Clear Sky Science · ru
Многопараметрическая оптимизированная база правил убеждений для прогнозирования успеваемости студентов с интерпретируемостью
Почему прогнозирование оценок важно для всех
Выглядящие просто табели успеваемости скрывают за собой сложные факторы, которые формируют оценки ученика. Школы всё чаще используют компьютерные модели, чтобы вовремя выявить учеников, испытывающих трудности, и направить им помощь. Однако многие такие модели — «чёрные ящики»: они могут быть точными, но даже учителя и родители не видят, почему был сделан тот или иной прогноз. В этой статье предложен новый подход, который стремится сочетать высокую точность и понятность, чтобы педагоги могли доверять результатам и действовать на их основе.
Более разумный способ читать сигналы
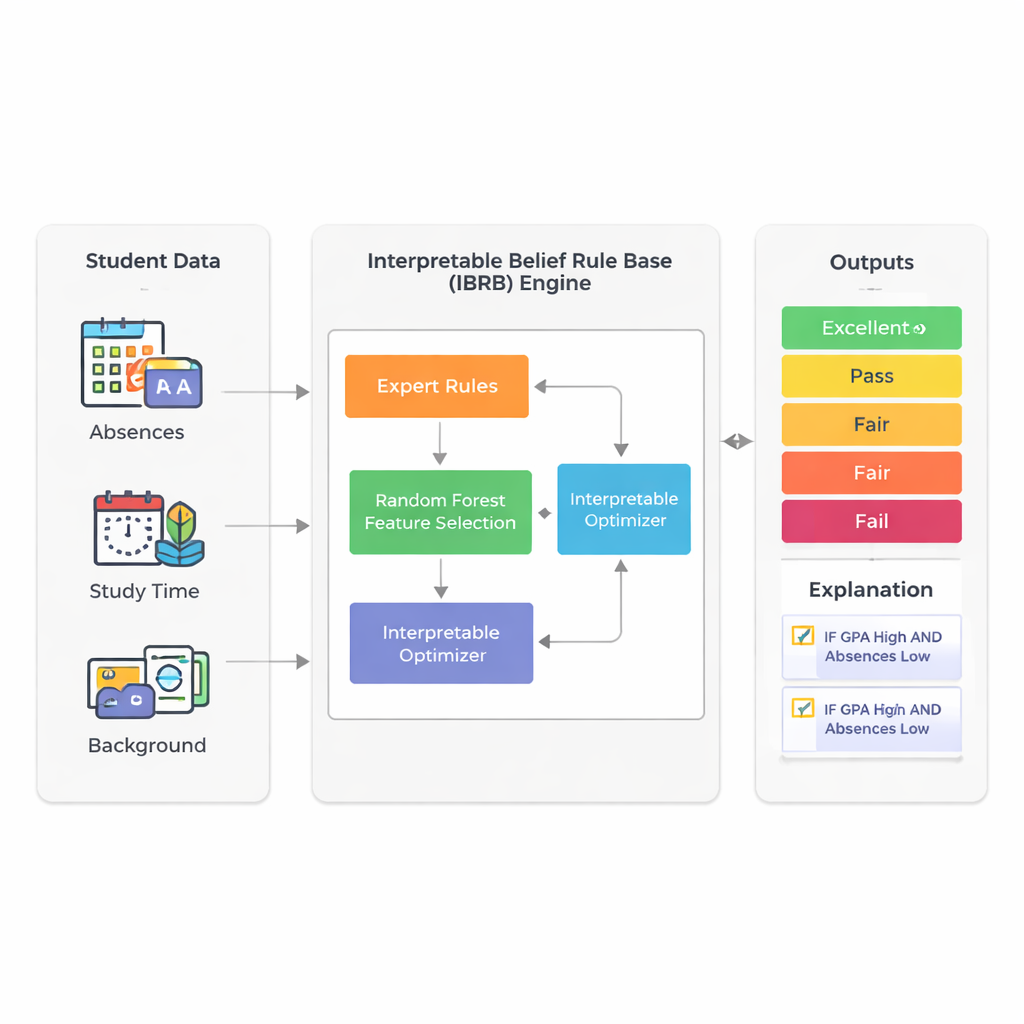
Исследование сосредоточено на прогнозировании конечной успеваемости студентов с использованием данных, которые школы уже собирают: средний балл (GPA), число пропусков, время на учёбу, социальный фон и факторы семьи и внеклассной активности. Вместо опоры на непрозрачные системы глубокого обучения авторы опираются на метод, называемый базой правил убеждений. В этой схеме эксперты записывают правила, которые напоминают высказывания учителя: «Если GPA высокий и пропусков мало, то, вероятно, студент покажет хорошие результаты». Каждое правило сопровождается степенью уверенности в возможных исходах, таких как Отлично, Хорошо, Сдано, Удовлетворительно или Неудовлетворительно. Это делает процесс рассуждения видимым и, по сути, объяснимым для неспециалистов.
