Clear Sky Science · ru
Руководящая вниманием пространственно-временная слияние признаков для надёжного обнаружения аномалий в видеонаблюдении
Почему важны более умные камеры
От многолюдных вокзалов до торговых центров — современная жизнь полна камер наблюдения, тихо фиксирующих всё происходящее. Тем не менее большинство этих видеозаписей по-прежнему просматриваются — если просматриваются вообще — уставшими человеческими глазами, которые легко могут пропустить решающий момент. В статье рассматривается новый тип «умной» системы наблюдения, способной в реальном времени автоматически обнаруживать необычное или рискованное поведение, такое как кража или вандализм, понимая не только то, что показано в кадре, но и то, как это меняется во времени.

Видеть больше, чем пиксели
Традиционная видеопоток — это просто последовательность изображений. Старые компьютерные системы пытались обнаруживать проблемы, анализируя каждый кадр отдельно и ища формы и контуры, похожие на людей или объекты. Авторы сначала проверяют современную версию этой идеи, которая использует компактную сеть распознавания изображений в сочетании с классическими детекторами границ. Такая схема хорошо работает в аккуратно оформленных сценах, особенно при заметных визуальных признаках, например когда кто-то хватает предмет. Но поскольку она фокусируется на отдельных снимках, она испытывает трудности, когда люди заслоняют друг друга, в плотных толпах или когда одна и та же поза может означать как обычное, так и подозрительное поведение в зависимости от того, как оно развивается со временем.
Понимание движения и поведения
Чтобы уловить историю действия, а не только внешний вид одного кадра, исследование далее оценивает модель, ориентированную на видео, которая анализирует короткие фрагменты вместо одиночных изображений. Эта модель изучает, как движение распространяется через несколько кадров, и лучше распознаёт внезапные изменения, такие как бег, драка или выхват вещи. Она хорошо ловит многие аномальные события, что приводит к высокой чувствительности. Однако у неё также есть классическая проблема реального мира: действительно необычные события редки по сравнению с повседневной активностью. В результате модель может становиться нестабильной, давая слишком много ложных срабатываний и требуя аккуратно вырезанных отрезков видео, которые не отражают беспорядочный, непрерывный характер реального наблюдения.
Слияние где и когда
Опираясь на сильные и слабые стороны этих двух базовых подходов, авторы предлагают новую гибридную систему под названием HybridModel-1, которая стремится «думать» и в пространстве, и во времени одновременно. Она комбинирует сеть, хорошо распознающую, какие объекты присутствуют в каждом кадре, с быстрым детектором, определяющим расположение этих объектов в сцене. Специальный модуль слияния учится выделять наиболее информативные визуальные детали — таких как люди и ключевые объекты — одновременно приглушая фоновые помехи вроде стен, деревьев или проезжающих машин. Параллельно новая стратегия обучения мягко штрафует систему, когда её уверенность резко меняется от кадра к кадру, подталкивая её к более плавным и согласованным решениям на протяжении всего видео.
