Clear Sky Science · ru
ADAT: новая архитектура адаптивного трансформера с учётом временных рядов для перевода жестового языка
Преодоление коммуникационного разрыва
Для миллионов глухих и слабослышащих людей повседневные задачи, такие как визит к врачу или просмотр прогноза погоды, могут быть сложнее, чем должны, просто потому что квалифицированных переводчиков жестового языка мало. В этой статье представлена новая система искусственного интеллекта под названием ADAT, которая преобразует видео с жестами в письменные предложения точнее и эффективнее многих существующих систем, приближая нас к переводу жестового языка в реальном времени на телефонах, планшетах и в больничных компьютерах.
Почему жестовый язык сложен для компьютеров
Жестовые языки богаты и сложны, у них своя грамматика, и смысл зависит не только от движений рук. Выражение лица, поза тела и тонкие временные нюансы меняют значение предложения, выполненного жестами. Современные системы перевода часто используют мощную архитектуру ИИ, известную как трансформер, которая отлично справляется с длинными предложениями в устной или письменной речи. Но при работе с видео высокой частоты — 30–60 кадров в секунду — такие системы могут замедляться и упускать быстрые, тонкие движения, которые различают один знак от другого. Им также требуется много вычислительных ресурсов и времени на обучение, что затрудняет их обновление по мере эволюции жестовых языков.
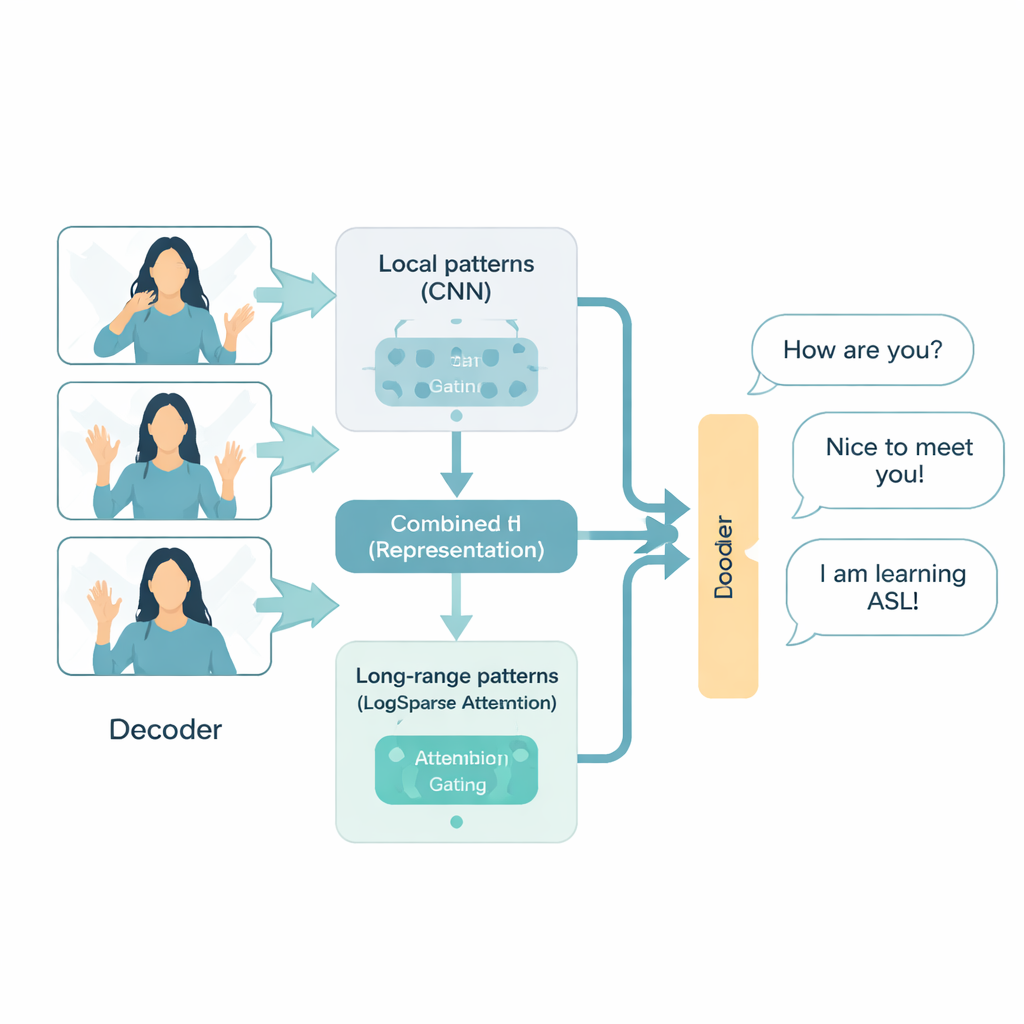
Более умный способ «читать» жесты
Архитектура ADAT специально разработана для видеозаписей жестового языка, рассматривая их как временной ряд — быстрый поток визуальных событий, разворачивающихся во времени. Она сочетает три идеи. Во‑первых, используются сверточные нейронные сети — проверенный метод для изображений — чтобы фокусироваться на локальных паттернах, таких как форма руки и мимика. Во‑вторых, применяется более эффективная форма внимания, которая избирательно обращается к ключевым моментам в видео, а не сравнивает каждый