Clear Sky Science · ru
Мета-обучение для распознавания открытых задач с немногими примерами
Почему важно учить ИИ на очень небольшом количестве примеров
Современные системы ИИ умеют с впечатляющей точностью распознавать лица, животных и бытовые предметы — но обычно лишь после просмотра миллионов размеченных изображений. В реальных ситуациях, например при диагностике редкого заболевания или обнаружении нового типа дефекта на производственной линии, таких данных часто нет. В этой статье исследуют, как обучать модели ИИ решать новые визуальные задачи по нескольким примерам, даже если эти задачи сильно отличаются от тех, на которых модель обучалась. Авторы предлагают метод под названием Open-MAML, цель которого сделать такое гибкое обучение на малых данных более надёжным и предсказуемым.
От фиксированных упражнений к открытым «внезапным» проверкам
Большая часть исследований по «few-shot learning» оценивает системы ИИ в строго контролируемых условиях. Модель обучают и тестируют на очень похожих задачах — например, всегда требуется отличать ровно пять категорий (так называемый «5-way») при одном примере на категорию («1-shot»). Это похоже на отработку учеником только пятивопросного теста с одним практическим примером каждого типа вопроса. В реальности всё намного запутаннее: число категорий может меняться, и объём размеченных данных для каждой из них со временем растёт или уменьшается. Авторы называют такую более реалистичную ситуацию открытой постановкой задачи (open-task setting), где модели должны справляться с задачами, имеющими иную численность классов и объём примеров, чем при обучении. 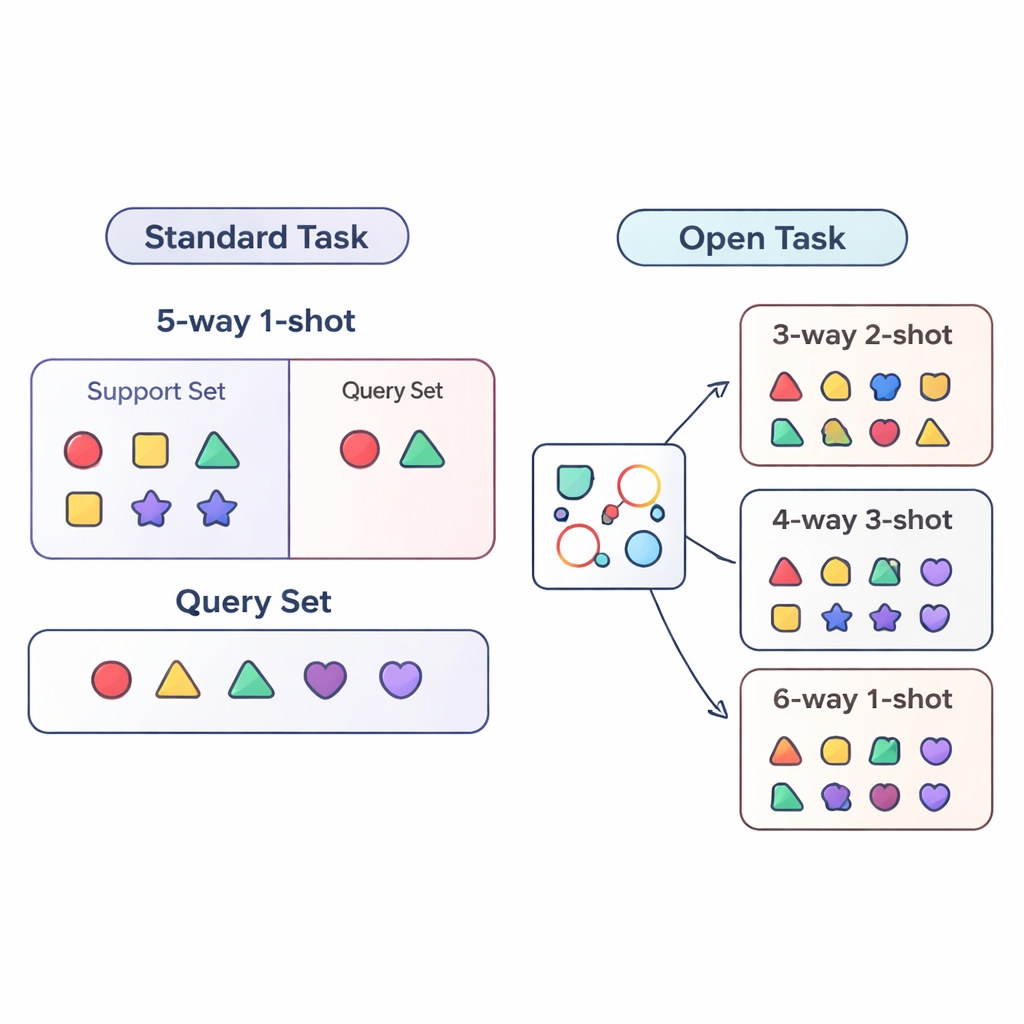
Переосмысление способов тестирования few-shot моделей
