Clear Sky Science · ru
Диалектная замена как атакующий подход для оценки устойчивости NLP на арабском
Почему повседневный арабский сбивает с толку умные компьютеры
Сегодня многие приложения читают арабский текст, чтобы определить настроение, сортировать новости или отвечать на вопросы. Тем не менее эти системы в основном обучаются на современном стандартном арабском (MSA), тогда как люди ежедневно смешивают региональные диалекты. В статье показано, как замена всего одного слова на египетский или заливной диалект может обмануть передовые языковые модели, что вызывает обеспокоенность у тех, кто полагается на арабский ИИ в службах поддержки, мониторинге медиа или обеспечении безопасности в интернете.
Один язык — много голосов
Арабский не является единым однородным способом говорения. MSA используется в школах, новостях и официальных текстах, но в повседневных беседах доминируют диалекты, такие как египетский и заливной арабский. Эти варианты отличаются словарём, формами слов и даже синтаксисом. Например, простое слово «сейчас» принимает очень разные формы в разных регионах. Для человеческих читателей такие вариации естественны и легко понимаются. Для компьютерных моделей, натренированных почти исключительно на MSA, диалектные слова могут выглядеть незнакомыми, превращая понятное предложение в нечто странное.
Превращение диалектов в стресс-тест для ИИ
Чтобы проверить, насколько хрупки арабские языковые модели, автор разрабатывает простой двухэтапный тест. Сначала модель многократно запрашивают, чтобы выявить одно слово в предложении, которое наиболее влияет на её решение — часто сильное прилагательное, ключевой глагол или тематическое существительное. Затем это слово заменяют на эквивалент из египетского или заливного арабского с помощью большой, тщательно донастроенной «диалектайзер»-модели. Остальная часть предложения остаётся без изменений, и для человеческого читателя смысл сохраняется. Это превращает изменённое предложение в реалистичный адверсариальный пример: небольшая, естественно выглядящая правка, созданная, чтобы ввести систему в заблуждение, не меняя исходного сообщения.