кадр со всеми остальными. В‑третьих, адаптивный «затвор» (gate) обучается смешивать детальную краткосрочную информацию с более широким долгосрочным контекстом, решая в реальном времени, что важнее для каждой части предложения. Вместе эти компоненты позволяют ADAT улавливать и быстрый взмах пальца, и общую структуру разговора, не тратя лишних вычислительных ресурсов.
От жестов к словам двумя путями
Перевод жестового языка можно организовать двумя основными способами: сначала распознавать базовые единицы жеста, так называемые глоссы, а затем преобразовывать эти глоссы в устной или письменный текст — это называется sign-to-gloss-to-text. Альтернативно, система может пытаться сразу перейти от видео к тексту за один шаг, что называется sign-to-text. Авторы тестируют ADAT в обоих подходах. Они сравнивают его с несколькими сильными трансформерными базовыми моделями, включая хорошо известную систему SLTUNET, на трёх наборах данных: большом немецком корпусе прогнозов погоды, коллекции индийского жестового языка и новом медицинском датасете американского жестового языка, созданном авторами для отражения реалистичных разговоров врача и пациента.
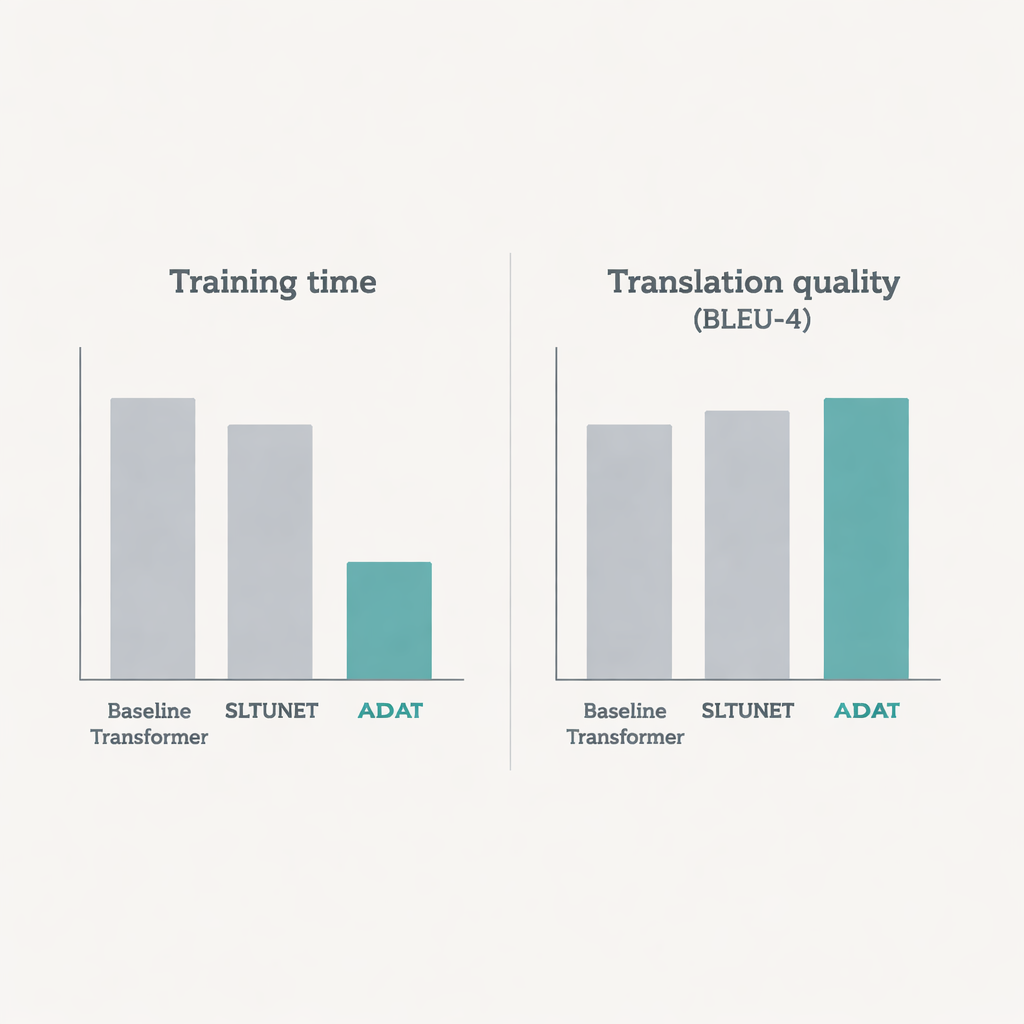
Быстрее обучение и более точный перевод
Во всех тестах ADAT либо соответствует, либо превосходит лучшие конкурирующие модели по качеству перевода, измеряемому стандартными BLEU‑метриками, при заметно более быстром обучении. В двухэтапной схеме sign-to-gloss-to-text он даёт сопоставимые или немного лучшие результаты по сравнению с классическим трансформером, при этом сокращая время обучения примерно на одну пятую в среднем. В более сложной задаче прямого sign-to-text ADAT явно опережает базовые трансформеры типа encoder-only, decoder-only и unified, часто повышая точность примерно на один процентный пункт или более, опять же с примерно 20% ускорением обучения. Детальный анализ математической части показывает, что более избирательное внимание и двухпутевая конструкция ADAT значительно сокращают количество необходимых операций, особенно при обработке длинных или высокочастотных видео.
