Clear Sky Science · ru
Контрастное предварительное обучение языка и изображений с учётом объектов для нулевой эффективной распознаваемости целей
Более тонкий взгляд для загруженного неба и моря
Современные системы безопасности и реагирования на чрезвычайные ситуации полагаются на камеры в небе и на море, чтобы обнаруживать самолёты, корабли и другие важные объекты. Но научить компьютеры отличать истребитель от пассажирского лайнера или военный корабль от грузового судна оказывается неожиданно сложно, когда сцены загромождены, данных мало, а новые модели техники постоянно появляются. В этой статье представлен OG‑CLIP — новая система ИИ, рассчитанная на распознавание военных и гражданских целей, на которых она не обучалась напрямую, объединяя большие объёмы априорных знаний с более чёткой визуальной фокусировкой на значимых объектах.
Почему традиционный ИИ промахивается
Большинство систем распознавания изображений учатся на огромных коллекциях размеченных картинок: каждое изображение привязано к фиксированному набору категорий, например «кот» или «машина». Такой подход даёт сбои в специализированных областях, таких как оборона и дистанционное зондирование, где данные чувствительны, разметку должны выполнять эксперты, а разнообразие техник огромное. Новые визуально‑языковые модели вроде CLIP сопоставляют изображения с короткими текстами, собранными в интернете, что позволяет им распознавать новые понятия, описанные словами. Тем не менее в военной съёмке эти модели всё ещё испытывают трудности: подписи часто расплывчаты, фон вроде облаков и волн доминирует в пикселях, а их внутренние представления недостаточно гибки, чтобы эффективно работать и на маленьких дронах, и на мощных серверах. OG‑CLIP решает эти три проблемы сразу.
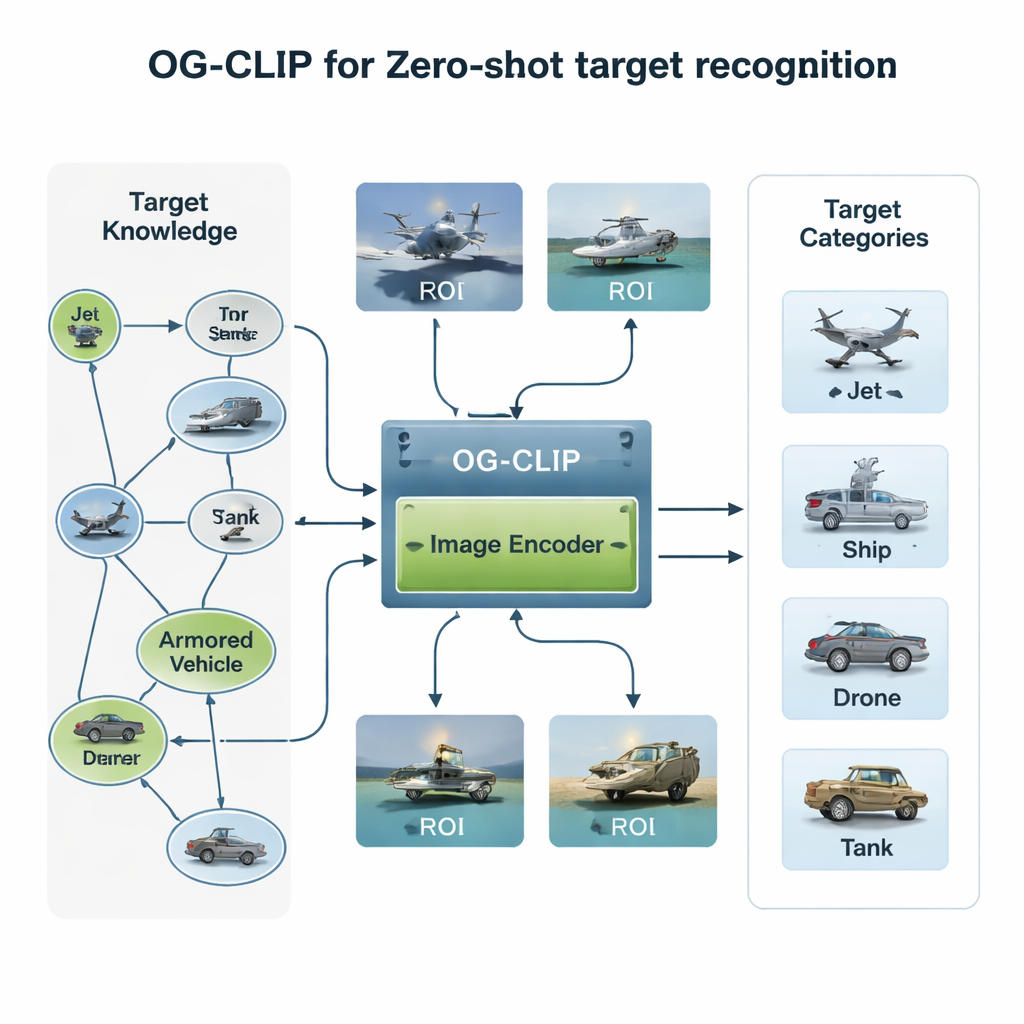
Построение обучающего мира, насыщенного знаниями
Первый компонент OG‑CLIP — тщательно спроектированная обучающая среда. Авторы собрали базу данных из 5000 типов целей — от истребителей и бомбардировщиков до военных кораблей и гражданских самолётов — и организовали их в подробный граф знаний. Каждая запись содержит структурированные факты, такие как дальность, масса и конфигурация вооружения, взятые из общедоступных справочников по обороне, энциклопедий и технической документации. Затем они собрали около миллиона изображений из публичных наборов данных, веб‑поиска, старых внутренних архивов и даже смоделированных сцен игровых движков. Чтобы повысить надёжность данных, изображения сгруппировали с помощью существующей модели для выявления выбросов, провели экспертную проверку и отфильтровали некорректные метки. Наконец, использовали современные языково‑визуальные инструменты, чтобы превратить граф знаний в насыщенные, естественно‑языковые описания каждого снимка, так что система учится не просто «это самолёт», а «однофюзеляжный самолёт с выгнутыми вверх законцовками крыла» или «стелс‑бомбардировщик с летающим крылом».
