Clear Sky Science · ru
Модифицированный приоритетный алгоритм DDPG для совместной оптимизации формирования луча и фаз RIS в MISO нисходящих системах
Умные поверхности для следующего поколения беспроводных сетей
По мере того как наши телефоны, автомобили и датчики требуют всё более быстрых и надёжных подключений, современные беспроводные сети достигают пределов своих возможностей. В этой работе исследуется новый способ сделать будущие сети 6G более экологичными и надёжными, сочетая «умные» отражающие поверхности на зданиях с методом искусственного интеллекта, который самостоятельно учится направлять радиосигналы с меньшими затратами энергии.
Превращая стены в полезные зеркала для сигнала
Системы 6G будущего должны обслуживать огромное число устройств с высокими скоростями передачи данных, предельной надёжностью и очень малой задержкой. Добиться всех этих требований, опираясь только на традиционные базовые станции, означало бы значительное увеличение аппаратных средств и энергопотребления. Перенастраиваемые интеллектуальные поверхности (RIS) предлагают альтернативу: панели, покрытые множеством крошечных, низкопотребляющих элементов, которые могут отражать входящие радиоволны в заданных направлениях, подобно программируемому зеркалу. Корректно выбирая фазы этих отражений, RIS может перенаправлять сигналы вокруг препятствий, усиливать слабые каналы и снижать помехи, не передавая при этом собственную энергию. Это даёт проектировщикам сетей новый мощный рычаг для расширения покрытия и повышения энергоэффективности.
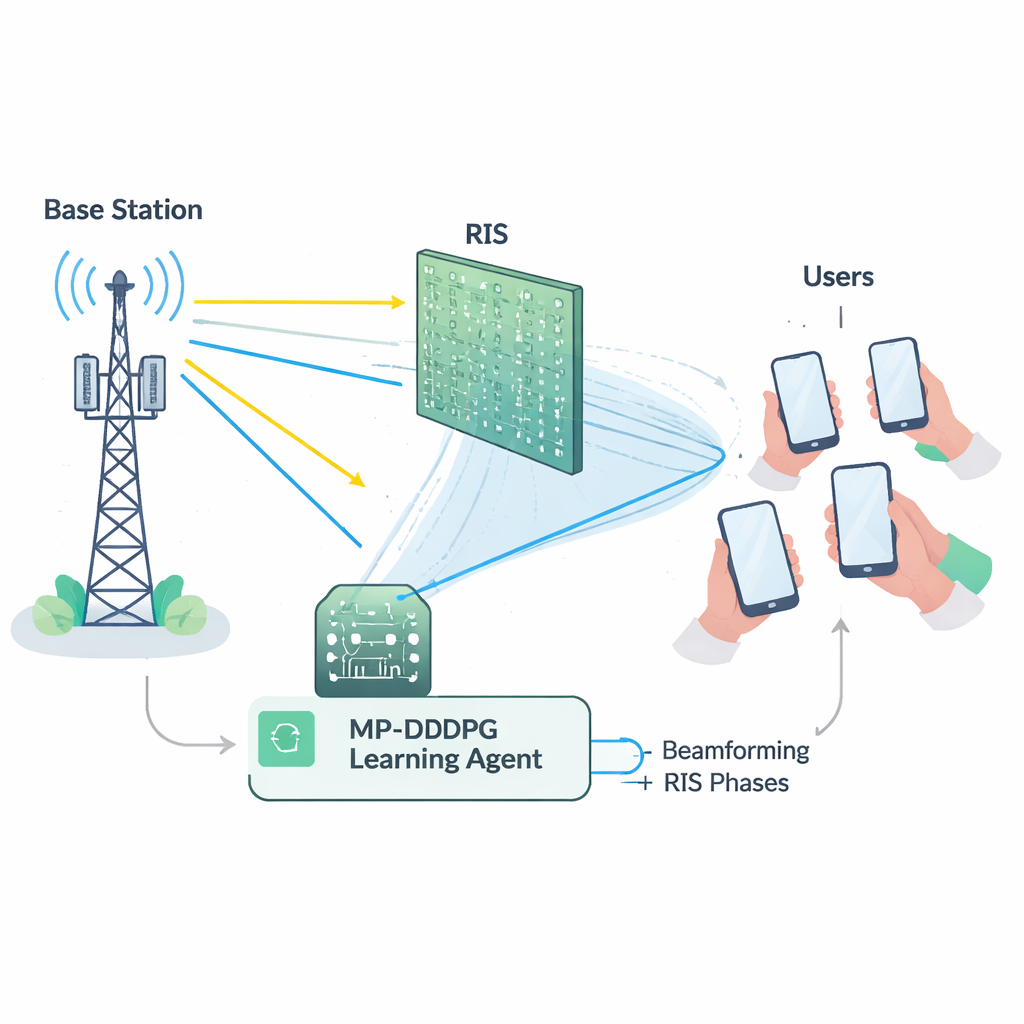
Сложный баланс для сети
Эффективное использование RIS далёко не тривиально. Базовая станция должна решить, как нацелить свои антенны (формирование луча), в то время как RIS должен установить фазу каждого из множества своих отражающих элементов. Эти решения тесно взаимосвязаны и одновременно должны удовлетворять нескольким ограничениям: держать суммарную мощность передачи ниже максимума, гарантировать каждому пользователю минимальное качество сигнала и соблюдать физические ограничения аппаратуры RIS. С математической точки зрения задача совместной настройки является сильно нелинейной и «невыпуклой», что