Clear Sky Science · ru
Гибридная архитектура CNN и обучения с подкреплением для идентификации говорящего с использованием признаков мел-спектрограммы и непрерывного вейвлет-преобразования
Почему ваш голос может стать цифровым ключом
Представьте, что вы открываете банковский счет, входную дверь или телефон, используя только голос. Чтобы это было безопасно, компьютеры должны надежно отличать одного человека от другого, даже при шумном фоне, эмоциях или плохом микрофоне. В этой работе исследуется новый подход к обучению машин распознавать, кто говорит, а не только что говорится, сочетая современные приёмы глубокого обучения с методом проб и ошибок из робототехники.
От звуковой волны к отпечатку голоса
Голос каждого человека содержит тонкие подсказки, сформированные размером и формой вокального тракта, тем, как вибрируют голосовые складки, и манерой речи. Исследователи начали с вопроса: какие измеримые свойства записи речи действительно отличаются у разных людей? Используя 2703 аудиоклипа от 40 англоговорящих в наборе данных LibriSpeech, они проанализировали 22 простых акустических признака, таких как вариация громкости, энергия в разных частотных полосах, ритм и мера, называемая энтропией, которая отражает сложность или непредсказуемость звука. Статистические тесты показали, что 21 из этих 22 признаков несут сильную информацию, специфичную для говорящего, а энтропия и энергия в высоких частотах оказались особенно отличительными. Иными словами, «отпечаток голоса» человека распределён по многим аспектам звука, а не только по тону или громкости.
Два способа превратить звук в изображение
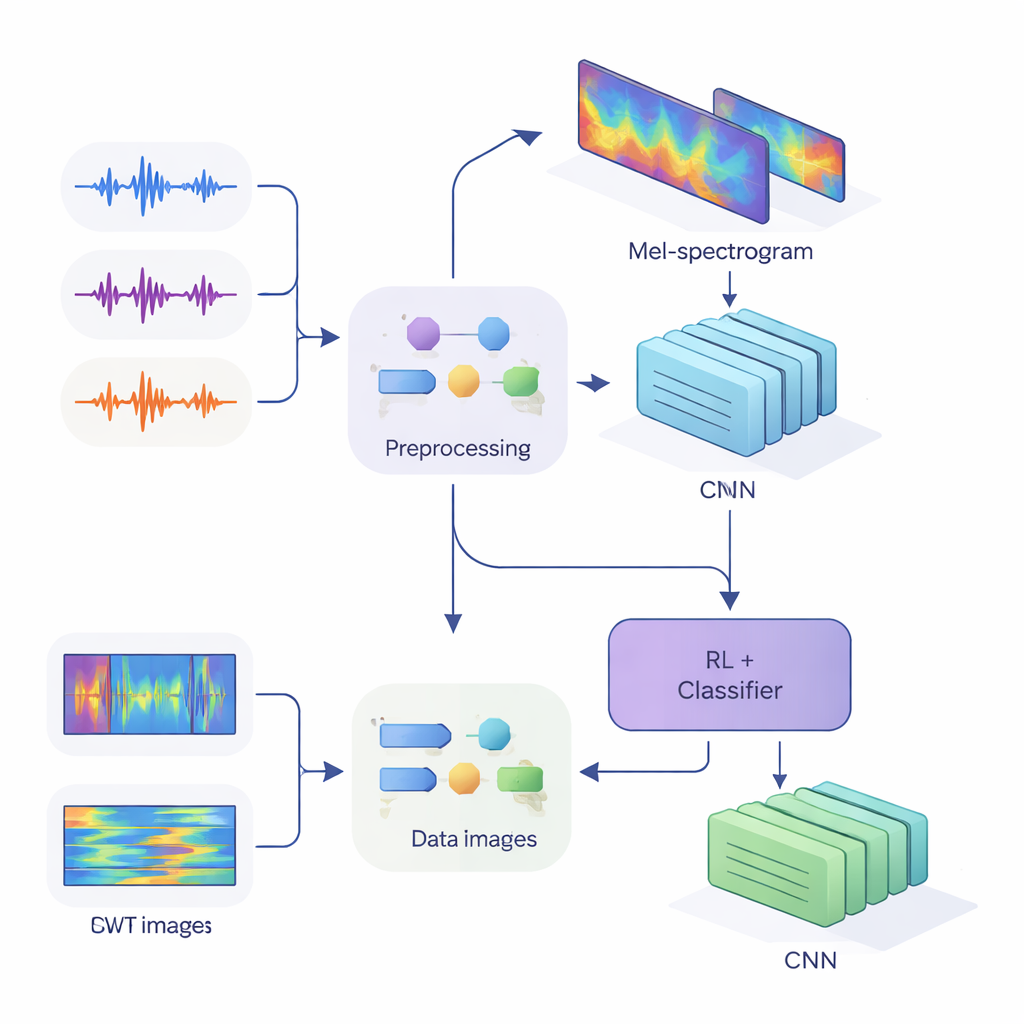