Обучение модели игнорировать шум
Второе новшество заключается в том, куда модель «смотрит». На многих спутниковых или аэрофотоснимках реальный корабль или самолёт занимает лишь небольшую область, окружённую отвлекающим небом, морем или ландшафтом. OG‑CLIP добавляет модуль области интереса (ROI), имитирующий то, как человек мельком выделяет ключевой объект, а не весь кадр. Современный инструмент сегментации автоматически выделяет вероятные объекты на изображении, создавая мягкие маски, которые подчёркивают цель и затемняют фон. Эти маски вместе с исходным изображением подаются в визуальную часть модели, так что её внимание естественным образом концентрируется на отличительных признаках: форме крыла, планировке палубы или силуэте корпуса. Такой плагин можно добавить к существующим системам без переписывания их основной архитектуры, придавая им более «объект‑ориентированный» взгляд.

Адаптация детализации под железо
Третья составляющая решает практическую, но важную проблему: не все устройства могут позволить себе одинаковый уровень детализации. Наземная станция спутника может обрабатывать богатые, высокоразмерные признаки, тогда как небольшой дрон нуждается в более быстрых и лёгких вычислениях. Традиционные методы фиксируют один размер признака или тренируют несколько отдельных моделей для разных размеров. OG‑CLIP вместо этого использует представление в стиле «матрёшки», упаковывая информацию на нескольких уровнях детализации в один вектор, как вложенные куклы. Система умеет отрезать короткие или длинные части этого вектора — более грубые или более тонкие описания содержимого изображения — без дообучения. Механизм взвешивания поощряет каждый уровень сохранять наиболее полезную для классификации информацию, а дополнительный член функции потерь подталкивает уровни к семантической согласованности друг с другом.
Насколько хорошо это работает на практике?
Чтобы протестировать OG‑CLIP, исследователи собрали сложный тестовый набор из 99 категорий целей, включая 51 тип военных самолётов, 29 типов военных кораблей и 19 гражданских или смешанных целей. Важно, что ни одна из этих категорий не встречается в обучающих данных, поэтому система вынуждена полагаться на накопленные языковые и визуальные представления — тест в режиме «нулевого примера». По сравнению с несколькими сильными базовыми моделями на основе CLIP, OG‑CLIP улучшил среднюю точность более чем на 11 процентных пунктов, достигнув в целом 84,28 процента. Особенно хорошо модель показала себя на перегруженных, сложных сценах и при тонком различении похожих моделей, например разных истребителей, где модуль ROI и описания, насыщенные знаниями, дали заметное преимущество. Аба́ляционные исследования показали, что каждый компонент — данные графа знаний, фокус ROI и адаптивные представления — вносил измеримый вклад.
Что это значит для мониторинга в реальном мире
Для неспециалистов главный вывод в том, что OG‑CLIP — это шаг к системам безопасности и мониторинга, которые могут надёжнее распознавать незнакомые самолёты и корабли по реальным изображениям, даже когда размеченных примеров мало. Объединяя структурированные экспертные знания, автоматическую фокусировку на объекте интереса и регулируемые уровни детализации, подход делает визуально‑языковой ИИ одновременно умнее и практичнее. За пределами обороны похожие идеи могут помочь в экологическом мониторинге, реагировании на бедствия и промышленной инспекции, позволяя системам понимать сложные сцены на самых разных аппаратных платформах.
Цитирование: Zheng, C. Object-guided contrastive language-image pre-training for zero-shot target recognition. Sci Rep 16, 6425 (2026). https://doi.org/10.1038/s41598-026-36314-7
Ключевые слова: нулевое распознавание, визуально-языковые модели, обнаружение объектов, дистанционное зондирование, графы знаний