Clear Sky Science · ru
HEViTPose: к высокоточной и эффективной 2D-оценке поз человека с каскадным групповым пространственным редукционным вниманием
Обучая компьютеры «читать» язык тела
От фитнес-приложений до систем помощи водителю — многие технологии сейчас зависят от способности компьютера понимать, как движутся люди. Эта задача, называемая оценкой позы человека, состоит в определении положений суставов — например, плеч, коленей и лодыжек — на изображении или в видео. Сложность заключается в том, чтобы делать это одновременно точно и быстро, чтобы подходило для работы в реальном времени на обычном оборудовании. В статье представлен HEViTPose — новый метод, который сохраняет высокую точность при меньших затратах вычислений по сравнению со многими современными системами.
Почему поиск суставов на изображениях так сложен
На первый взгляд определение суставов может показаться простым: достаточно найти руки и ноги. На практике люди появляются в разных масштабах, в необычных позах, в зашумленных сценах и часто частично закрыты предметами — мебелью или автомобилями. Современные системы оценки поз обычно решают это, создавая подробную «тепловую карту» для каждого сустава, где яркие участки указывают на вероятные позиции. Тепловые карты дают высокую точность, но дорогие в вычислении. Традиционные системы в основном опираются на сверточные нейронные сети, которые хорошо улавливают локальные паттерны, но им приходится становиться глубже и «тяжелее», чтобы захватывать дальние взаимосвязи по всему телу. Новые модели на основе трансформеров превосходно моделируют такие дальние связи, однако часто требуют больших наборов данных и больших вычислительных ресурсов, что затрудняет их применение в реальном времени или на малых устройствах.
Наложенные фрагменты для более плавного восприятия
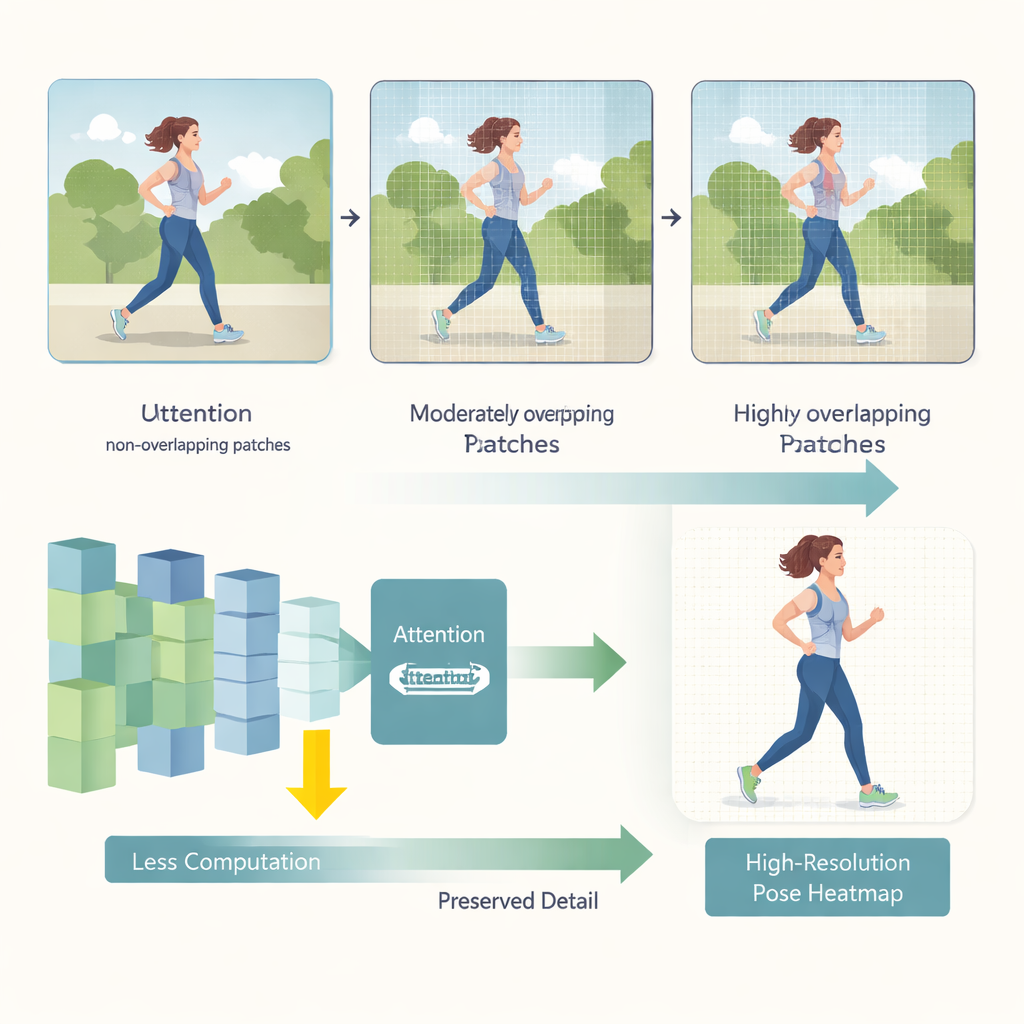
HEViTPose начинает с переосмысления того, как изображение разбивается на куски для анализа. Ранние трансформер-модели часто разрезали картинку на непересекающиеся плитки, что могло нарушать визуальную целостность соседних областей — например, отрезать руку человека по краю патча. HEViTPose опирается на идею наложенных встраиваний патчей и вводит более понятную, настраиваемую меру, названную шириной перекрытия встраивания патча (Patch Embedding Overlap Width, PEOW). PEOW просто считает, сколько пикселей соседние плитки разделяют по границе. Систематически варьируя это перекрытие, авторы показывают, что умеренное перекрытие позволяет сети лучше «чувствовать» плавные изменения цвета и формы от одного патча к другому. Это богатое локальное непрерывное представление приводит к более точному определению суставов, не увеличивая существенно размер модели или вычисления.
Более умное внимание при меньших затратах
