Clear Sky Science · ru
Моделирование контекста на дальнем расстоянии для обнаружения уязвимостей в ПО с использованием подхода на основе XLNet
Почему скрытые ошибки в ПО имеют значение
Современная жизнь работает на программном обеспечении: от онлайн-банкинга и больничных систем до видеоплееров и чат-приложений. Даже крошечные ошибки в коде могут открыть дверь злоумышленникам, ставя под угрозу кражу данных или отказ в обслуживании. Эксперты по безопасности всё чаще обращаются к искусственному интеллекту, чтобы просканировать миллионы строк кода в поисках таких слабых мест. В этой статье рассматривается новый метод на основе ИИ, названный XLNetVD, который разработан для выявления тонких уязвимостей, читая значительно большие фрагменты кода, чем многие существующие инструменты.
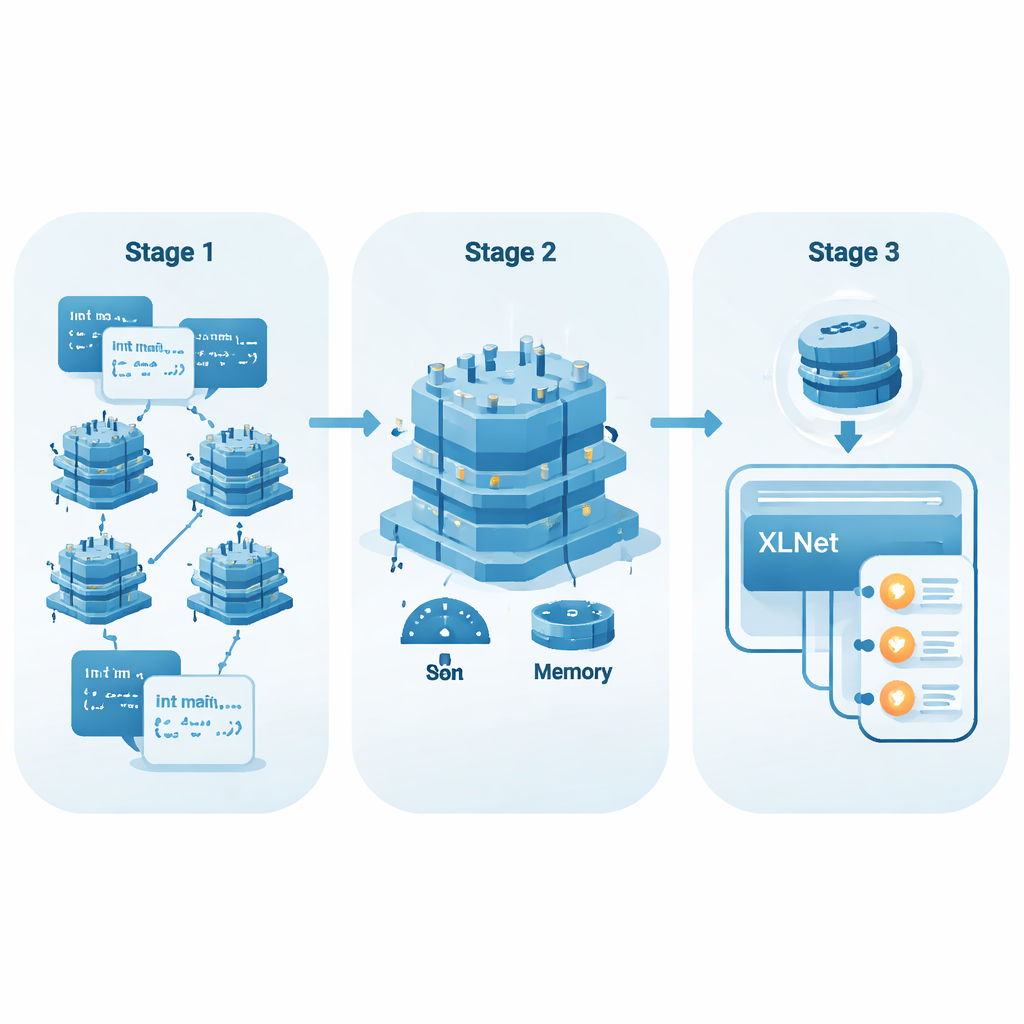
От простых словарей к коду, понимающему контекст
Ранние методы ИИ для анализа кода рассматривали каждый токен — например, имя переменной или символ — почти как слово из словаря с фиксированным значением. Подходы вроде Word2Vec или GloVe обучали по одному вектору на токен, независимо от контекста его появления. Для естественного языка это работает достаточно хорошо, но для программ это бывает недостаточно: одно и то же имя переменной может вести себя совсем по‑разному в зависимости от того, где и как оно используется. Новые модели, известные как контекстные встраивания (contextual embeddings), анализируют всю функцию целиком и корректируют представление каждого токена в зависимости от окружения. Это позволяет уловить шаблоны, связанные с потоками данных, управлением потоком и зависимостями между переменными — шаблоны, которые зачастую определяют разницу между безопасным и опасным кодом.