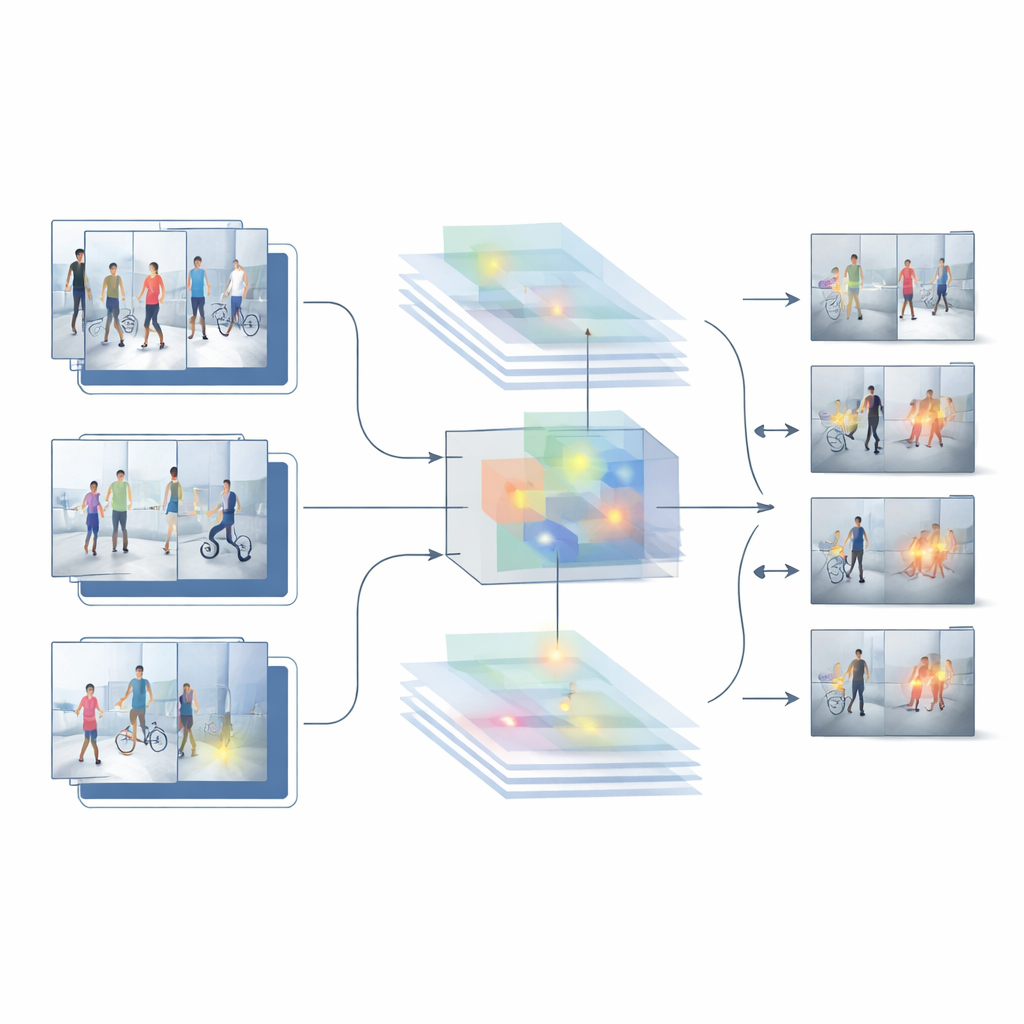
Испытание системы
Чтобы понять, работает ли такой дизайн вне лаборатории, исследователи протестировали его на нескольких сложных публичных наборах данных реальных видеозаписей наблюдения. Эти коллекции включают всё — от сцен краж в помещениях до открытых дорожек на кампусе, с разными позициями камер, освещением, плотностью толпы и типами инцидентов. На этих тестах гибридная модель превосходит как подход, основанный только на изображениях, так и сугубо видеоподход. Она достигает более высокой общей точности, даёт значительно меньше ложных тревог и сохраняет высокую эффективность даже при оценке записей, на которых не обучалась. Подробные сравнения и абляционные исследования — когда части системы удаляют или изменяют — показывают, что модуль слияния признаков и шаг обучения, ориентированный на плавность, каждый вносят значимый вклад в эти улучшения.
Что это значит для повседневной безопасности
Проще говоря, работа показывает, что системы наблюдения становятся надёжнее, когда они учатся обращать внимание на нужные части сцены и сохранять устойчивость оценок во времени. Вместо того чтобы рассматривать каждый кадр как изолированное изображение или полагаться только на сырое движение, предложенный подход сочетает «что» и «когда» в одной тщательно настроенной структуре. Хотя остаются проблемы в условиях очень плохого освещения или сильных перекрытий, результаты указывают на практический путь к сетям камер, которые могут в фоновом режиме просматривать огромные объёмы видео, выявлять действительно подозрительные события и снижать нагрузку ложных тревог на операторов. Для общественности это может означать более безопасные пространства, контролируемые системами, которые не просто смотрят, но и действительно понимают увиденное.
Цитирование: Nivethika, S.D., Joshi, S., Verma, K. et al. Attention-guided saptio-temporal feature fusion for robus video surveillance anomaly detection. Sci Rep 16, 8027 (2026). https://doi.org/10.1038/s41598-026-36130-z
Ключевые слова: видеонаблюдение, обнаружение аномалий, умные камеры, обнаружение преступлений, машинное обучение