Clear Sky Science · ru
Прогнозирование пищевой зависимости у студентов университетов с помощью машинного обучения на основе демографических, антропометрических и личностных характеристик
Почему наши отношения с едой могут выходить из‑под контроля
Многие шутят, что «зависимы» от шоколада или фаст‑фуда, но для некоторых сильные влечения и потеря контроля при приёме пищи — серьёзная и угнетающая проблема. Студенты университетов особенно уязвимы: они сталкиваются со стрессом, новыми свободами и изменениями тела. В этом исследовании задаётся своевременный вопрос: могут ли компьютерные программы научиться выявлять студентов с повышенным риском пищевой зависимости, опираясь на простую информацию о происхождении, антропометрии и чертах личности? Если да, то в будущем мы могли бы раньше обнаруживать проблемы и подбирать поддержку прежде, чем пищевые привычки перерастут в длительные нарушения здоровья.
Изучение студентов с разных сторон
Исследователи работали с 210 студентами университета города Ахваз (Иран) в возрасте от 18 до 35 лет. Каждый студент предоставлял базовые сведения, такие как возраст и уровень образования, сообщал рост и вес для расчёта индекса массы тела (ИМТ) и заполнял стандартную шкалу личностных черт. Также использовали краткую версию Yale Food Addiction Scale, которая классифицирует наличие паттернов, похожих на зависимость от высоко привлекательной пищи — например, сильные влечения, неудачные попытки сократить потребление или еда вопреки отрицательным последствиям. Лишь 30 студентов соответствовали критериям пищевой зависимости, тогда как 180 — нет, что отражает то, что такие проблемы касаются меньшей доли населения.
Компенсация несбалансированных данных и обучение умных моделей