Новые данные для критически важных разговоров
Чтобы убедиться, что эти методы применимы за пределами лабораторий, авторы представляют MedASL — первый датасет американского жестового языка, ориентированный на медицинскую коммуникацию. Он состоит из 500 уникальных, тщательно продуманных предложений, имитирующих реальные взаимодействия пациентов и медицинских работников, и включает как глоссовые, так и текстовые аннотации. Медицинская направленность важна, поскольку недопонимания в больнице или клинике могут иметь серьёзные последствия, а существующие датасеты редко охватывают эту область. ADAT показывает сильные результаты на MedASL, хотя полученные данные также демонстрируют, насколько сложно любой системе полностью обобщать на новые реальные предложения.
Что это означает для повседневной жизни
Проще говоря, исследование показывает, что мы можем создавать системы перевода жестового языка, которые одновременно умнее и эффективнее: им требуется меньше времени и вычислительной мощности для обучения, при этом они лучше улавливают тонкости жестовой речи. ADAT ещё не является универсальным «включи-и-пользуйся» переводчиком для всех жестовых языков и ситуаций и по-прежнему уступает системам, основанным на огромных предварительно обученных моделях. Но, сосредоточившись на временных паттернах видео и эффективности, он указывает путь к практичным инструментам, которые однажды смогут работать на обычных устройствах, поддерживать несколько жестовых языков и помогать глухим пользователям проще общаться в критических сферах, таких как здравоохранение, экстренные службы и публичные услуги.
Цитирование: Shahin, N., Ismail, L. ADAT novel time-series-aware adaptive transformer architecture for sign language translation. Sci Rep 16, 6551 (2026). https://doi.org/10.1038/s41598-026-36293-9
Ключевые слова: перевод жестового языка, адаптивный трансформер, внимание для временных рядов, медицинский ASL, доступный ИИ