Чтобы систематически изучить мир открытых задач, в статье предложены три режима оценки. В режиме cross-way меняется только число классов: модель может обучаться на пяти классах, но тестироваться на трёх или пятнадцати. В режиме cross-shot варьируется число примеров на класс — от одного размеченного изображения до нескольких. Самый сложный случай — cross-way–cross-shot, когда одновременно изменяются и число классов, и объём данных на класс. Авторы также исследуют, что происходит при смещении визуального стиля данных: обучение на общем датасете объектов и тестирование на тонкодифференцированном наборе птиц. Эти сценарии призваны показать, действительно ли метод может обобщать за пределы единого, фиксированного рецепта обучения.
Как Open-MAML адаптируется на ходу
Open-MAML развивает популярную мета-обучающую стратегию Model-Agnostic Meta-Learning (MAML), которая тренирует модель так, чтобы она могла быстро адаптироваться к новой задаче за несколько градиентных шагов. Стандартный MAML, однако, предполагает, что число категорий на этапе тестирования совпадает с тем, что было при обучении, и использует фиксированный финальный классификационный слой. Open-MAML вносит три ключевых изменения, чтобы снять это ограничение. Во-первых, он применяет динамическое построение классификатора: при появлении новой задачи с большим числом классов создаются дополнительные выходные единицы путём копирования среднего значения существующих, что даёт модели нейтральную, но разумную стартовую инициализацию. Во-вторых, он корректирует внутреннюю скорость обучения в зависимости от числа классов и примеров в задаче, чтобы адаптация оставалась стабильной как при дефиците данных, так и при их избытке. В-третьих, вводится регуляризатор под названием AdaDropBlock, который временно скрывает смежные области в картах признаков во время обучения, побуждая модель опираться на более разнообразные визуальные подсказки вместо переобучения на маленьких, хрупких деталях. 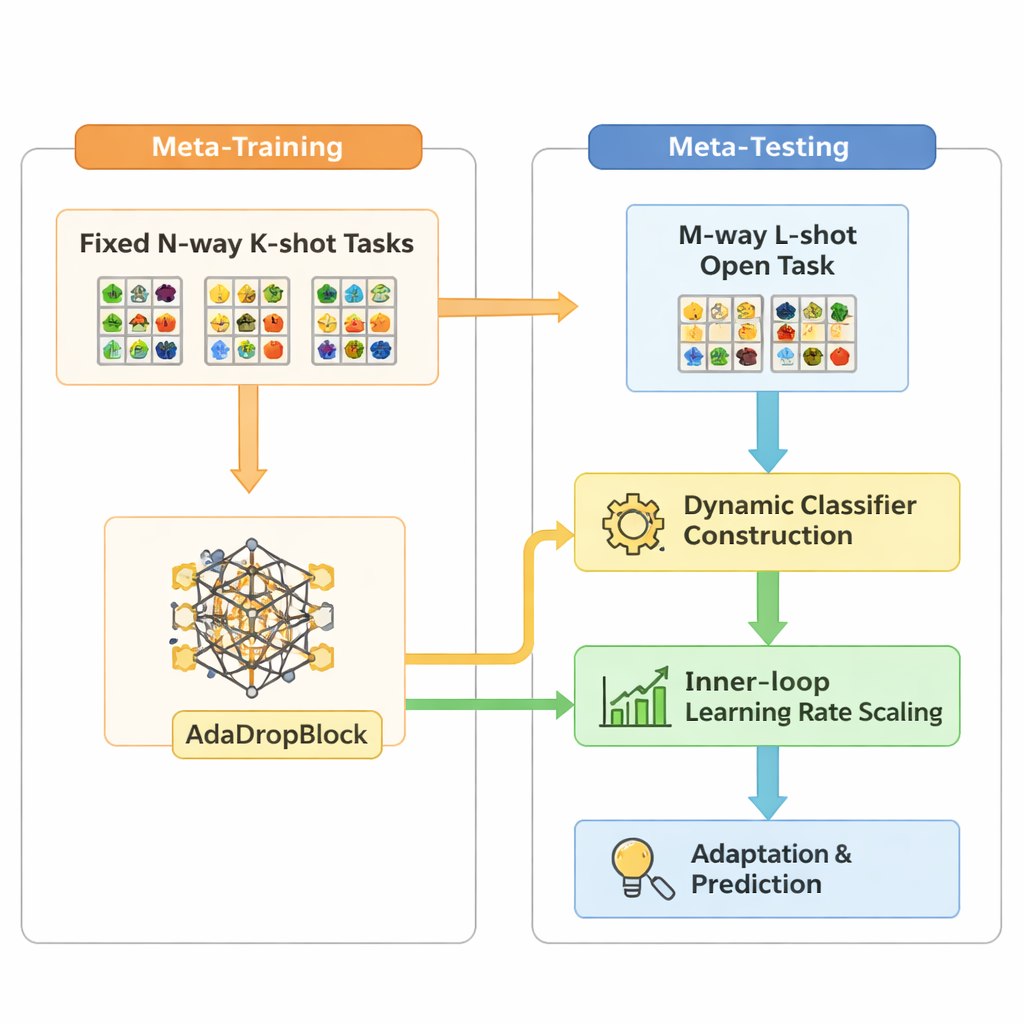
Проверка гибкого обучения на практике
