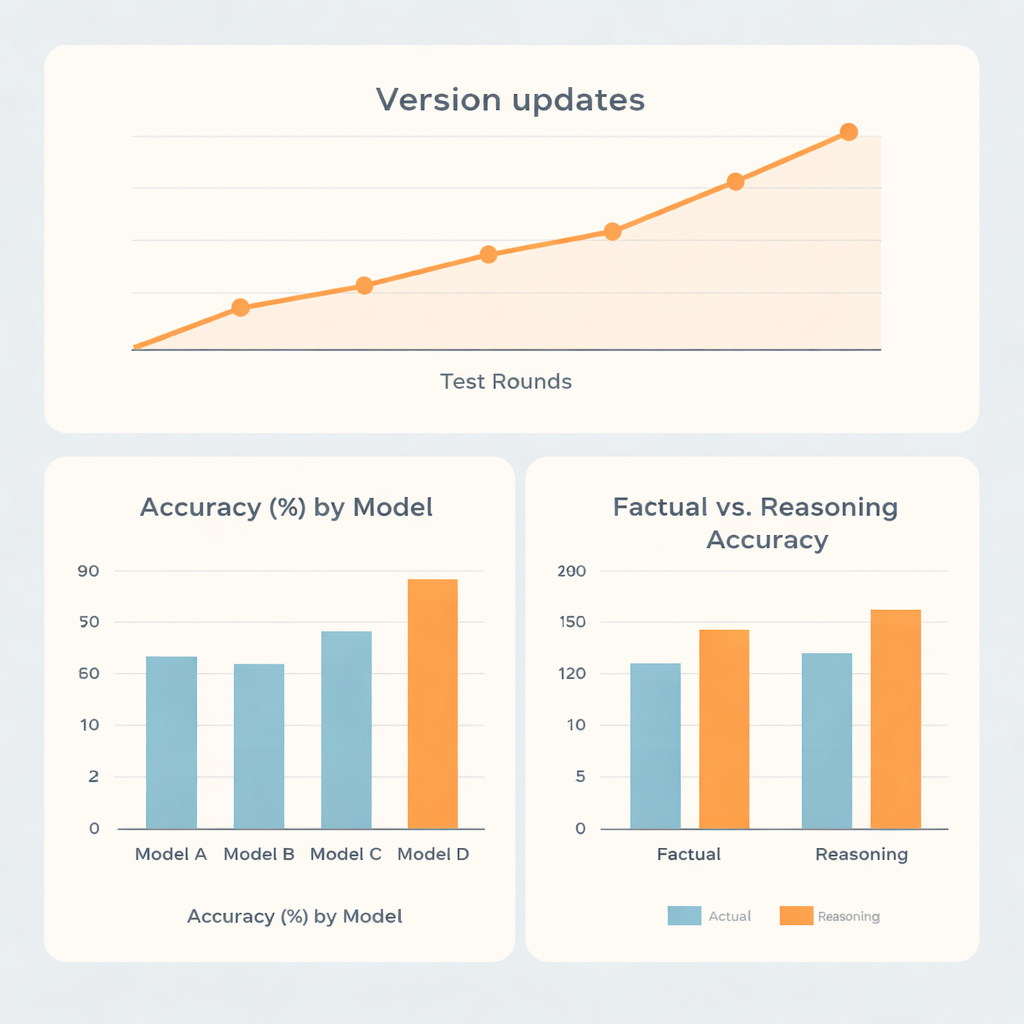
В целом два семейства моделей показали заметно лучшие результаты, чем другие два. Лучшая система достигла примерно 73% точности, вторая — около 70%, а оставшиеся модели набрали примерно 62% и 56%. Примечательно, что лидеры не ограничивались запоминанием фактов: они были заметно сильнее в вопросах, требующих рассуждений, чем в простом воспроизведении сведений. Это указывает на относительную силу этих систем в многошаговом мышлении, например при расчетах доз или при задачах планирования внутри этой узкой медицинской области. Одна модель показала почти одинаковые результаты на фактах и задачах на рассуждение, тогда как другая в целом отставала, несмотря на относительно лучшее поведение в задачах на рассуждение по сравнению с фактологическими пунктами.
Обновления, языки и готовность сказать «я не знаю»
Поскольку системы ИИ часто обновляются, исследователи также изучили, как менялась производительность в пяти раундах тестирования с конца 2023 по середину 2025 года. Крупные обновления версий обычно давали заметные скачки точности, тогда как мелкие правки внутри одной версии мало влияли. Одно семейство поднялось с уровня ниже 60% до более чем 80% за это время, что подчёркивает скорость прогресса технологий. Удивительно, но язык вопросов — китайский или английский — и формат подачи (прямой вопрос или ролевая подача) оказывали лишь небольшое влияние по сравнению с внутренними сильными сторонами каждой модели. Более заметными были различия в том, насколько откровенно системы признавали неопределенность при ошибках. Некоторые модели допускали признание неуверенности почти в одном из пяти неверных ответов, тогда как другая редко это делала, часто давая уверенные, но ошибочные ответы.
Что это значит для врачей, студентов и пациентов
Авторы приходят к выводу, что лучшие на сегодняшний день универсальные чат‑боты уже способны давать относительно точные объяснения и учебные вопросы по BNCT, что делает их перспективными помощниками в обучении и самообразовании. Однако ни одну из систем пока нельзя полностью доверять в ответах на все вопросы по BNCT, и их стилевые различия в выражении или сокрытии неопределенности имеют значение для безопасности. В настоящее время эти инструменты лучше рассматривать как умных ассистентов, которые могут поддерживать, но не заменять экспертную оценку. Авторы утверждают, что потребуются специализированные модели ИИ, ориентированные на BNCT, а также четкие стандарты использования таких инструментов в клиниках и учебных заведениях, прежде чем ИИ сможет надёжно играть ведущую роль в этой высокоспециализированной области онкологической помощи.
Цитирование: Shen, S., Wang, S., Gao, M. et al. Performance comparison of large language models in boron neutron capture therapy knowledge assessment. Sci Rep 16, 5321 (2026). https://doi.org/10.1038/s41598-026-36322-7
Ключевые слова: бор-нейтронная терапия захвата, лучевая терапия при раке, медицинское образование, искусственный интеллект, крупные языковые модели