означает, что традиционные методы оптимизации часто оказываются медленными, уязвимыми или застряют в субоптимальных решениях, особенно по мере увеличения размеров сети. Более того, точное измерение состояния каждого радиоканала (так называемая информация о состоянии канала) само по себе дорого и подвержено ошибкам в реальных развертываниях.
Позволяя агенту ИИ учиться формировать луч
Чтобы преодолеть эти трудности, авторы создают обучающего агента на базе глубокого обучения с подкреплением — ветви ИИ, в которой агент через пробу и ошибку осваивает хорошие стратегии взаимодействия со средой. Их метод, называемый Модифицированный Приоритетный Алгоритм Deep Deterministic Policy Gradient (MP‑DDPG), наблюдает за текущим состоянием сети — предыдущими направлениями лучей, настройками RIS, принятой мощностью и качеством сигнала — и затем выбирает новые значения формирования луча и фаз RIS. После каждого выбора он получает награду, которая одновременно поощряет три вещи: снижение передаваемой мощности, выполнение целевых требований по качеству обслуживания пользователей и соблюдение предела мощности базовой станции. В ходе многочисленных имитационных взаимодействий агент постепенно вырабатывает политику управления, которая уравновешивает эти цели, не опираясь на явную формулу для радиоканала.
Быстрее учиться, фокусируясь на важном
Ключевая инновация заключается в том, как алгоритм использует прошлый опыт. Стандартные подходы сохраняют множество прошлых ситуаций и выбирают их случайно при обучении, что может быть расточительным и медленным. Вместо этого MP‑DDPG назначает каждой сохранённой ситуации приоритет, зависящий как от полученной награды, так и от того, насколько её состояние отличается от ближайших соседей. Ситуации, которые одновременно информативны и разнообразны, выбираются чаще, тогда как избыточные — игнорируются. Эта «модифицированная приоритетная реплей-память» делает каждый шаг обучения более полезным, ускоряя сходение и помогая агенту избегать плохих локальных решений. Авторы также анализируют дополнительные вычислительные затраты, показав, что хотя учет приоритетов сложнее, более быстрое обучение компенсирует эти расходы на практике.
