Clear Sky Science · ru
Трансформеры глубокого обучения, основанные на зрительном восприятии, для классификации картин и фотографий через извлечение признаков
Почему это важно для повседневных изображений
В эпоху, когда любой может одним кликом сгенерировать реалистичную картинку, становится всё труднее понять, является ли изображение настоящей фотографией, традиционной картиной или чем-то, полностью созданным алгоритмами. В этом исследовании изучается, как современные методы искусственного интеллекта могут автоматически отличать созданные человеком картины от фотоснимков, сделанных камерой, а также от изображений, сгенерированных ИИ, что помогает защищать арт-рынки, архивы и пользователей в интернете от путаницы и подделок.
Искусство, фото и рост машинной графики
Картины и фотографии на первый взгляд могут выглядеть схоже на экране, но у них разные визуальные отпечатки. Картины обычно демонстрируют заметные мазки кисти, стилизованные цвета и более абстрактные композиции, тогда как фотографии чаще содержат более чёткие детали и естественное освещение. В то же время новые генераторы изображений всё лучше имитируют оба типа. Музеям, галереям, коллекционерам и цифровым платформам всё больше нужны инструменты, которые быстро и надёжно определяют тип изображения — как для аутентификации произведений, так и для управления потоком синтетического контента.
Новый конвейер для «обучения» машин видеть
Исследователи создали полный конвейер анализа изображений на базе Vision Transformer — современной модели глубокого обучения, изначально разработанной для обработки языка и теперь адаптированной к изображениям. Они обучили эту систему на публичном наборе данных Kaggle, включающем 1 361 картину и 3 747 фотографий, представляющих широкий спектр сцен и стилей. Каждое изображение сначала