Позволяя ИИ читать больше файла
Популярные модели для кода, такие как CodeBERT и GraphCodeBERT, уже используют этот подход с учётом контекста, но обычно ограничивают «поле зрения» примерно до 512 токенов. Для длинных функций или уязвимостей, которые намечаются в широко разделённых частях кода, этого окна может не хватать. Важные проверки в начале функции могут быть отрезаны от рискованных операций в конце. Авторы строят свою работу на XLNet, модели на базе Transformer-XL, которая способна сохранять информацию между сегментами и комфортно обрабатывать более длинные последовательности (до 768 токенов в их экспериментах). Это делает её лучше приспособленной для связывания разнесённых событий в коде — например, для понимания того, что значение было проверено ранее, или для осознания того, что проверка вообще не выполнялась.
Делаем мощные модели легче и быстрее
Крупные модели ИИ часто требуют мощного оборудования, что ограничивает их применение в повседневных средах разработки. Чтобы решить эту проблему, авторы применяют метод донастройки Low-Rank Adaptation (LoRA). Вместо изменения всех многочисленных параметров XLNet, LoRA добавляет небольшие адаптерные слои, которые гораздо дешевле в обучении и хранении. Команда вводит простой показатель EffScore, который взвешивает, сколько памяти и времени экономится против возможного падения качества обнаружения. По результатам нескольких ведущих моделей, XLNet с LoRA оказывается наиболее эффективным в целом, предлагая высокую точность при существенно меньших затратах ресурсов.
Тестирование на реальных и синтетических проектах
Исследователи оценивают XLNetVD на двух очень различных наборах данных. Один состоит из реального C‑кода из 12 открытых проектов — таких как мультимедийные библиотеки и веб‑серверы — с крайне смещённым соотношением примерно 1 уязвимая функция на 65 неуязвимых, что отражает реальность крупных кодовых баз. Другой набор — сбалансированная синтетическая коллекция из проекта SARD, где каждая функция создана так, чтобы представлять известный тип уязвимости. XLNetVD не только сравним или превосходит предыдущие системы глубокого обучения и классические инструменты статического анализа по этим тестам, но и хорошо проявляет себя в условиях кросс‑проектного тестирования, когда модель должна находить ошибки в проекте, которого не видела ранее. Его преимущество особенно заметно для длинных функций, где важен расширенный контекст, а также по ряду категорий уязвимостей, включая переполнение целых чисел, неправильное управление ресурсами и некорректную обработку ввода.
Что это означает для повседневной безопасности ПО
Для неспециалиста главный вывод таков: более умный, учитывающий контекст ИИ может читать и анализировать код ближе к тому, как это делает опытный человек‑ревьюер, но в масштабах машинной проверки. Позволяя модели видеть больше каждой функции и настраивая её эффективно, XLNetVD предлагает практический способ приоритизировать участки огромной кодовой базы, которые требуют более внимательной проверки человеком. Он не заменяет ручные аудиты безопасности или формальные методы и не может гарантировать отсутствие ошибок в ПО. Тем не менее он значительно повышает шансы обнаружить опасные ошибки на ранних стадиях, даже в незнакомых проектах, делая его перспективным компонентом для более надёжной и безопасной цифровой инфраструктуры.
Цитирование: Zhao, Y., Lin, G. & Liao, Z. Long-range context modeling for software vulnerability detection using an XLNet-based approach. Sci Rep 16, 5338 (2026). https://doi.org/10.1038/s41598-026-36196-9
Ключевые слова: уязвимости программного обеспечения, безопасность кода, глубокое обучение, XLNet, донастройка LoRA