Исследователи оценили Open-MAML на стандартных бенчмарках few-shot и в новых сценариях open-task, сравнив его с несколькими известными базовыми подходами. Среди них — модели, обучаемые с нуля для каждой задачи, модели с мощным предобученным экстрактором признаков и дообучаемым классификатором, а также метрические методы, классифицирующие изображения по расстоянию до «прототипов» классов. Все методы используют одну и ту же базовую сеть, чтобы различия зависели от стратегии обучения, а не архитектуры. На десятках тысяч тестовых задач Open-MAML стабильно показывает более высокую точность — обычно на 1–7 процентных пунктов лучше, когда меняется только число классов или примеров, и на 3–6 пунктов лучше, когда меняются оба параметра одновременно. Преимущества особенно заметны в более сложных сценариях с большим числом классов, большим количеством снимков на класс или при переносе на датасет птиц, что говорит о том, что механизмы адаптации действительно помогают в сложной незнакомой среде.
Что это значит для реальных систем ИИ
Для неспециалистского читателя главное вывод: не все few-shot подходы равнозначны, как только мы выходим за пределы удобной лабораторной среды. Метод, который отлично работает на одном фиксированном бенчмарке, может дать сбой, если число категорий или объём размеченных данных изменится. Open-MAML показывает, что при явной подготовке к таким структурным изменениям — позволяя классификатору расширяться или сжиматься, масштабируя скорость обучения в зависимости от размера задачи и регуляризируя признаки независимым от задачи способом — системы ИИ лучше справляются с изменяющимися условиями на практике. В областях вроде медицинской визуализации, спутникового мониторинга или промышленного контроля качества, где и набор категорий, и доступность меток постоянно меняются, такая устойчивость к открытым задачам может сделать обучение на малых данных значительно более применимым за пределами тщательно подобранных исследовательских бенчмарков.
Цитирование: Han, X., Shi, D., Wang, Z. et al. Meta-learning for few-shot open task recognition. Sci Rep 16, 5624 (2026). https://doi.org/10.1038/s41598-026-36291-x
Ключевые слова: обучение с немногими примерами, мета-обучение, распознавание открытых задач, классификация изображений, обобщение