стандартизируется: его изменяют по размеру, слегка обрезают, а затем увеличивают набор данных с помощью отражений, небольших вращений, изменений яркости и удаления шума, чтобы модель видела множество реалистичных вариантов. После этой подготовки Vision Transformer делит изображение на маленькие патчи и учится понимать, как разные части кадра соотносятся друг с другом в масштабе всего изображения. 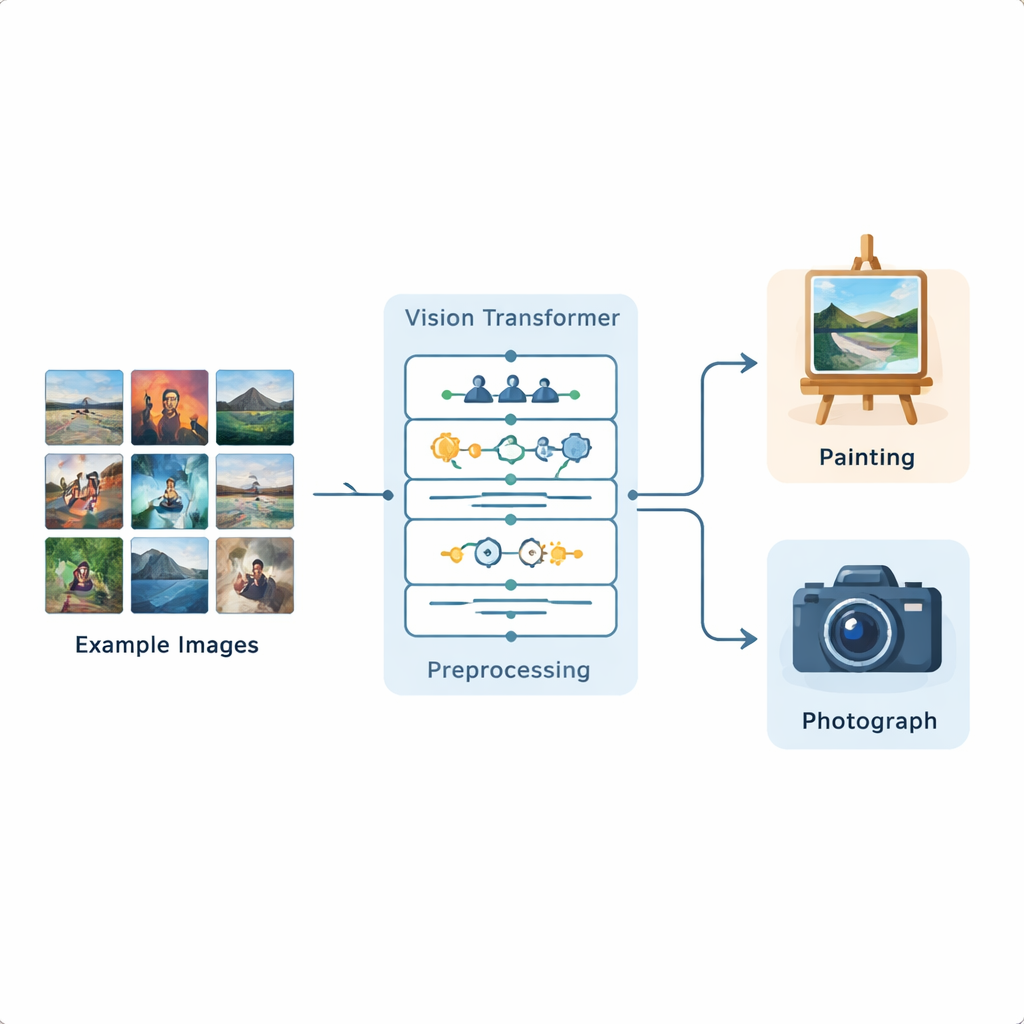
Как модель фокусируется на нужных деталях
В отличие от ранних нейросетей, которые в основном смотрели на локальные шаблоны, Vision Transformer использует механизм «внимания», чтобы решить, какие части изображения наиболее важны для конкретной задачи. Он фактически спрашивает для каждого патча, с какой силой стоит обращать внимание на каждый другой патч. Это улучшает обнаружение глобальной структуры: как цвета переходят по полотну, как свет ложится на сцену или как повторяются текстуры. Чтобы убедиться, что модель не делает случайных предположений, авторы также применяют метод визуализации Grad-CAM, который подсвечивает конкретные области, повлиявшие на решение. Для картин эти подсветки обычно попадают на текстуры мазков и стилизованные участки; для фотографий — вокруг тонких краёв, реалистичных поверхностей и переходов освещения. 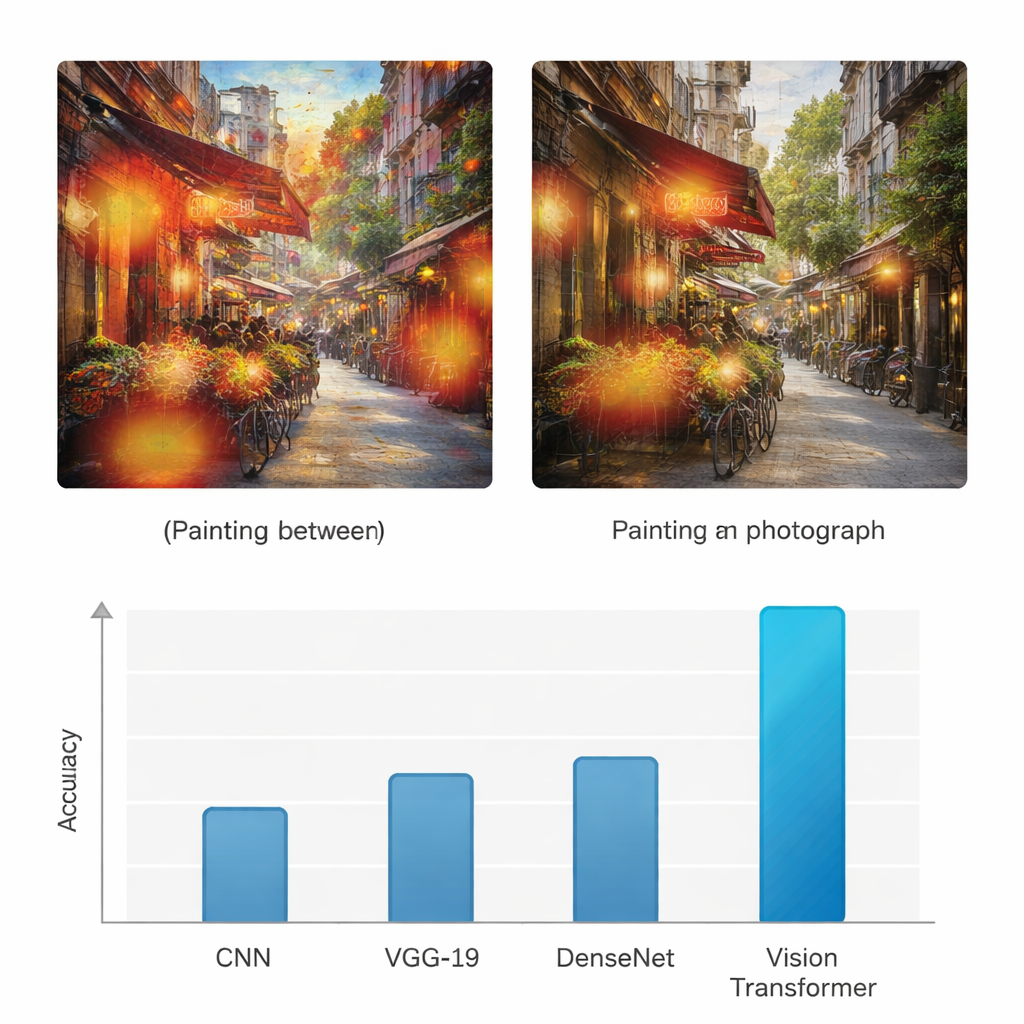
Превосходство над ранними методами распознавания изображений
Чтобы проверить, действительно ли этот подход добавляет ценность, исследование сравнивает Vision Transformer с тремя широко используемыми архитектурами глубокого обучения: стандартной сверточной нейронной сетью (CNN), сетью VGG-19 и DenseNet. Все модели обучались и тестировались на одном и том же наборе данных и оценивались с помощью распространённых метрик: точности, precision, recall и F1‑score, которые учитывают