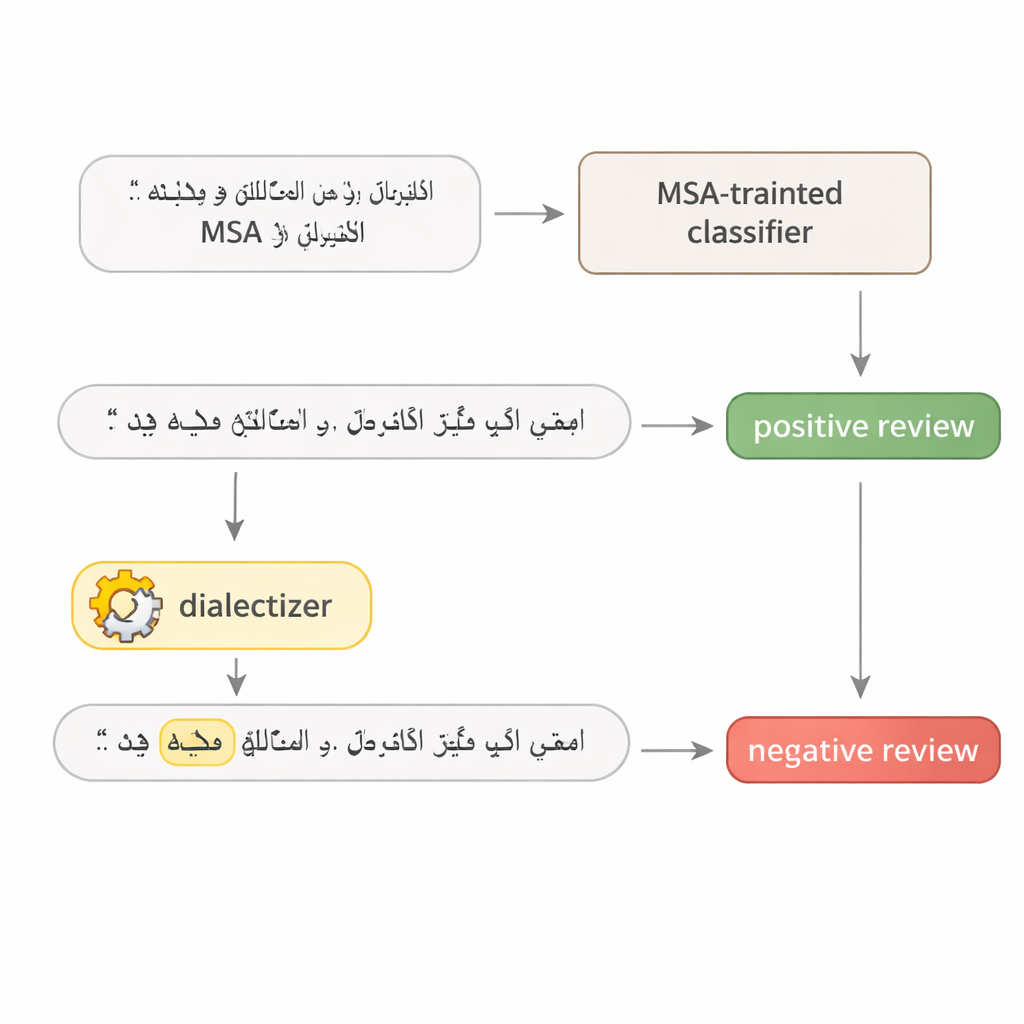
Испытание отзывов об отелях и новостных материалов
Исследование атакует четыре известные модели глубокого обучения: две большие трансформерные модели (AraBERT и CAMeLBERT) и две более простые сети (сверточная модель и двунаправленный LSTM). Их обучают на двух крупных наборах данных на MSA: отзывах об отелях для анализа настроений и новостных статьях для классификации тем. Из каждого тестового набора автор выбирает 1 280 примеров и применяет процедуру диалектной замены. Хотя в каждом предложении изменяется только одно слово, эффект поражает. Для отзывов об отелях точность AraBERT падает с 94 процентов на чистом тексте до примерно 72 процентов при заливных подстановках и до 65 процентов при египетских. CAMeLBERT падает ещё сильнее — примерно до 63 и 55 процентов соответственно. Классификаторы новостей также страдают: сверточная модель теряет около 18–22 процентных пунктов, а LSTM демонстрирует похожие падения.
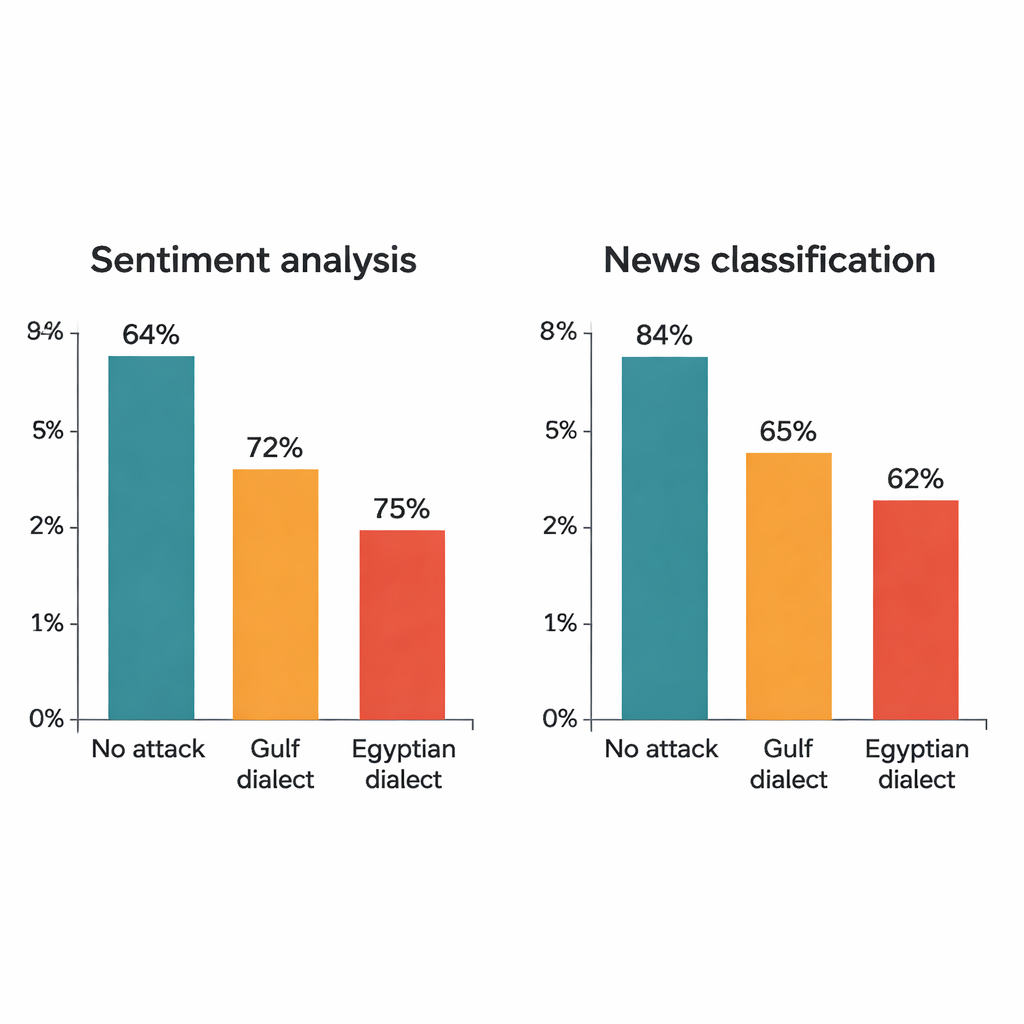
Что идёт не так внутри моделей
Более внимательный анализ показывает, что самые уязвимые слова совпадают с тем, как люди действительно читают текст. В отзывах об отелях почти половина целевых слов — прилагательные вроде «хорошо» или «ужасно», которые несут явную эмоциональную нагрузку. В новостных статьях большинство выбранных слов — существительные и имена, сигнализирующие о темах вроде политики, спорта или финансов. Когда эти ключевые слова заменяются диалектными формами, модели, обученные только на MSA, часто не распознают их. Трансформеры оказываются особенно хрупкими: их зависимость от субсловных фрагментов и внимание к нескольким сильно взвешенным токенам делает одно диалектное слово достаточным, чтобы перевернуть предсказание. Более простые модели, распределяющие внимание равномернее по предложению, тоже обманываются, но демонстрируют некоторую большую устойчивость.