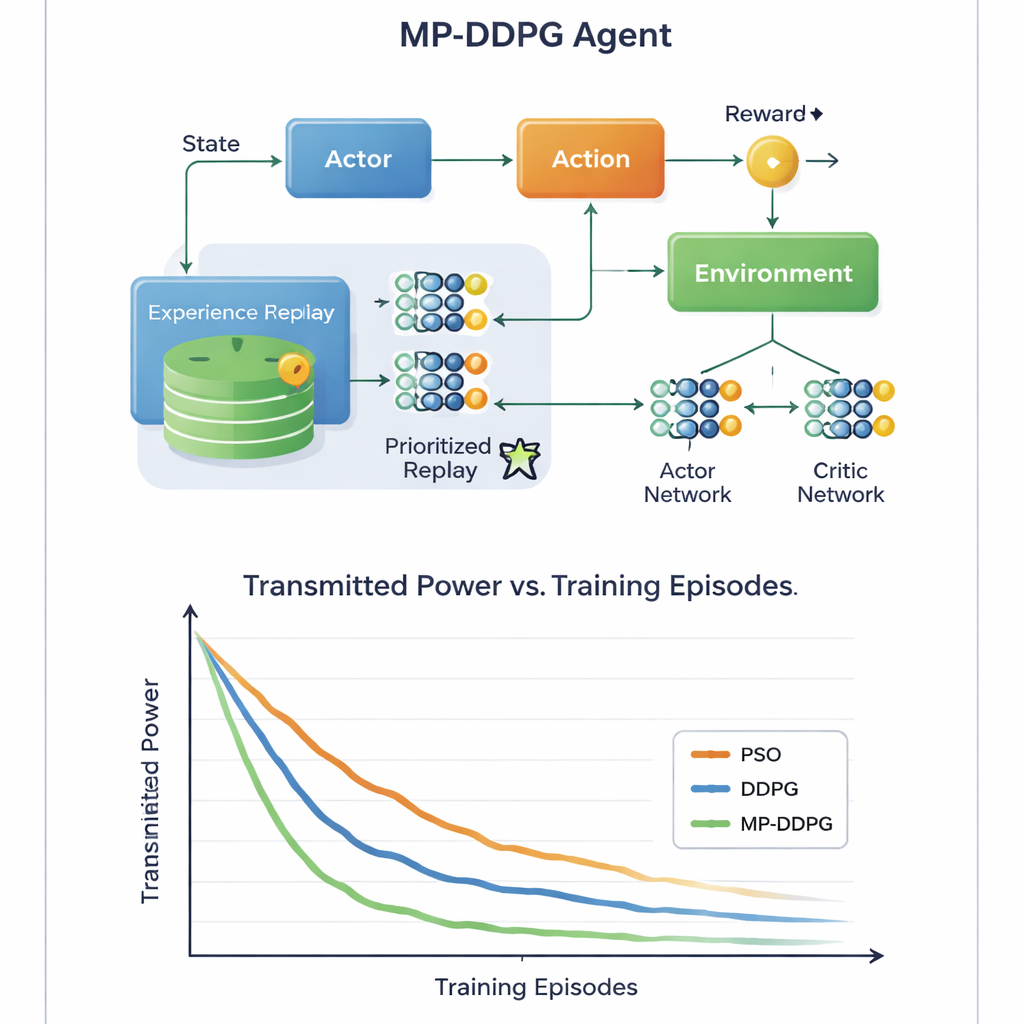
Более экологичные сигналы при меньшем количестве оборудования
Через подробные компьютерные симуляции сценария нисходящей сотовой связи исследование сравнивает MP‑DDPG с двумя альтернативами: традиционным методом оптимизации роя частиц и исходным алгоритмом DDPG. Новый метод стабильно достигает более низкой передаваемой мощности за меньшее число обучающих эпизодов и делает это, используя меньше элементов RIS и меньше антенн базовой станции при том же уровне производительности. Проще говоря, сеть учится извлекать больше пользы из каждой отражающей плитки и каждой антенны. Для неспециалиста главный вывод таков: позволяя интеллектуальному контроллеру настраивать одновременно лучи базовой станции и «умные» поверхности на соседних стенах, будущие сети 6G смогут обеспечивать мощные, надёжные сигналы, затрачивая меньше энергии и оборудования, что способствует большей устойчивости нашей всё более связанной среды.
Цитирование: Shukry, S., Fahmy, Y. Modified prioritized DDPG algorithm for joint beamforming and RIS phase optimization in MISO downlink systems. Sci Rep 16, 5942 (2026). https://doi.org/10.1038/s41598-026-36179-w
Ключевые слова: перенастраиваемая интеллектуальная поверхность, беспроводные сети 6G, глубокое обучение с подкреплением, оптимизация формирования луча, энергоэффективные сети