Clear Sky Science · ru
Общая схема для адаптивного непараметрического снижения размерности
Почему важно сжимать большие данные
Современная жизнь работает на данных: медицинские сканы, истории покупок в интернете, фотографии, новостные ленты и многое другое. Каждая запись может содержать сотни или тысячи измерений, что затрудняет хранение, анализ и даже визуализацию. Ученые используют «снижение размерности», чтобы сжать эту сложность в более простые представления и модели, сохраняя важные закономерности. Но популярные сегодня инструменты часто требуют множества ручных настроек и перебора параметров методом проб и ошибок. В этой статье предложен способ позволить самим данным решать, как лучше сжимать пространство, что приводит к более ясным визуализациям, более точному обучению и меньшему количеству догадок со стороны пользователя.
От простых линий к изогнутым реалиям
Классический инструмент упрощения данных, метод главных компонент (PCA), работает как осветить объект и посмотреть на его тень: он находит лучшие плоские направления, объясняющие большую часть разброса. Это эффективно, когда структура данных примерно прямая или плоская. Но реальные данные — например, изображения, тексты или показания датчиков — часто лежат на изогнутых поверхностях, скрытых в пространствах высокой размерности. За последние два десятилетия появились новые «нелинейные» методы, такие как Isomap, Locally Linear Embedding (LLE), спектральное вложение и UMAP, специально предназначенные для выявления этих извилистых форм. Они опираются на локальные окрестности: для каждой точки выбирают ближайших соседей и стараются сохранить эти мелкомасштабные связи при построении низкоразмерного представления. Однако эти методы заставляют пользователя выбирать два ключевых параметра: сколько соседей использовать и в какую размерность проецировать. Неправильный выбор может привести к искаженному результату или к высокой вычислительной сложности.
Позволить данным выбирать собственную окрестность
Авторы опираются на недавний статистический инструмент — оцениватель внутренней размерности, который отвечает на простой вопрос: в скольких независимых направлениях данные действительно меняются, после отбрасывания шума? Их оцениватель, названный ABIDE, идёт дальше. Вокруг каждой точки он автоматически ищет окрестность, которая выглядит достаточно однородной — не слишком маленькую и зашумлённую и не слишком большую и искаженную. В результате он возвращает два результата: глобальную оценку истинной размерности данных и подобранный размер окрестности для каждой точки. Это превращает обычное фиксированное «число соседей» в локально адаптивную величину, которая может увеличиваться в разреженных областях и уменьшаться в густонаселённых, соответствуя реальной плотности данных.
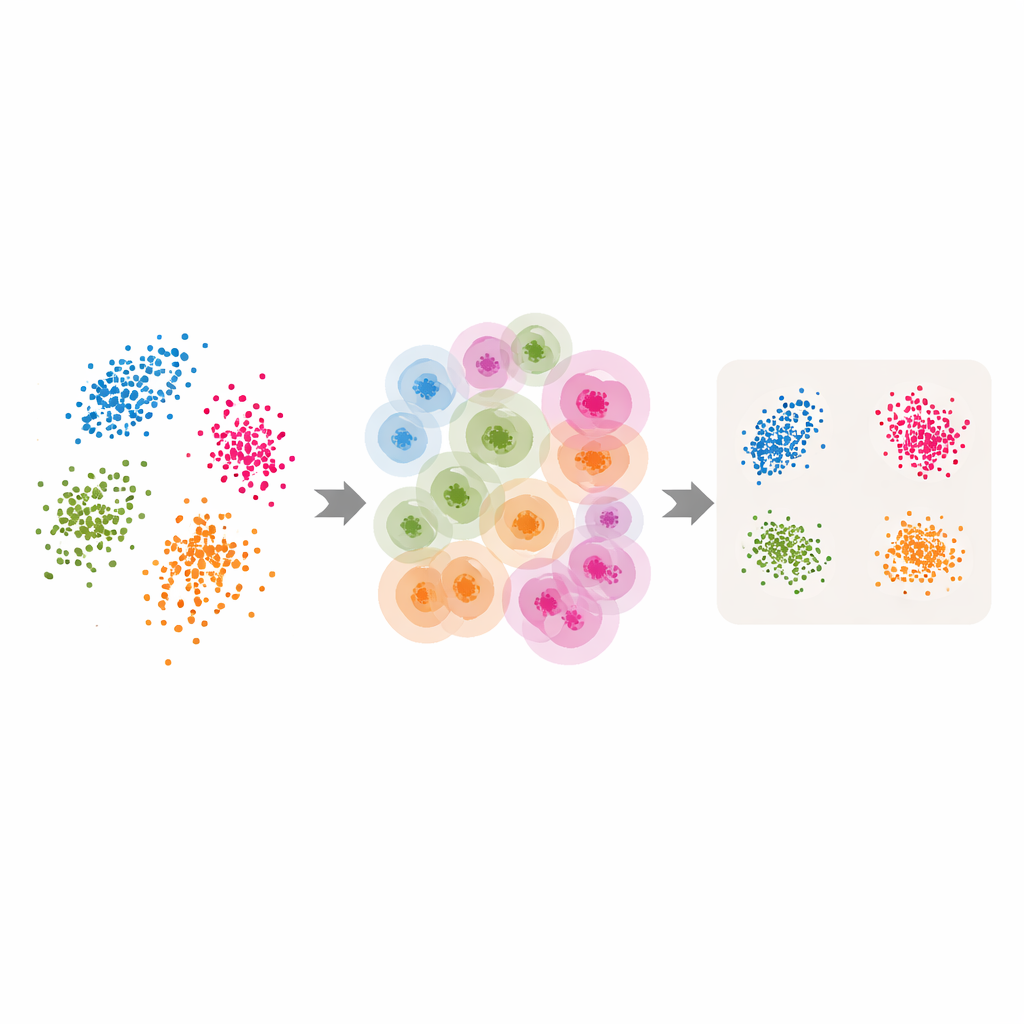
Преобразование классических инструментов в адаптивные
Имея эти адаптивные окрестности и оценку внутренней размерности, авторы перерабатывают несколько популярных методов понижения размерности и кластеризации. Для LLE они заменяют единое, заданное пользователем число соседей на значение, возвращаемое ABIDE для каждой точки, а целевую размерность устанавливают равной оценённой внутренней размерности. Алгоритм затем учится восстанавливать каждую точку из тщательно подобранной локальной группы, после чего находит глобальное низкоразмерное расположение, которое наилучшим образом сохраняет эти локальные восстановления. Аналогичные идеи применяются к спектральной кластеризации — где для группировки используется граф сходств между точками — и к UMAP, который строит «нечеткую» карту связей между точками. В каждом случае жёсткий размер окрестности заменяется гибкой, управляемой данными структурой, которая следует естественной геометрии данных.