Второе ключевое новшество — новый модуль внимания под названием каскадное групповое пространственное редукционное многоголовое внимание (Cascaded Group Spatial Reduction Multi-Head Attention, CGSR-MHA). Механизмы внимания указывают сети, какие части изображения должны влиять на каждое предсказание, но обычно они плохо масштабируются с увеличением размера изображения. CGSR-MHA решает эту проблему тремя способами. Во-первых, он делит признаки на группы, так что каждая группа обрабатывает лишь часть информации, а не все сразу. Во-вторых, внутри каждой группы снижается пространственное разрешение перед вычислением внимания, что значительно уменьшает число операций. В-третьих, используется несколько небольших голов внимания вместо нескольких крупных, что сохраняет разнообразие того, на что модель может «обращать внимание», при более низкой стоимости. Тщательно подобранные параметры числа групп, степени сжатия и числа голов обеспечивают баланс между скоростью и точностью.
Легковесные модели, всё ещё сопоставимые с лучшими
Для проверки HEViTPose авторы оценили метод на двух широко используемых бенчмарках: наборе MPII с повседневной человеческой активностью и большем наборе COCO с людьми в самых разных сценах. Для нескольких размеров моделей HEViTPose достигает или почти достигает точности ведущих систем оценки поз при существенно меньшем числе параметров и вычислений. Например, одна из версий показывает сопоставимую точность с популярной высокоразрешающей сетью (HRNet), при этом сокращая число обучаемых параметров более чем на 60% и снижая объём вычислений более чем на 40%. По сравнению с другой современной гибридной моделью, сочетающей свертки и трансформеры, HEViTPose демонстрирует сопоставимую производительность, но работает примерно в 2,6 раза быстрее на графическом процессоре. Эти экономии напрямую переводятся в более плавную работу в реальном времени и более низкие требования к аппаратному обеспечению.
Что это значит для повседневных приложений
Проще говоря, HEViTPose показывает, что не нужно выбирать между точностью и эффективностью при обучении компьютеров «читать» язык тела. За счёт аккуратного перекрытия тех фрагментов изображения, которые анализирует сеть, и переработки способа вычисления внимания внутри модели, система может с высокой точностью определять суставы, оставаясь компактной и быстрой. Это делает её привлекательной для реальных применений: спортивного трекинга, видеонаблюдения, взаимодействия человек — робот и мониторинга в автомобиле, где важны и скорость, и энергопотребление. Идеи HEViTPose — более разумное перекрытие и эффективное внимание — также могут быть адаптированы для родственных задач, таких как слежение за позой животных или обнаружение лицевых ориентиров, что потенциально принесёт более «острое» цифровое зрение на множество устройств без необходимости суперкомпьютерного железа.
Цитирование: Wu, C., Chen, Z., Ying, B. et al. HEViTPose: towards high-accuracy and efficient 2D human pose estimation with cascaded group spatial reduction attention. Sci Rep 16, 5637 (2026). https://doi.org/10.1038/s41598-026-35859-x
Ключевые слова: оценка позы человека, компьютерное зрение, vision transformer, эффективное глубокое обучение, механизм внимания