Укрощение сложности без потери смысла
Главная проблема с системами на основе правил — их склонность к «взрыву правил», когда включается много характеристик: каждая дополнительная переменная умножает число возможных правил. Чтобы избежать этого, исследователи сначала используют случайный лес — широко применяемый ансамбль решающих деревьев — чтобы оценить, какие признаки важны для прогнозирования успеваемости. В их реальном наборе данных из 2392 студентов из общедоступного источника GPA и количество пропусков объясняют около 73% предсказательной силы модели. Целенаправленно оставив только эти два входа, финальная модель остаётся компактной и более удобной для интерпретации, при этом отражая большую часть вариаций в результатах студентов.
Построение правил, которым люди могут следовать
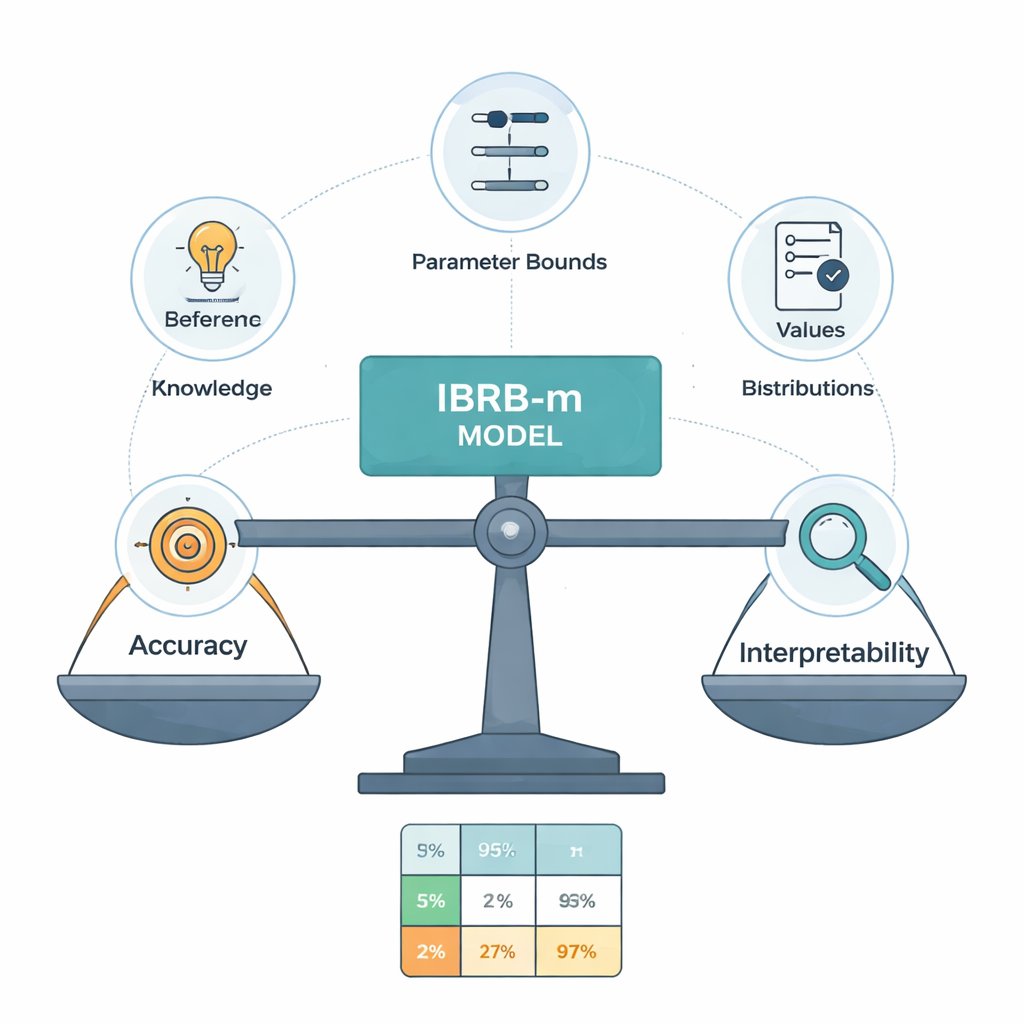
Ядро новой модели, названной IBRB-m, — это тщательно структурированный набор из 25 правил, комбинирующих уровни GPA и пропусков со степенями уверенности по пяти категориям успеваемости. Авторы формализуют, что значит, чтобы такая модель была «интерпретируемой». Среди требований: каждый опорный уровень (например, «низкий GPA») должен охватывать чёткий и различимый диапазон; база правил должна покрывать все реалистичные комбинации входных величин; параметры, такие как веса правил и веса признаков, должны иметь понятные, практические значения; а внутренние вычисления системы должны преобразовывать информацию прозрачно и математически последовательно. Поверх этих традиционных условий они добавляют образовательные руководящие принципы, которые заставляют предсказания модели следовать здравому смыслу — например, избегать абсурдных случаев, когда студент одновременно оценивается как очень вероятно преуспевающий и как обречённый на провал.
Как данные донастраивают то, что говорят эксперты
Мнения экспертов не всегда совпадают, и их начальные правила могут быть неточными. Чтобы уточнить эти правила, не превращая модель в чёрный ящик, авторы разработали улучшенный алгоритм оптимизации, который ищет лучшие значения параметров при строгом соблюдении ограничений интерпретируемости. Этот алгоритм настраивает не только веса правил и степени уверенности, но и пороговые точки, определяющие категории вроде Отлично или Сдано. Все изменения остаются в рамках, одобренных экспертами, и алгоритм поддерживает разумные, плавные закономерности уверенности по мере изменения оценок. Фактически, компьютер «подталкивает» экспертную систему к повышению точности, но не вправе придумывать правила, которые поставили бы в тупик опытного педагога.