Поскольку число студентов, классифицированных как зависимые, было значительно меньше, набор данных оказался несбалансированным. Такое несоответствие может «обмануть» модели, заставив их в основном предсказывать преобладающую группу и игнорировать группу высокого риска. Чтобы противостоять этому, команда применила две техники обработки данных. Сначала использовали метод Tomek Links для аккуратного удаления запутанных примеров из большинства, которые находились слишком близко к примерам меньшинства. Затем применили SMOTE, создающий реалистичные синтетические примеры для группы меньшинства, чтобы выровнять числа. Изменялись только обучающие данные; отдельная нетронутая тестовая группа оставалась в стороне для проверки того, как модели работают на новых, невидимых студентах.
Испытание множества алгоритмов
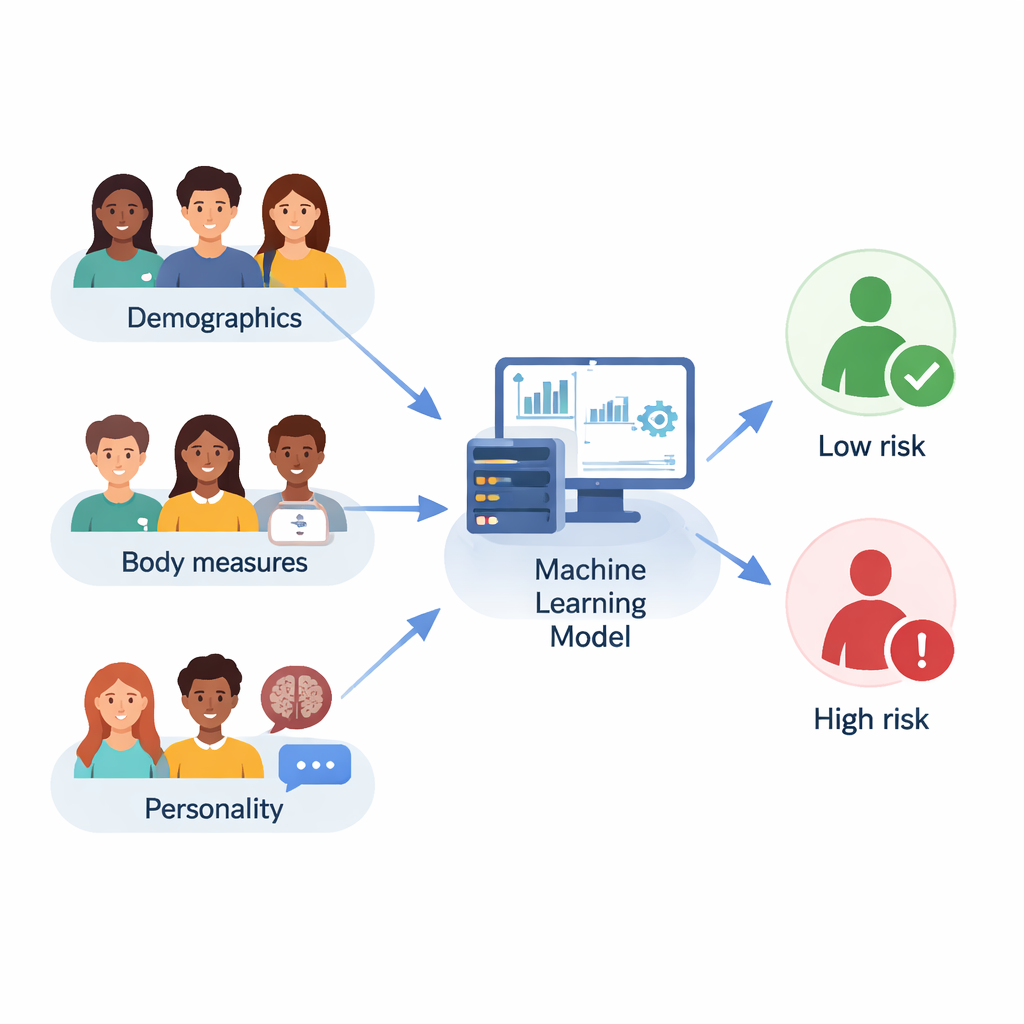
Исследователи не полагались на один математический рецепт. Вместо этого они сравнили десять разных моделей машинного обучения — от простых методов, таких как логистическая регрессия и k‑ближайших соседей, до более продвинутых ансамблевых методов, таких как Random Forest, Gradient Boosting, LightGBM и CatBoost. Также опробовали двенадцать стратегий отбора признаков, чтобы определить, какие вопросы и измерения наиболее информативны, и использовали сквозную проверку и автоматический поиск настроек для каждого алгоритма. Общую производительность оценивали с помощью нескольких метрик, включая точность (как часто модель права), F1‑метрику (баланс между обнаружением истинных случаев и числом ложных срабатываний) и площадь под ROC‑кривой, отражающую, насколько хорошо модель разделяет людей с высоким и низким риском.
Что управляет предсказаниями «под капотом»
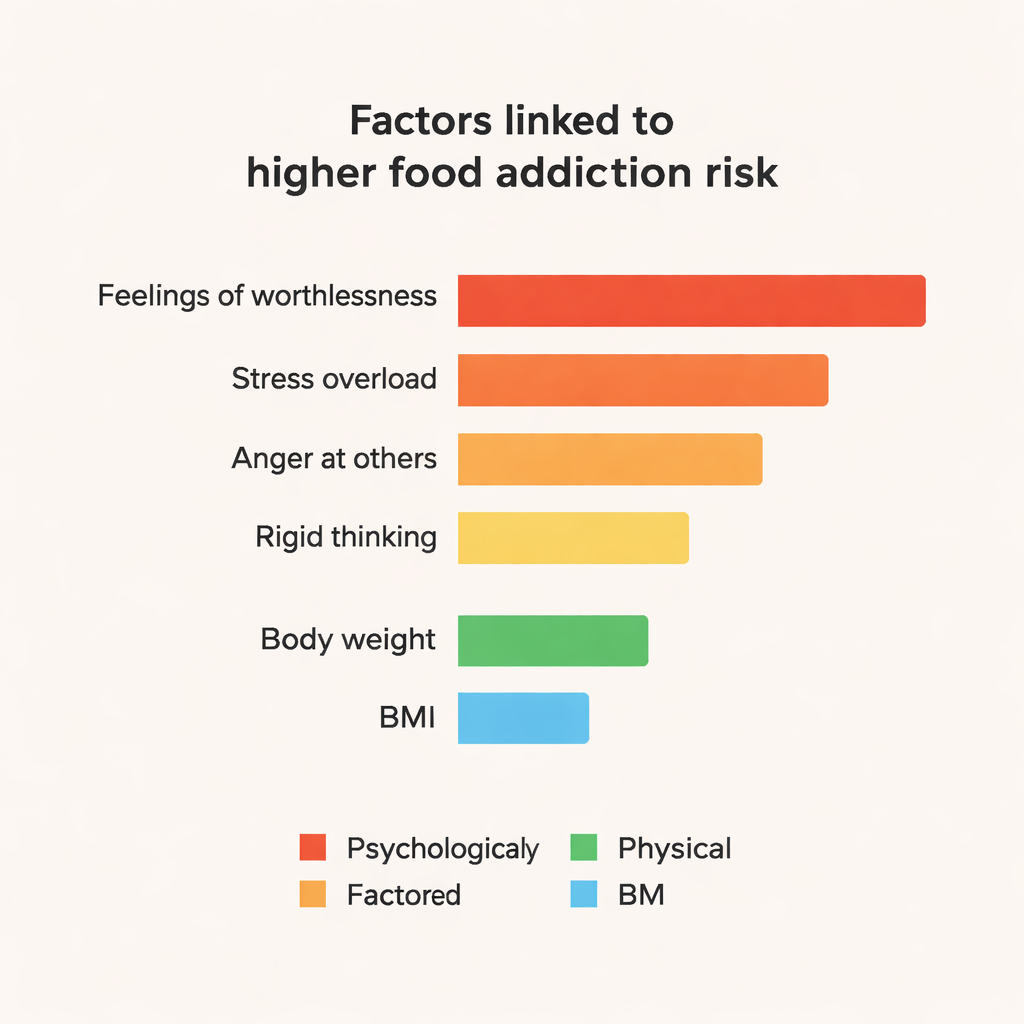
Ансамблевые модели, особенно CatBoost и Random Forest, стабильно превосходили более простые подходы, достигая примерно 84% точности и F1‑метрик около 0.84 на этом небольшом наборе данных. Чтобы выйти за пределы «чёрного ящика» предсказаний, команда использовала инструмент SHAP для анализа того, какие