Чтобы передать эти подсказки современным нейросетям, команда преобразовала одномерный аудиосигнал в двумерные изображения, которые фиксируют, как энергия меняется во времени и по частоте. В первом методе использовались мел-спектрограммы, имитирующие группировку частот человеческим ухом и ставшие стандартом в речевых технологиях. Во втором методе применили непрерывное вейвлет-преобразование — более гибкий способ приблизить как короткие резкие звуки, так и длительные гласные. После тщательной очистки аудио — удаления тишины, стандартизации громкости и добавления небольших искажений вроде шума и сдвигов тона для повышения робастности — они получили мел-«изображения» размером 80×313 и вейвлет-«изображения» размером 128×128, готовые к обработке сверточными нейронными сетями (CNN).
Обучение сетей слушать и сомневаться
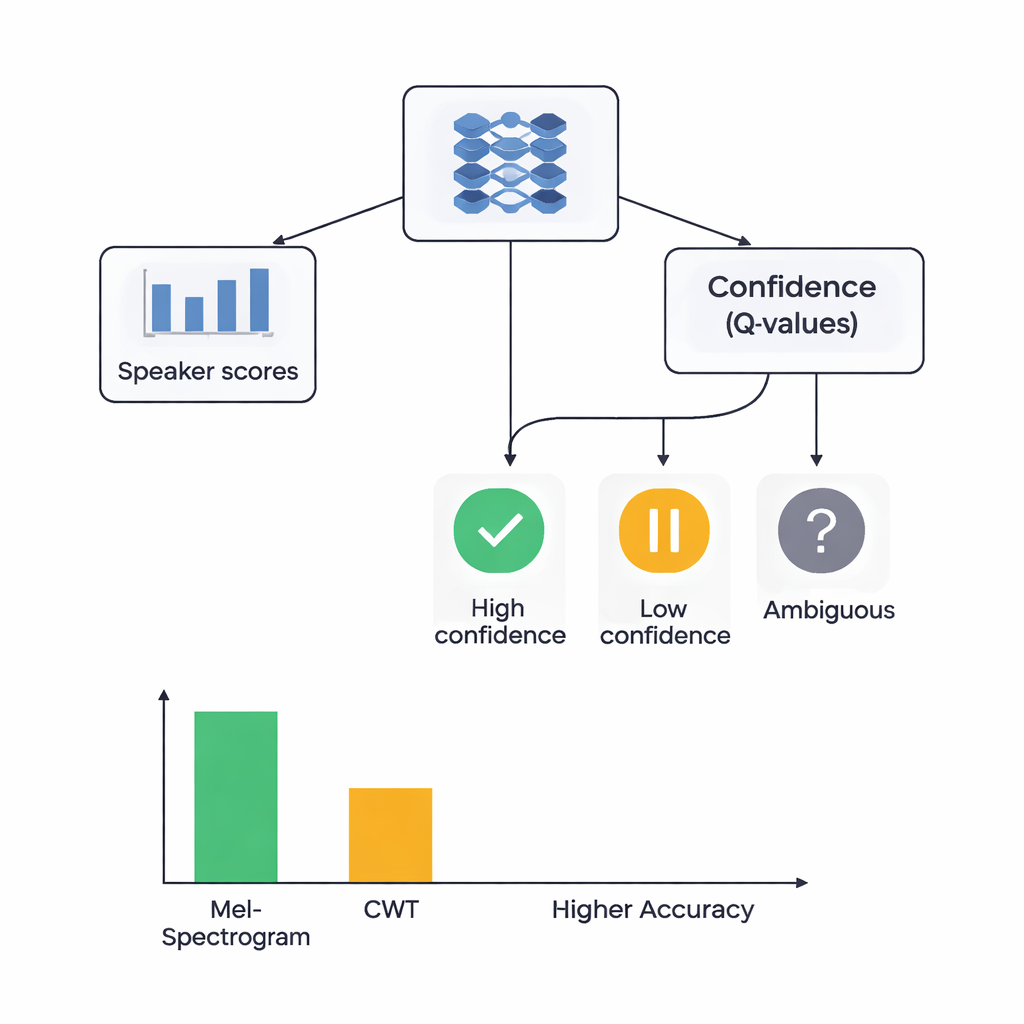
В основе исследования лежит гибридная архитектура, объединяющая два стиля обучения. Сначала CNN сканируют мел- или вейвлет-изображения, извлекая паттерны, характерные для конкретных говорящих, подобно тому, как сети для распознавания изображений учатся замечать глаза или контуры. Для системы на основе мел-спектрограмм авторы добавляют модуль самовнимания, позволяющий сети фокусироваться на наиболее информативных временных сегментах. Поверх этих извлекателей признаков размещён компонент обучения с подкреплением (RL), который учится оценивать степень уверенности системы в каждом решении. Вместо того чтобы всегда делать жёсткий выбор, RL назначает ценности действиям вроде «принять как уверенное предположение», «расценить как низкую уверенность» или «пометить как сомнительное». В ходе многочисленных тренировочных циклов он получает вознаграждение за правильные уверенные решения, подталкивая сеть к лучшей калибровке суждений.
Насколько хорошо работает гибридная система?
Исследователи сравнили четыре модели: на основе мел с RL, на основе мел без RL, на основе вейвлетов с RL и на основе вейвлетов без RL. Все модели оценивались с использованием тщательной пятикратной кросс-валидации, то есть каждый аудиоклип поочерёдно служил и для обучения, и для