Насколько это работает на практике?
Проверенная на датасете успеваемости студентов с Kaggle модель IBRB-m корректно предсказывает итоговые уровни успеваемости в более чем 99% случаев, превосходя как ранние системы на базе правил убеждений, так и распространённые инструменты машинного обучения, такие как нейронные сети, случайные леса и k-ближайших соседей. Не менее важно то, что оптимизированные правила остаются близкими к исходным экспертным оценкам при измерении простой метрикой расстояния, что означает — рассуждение за каждым прогнозом всё ещё можно проследить и обосновать. Кросс-валидация по нескольким разбиениям данных показывает, что производительность модели стабильна и не является случайным результатом удачного разбиения.
Что это означает для классов
Для неспециалистов главный вывод заключается в том, что возможно создать инструменты прогнозирования успеваемости, которые одновременно мощные и понятные. Вместо выдачи таинственных оценок риска модель может выделять конкретные паттерны вроде «средний GPA, но частые пропуски» и показывать, как это ведёт к прогнозу Удовлетворительно или Неудовлетворительно. Учителя и кураторы затем могут предпринять целенаправленные меры — например, поддержку посещаемости или обучение навыкам учёбы — и при этом уверенно объяснять студентам и родителям, почему модель пришла к такому выводу. Авторы утверждают, что такое сочетание точности и прозрачности необходимо, если системы, опирающиеся на данные, должны играть доверенную роль в обеспечении справедливого и эффективного образования.
Цитирование: Li, J., Zhou, W., Jiang, S. et al. The multi-parameter optimized belief rule base for predicting student performance with interpretability. Sci Rep 16, 5772 (2026). https://doi.org/10.1038/s41598-026-35950-3
Ключевые слова: прогнозирование успеваемости студентов, интерпретируемый ИИ, база правил убеждений, майнинг образовательных данных, объяснимое машинное обучение