Египетский против заливного: не все диалекты одинаковы
Атаки также показывают, что египетский арабский чаще выводит модели из строя, чем заливной. Лингвистические исследования подтверждают это: заливные варианты часто ближе к MSA по словарю и структуре, в то время как египетский арабский усвоил больше отличительных форм под влиянием истории и контактов с другими языками. В результате заливные подстановки иногда достаточно похожи на исходный MSA, чтобы модель могла с ними справиться, тогда как египетские подстановки чаще выходят за пределы того, что модель видела ранее. Статистические тесты подтверждают, что наблюдаемые падения производительности не случайны — они отражают систематические слепые зоны в том, как современные системы работают с арабской диглоссией.
Что это значит для арабского ИИ
Для повседневных пользователей вывод прост: современный арабский ИИ легко сбить с толку обычными диалектными словами, даже если людям текст кажется полностью ясным. Одно диалектное слово в отзыве об отеле может поменять оценку модели с положительной на отрицательную или неверно обозначить тему новостной статьи. Для исследователей и разработчиков послание — призыв создавать «диглоссически-осведомлённые» системы, обученные как на MSA, так и на региональных диалектах, и использовать реалистичные стресс-тесты вроде диалектной замены при оценке устойчивости. До тех пор любое приложение, которое предполагает, что «арабский — это только MSA», рискует серьёзными недопониманиями в реальной среде.
Цитирование: Alshemali, B. Dialectal substitution as an adversarial approach for evaluating Arabic NLP robustness. Sci Rep 16, 5996 (2026). https://doi.org/10.1038/s41598-026-36252-4
Ключевые слова: Обработка естественного языка на арабском, диалектные вариации, адверсариальные примеры, анализ настроений, классификация текста