тестирования. Система Mel + RL показала наилучший результат, правильно идентифицируя говорящего примерно в 88% случаев и демонстрируя почти идеальное разделение говорящих по стандартной метрике дискриминационной способности. Система wavelet + RL достигла примерно 78% точности. Важно, что добавление компонента RL улучшило показатели для обоих типов признаков примерно на 3 процентных пункта и сделало результаты более устойчивыми между разными разбиениями данных. Большее число классов говорящих получило высокое качество распознавания при включённом RL, что указывает на то, что принятие решений с учётом уверенности особенно помогло в сложных случаях с легко путаемыми голосами.
Что это значит для повседневной голосовой безопасности
Для неспециалистов главный вывод таков: надёжная голосовая идентификация требует и богатых представлений звука, и здоровой доли сомнения со стороны машины. Эта работа показывает, что мел-спектрограммы, вдохновлённые слуховой системой, в сочетании с вниманием и обучающимся с подкреплением модулем, умеющим говорить «я не уверен», превосходят более экзотические вейвлет-изображения в задаче различения говорящих. Хотя исследование использует относительно небольшой и чистый набор данных и ещё не оптимизировано для шумных реальных условий, оно демонстрирует, что добавление слоя, учитывающего уверенность, поверх глубоких нейросетей может сделать голосовую аутентификацию точнее и надёжнее — важный шаг на пути к тому, чтобы наши голоса стали безопасными цифровыми ключами.
Цитирование: Heir, F.M., Najafzadeh, H. & Erfani, S. A hybrid CNN and reinforcement learning framework for speaker identification using Mel-Spectrogram and continuous wavelet transform features. Sci Rep 16, 5954 (2026). https://doi.org/10.1038/s41598-026-35858-y
Ключевые слова: идентификация говорящего, голосовая биометрия, глубокое обучение, обучение с подкреплением, мел-спектрограммы