верные срабатывания и ошибки для обоих классов. В то время как базовые сети достигают точности в районе 70–80%, Vision Transformer показывает 95% точности как для картин, так и для фотографий, с аналогично высокими значениями precision и recall. Авторы также проводят несколько статистических тестов, чтобы подтвердить, что это улучшение не случайно, демонстрируя, что модель на базе трансформера стабильно лучше при повторных испытаниях и разных критериях оценки.
Что это значит для искусства, доверия и технологий
Результаты указывают на то, что современные трансформерные модели могут служить мощными и объяснимыми инструментами для разделения картин и фотографий, а также для выявления ИИ‑сгенерированных изображений, имитирующих любое из медиа. Для неспециалистов основной вывод в том, что компьютеры теперь способны обнаруживать тонкие признаки — такие как мазки кисти, гладкость или градиенты освещения — которые даже внимательные человеческие наблюдатели могут не заметить, и делать это в масштабе. Такие системы могут помочь галереям и коллекционерам проверять работы, ассистировать кураторам и архивариусам в организации больших цифровых коллекций и поддерживать онлайн‑платформы при маркировке или фильтрации синтетического контента. По мере того как генераторы изображений продолжают стирать грань между реальностью и вымыслом, методы, подобные представленному, предлагают практический способ сохранять доверие к тому, что мы видим.
Цитирование: Yu, L. Visual perception based deep learning transformers for classifying paintings and photographs through feature extraction. Sci Rep 16, 5326 (2026). https://doi.org/10.1038/s41598-026-36298-4
Ключевые слова: изображения, сгенерированные ИИ, аутентификация искусства, классификация изображений, vision transformer, анализ цифрового искусства