признаки склоняли модель к маркировке человека как зависимого от пищи. Наиболее сильное влияние оказали психологические факторы: выражения вроде «Иногда я чувствую себя совершенно никчёмным», ощущение «распада» под давлением, частая злость из‑за того, как другие относятся к ним, эмоциональное напряжение и жёсткое, негибкое мышление. Вес тела и ИМТ тоже имели значение, но были менее центральными по сравнению с этими эмоциональными и личностными сигналами. Черты, связанные с позитивным настроением и хорошей организованностью, оказывали умеренное защитное влияние.
Что это значит для повседневной жизни
Для обычного читателя главный вывод в том, что пищевая зависимость — это не просто вопрос силы воли или пристрастия к вкусным закускам. В этой пилотной группе студентов более глубокие эмоциональные трудности — низкая самооценка, сложности с управлением стрессом и напряжённые отношения — оказались тесно связаны с проблемным приёмом пищи. Ранние версии инструментов машинного обучения, обученные на простых опросниках и антропометрии, смогли уловить эти паттерны с обнадеживающей точностью. Однако авторы подчёркивают, что выборка была небольшой, основана на самоотчётах и взята из одного университета, поэтому результаты предварительны. При больших и более разнообразных исследованиях подобные модели в будущем могут использоваться вместе со стандартными клиническими оценками, чтобы выявлять молодых людей, которым может понадобиться помощь в управлении как эмоциями, так и привычками питания.
Цитирование: Rahimnezhad, A., Mortazavi, S.T., Behdarvand, Y. et al. Machine learning prediction of food addiction in university students using demographic, anthropometric and personality traits. Sci Rep 16, 6745 (2026). https://doi.org/10.1038/s41598-026-36162-5
Ключевые слова: пищевая зависимость, студенты университетов, личностные черты, машинное обучение, эмоциональное питание