Тестирование на цветах, цифрах, текстах и синтетических формах
Чтобы понять, окупается ли такой адаптивный подход, авторы провели эксперименты на нескольких бенчмарках: классические измерения ириса, изображения рукописных цифр (MNIST), новостные статьи, представленные эмбеддингами языковых моделей, и синтетические трёхмерные формы с добавленным шумом. Они сравнили адаптивные версии со стандартными настройками программного обеспечения и с тщательно подобранными сетками гиперпараметров. В неконтролируемых задачах, таких как кластеризация и визуализация, адаптивные методы обычно дают более чёткие кластеры, более компактные группы и лучшие показатели по стандартным метрикам качества. Например, на сложных многообразиях с неравномерной плотностью точек адаптивные методы восстанавливают истинную структуру гораздо точнее, чем версии с фиксированными соседями. В контролируемых тестах, где уменьшенные данные подаются в классификатор, адаптивный подход снова сравним или превосходит лучшие варианты с фиксированными настройками, без необходимости исчерпывающего перебора параметров.
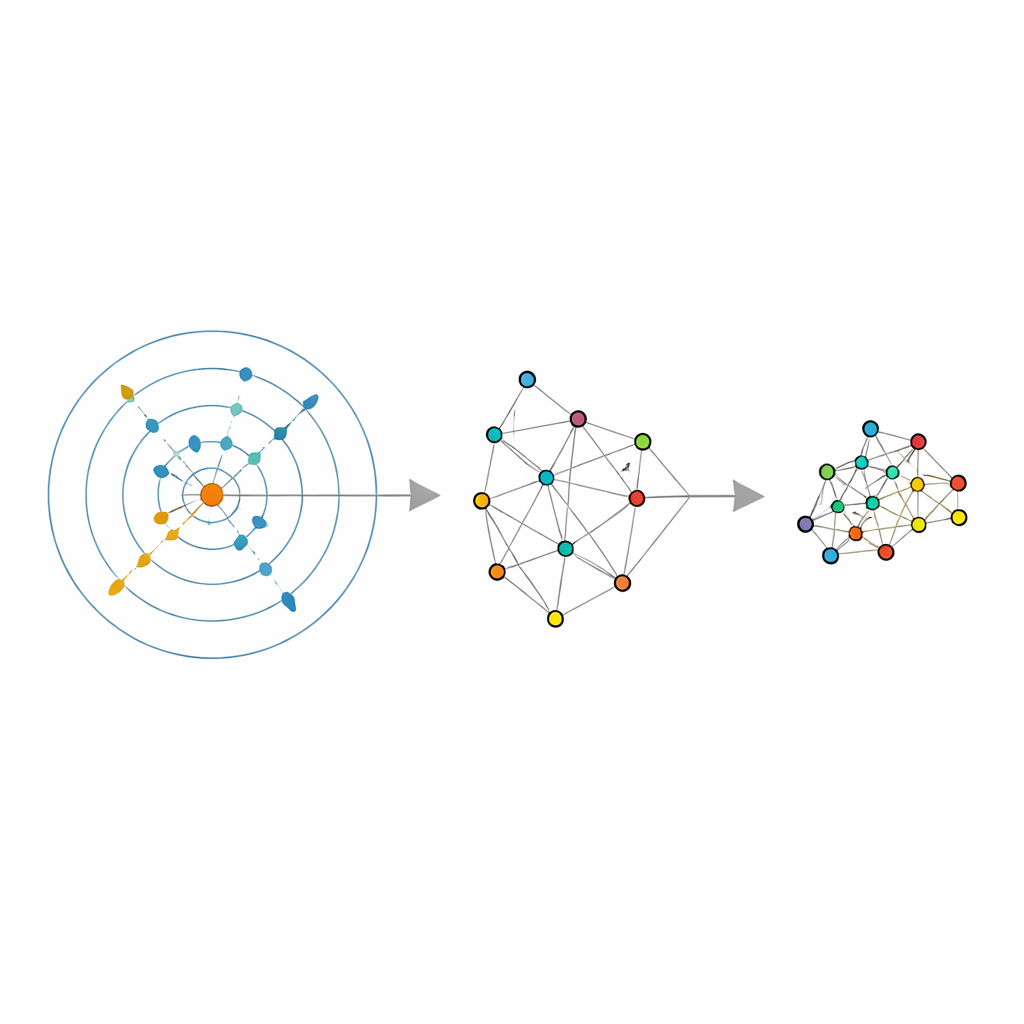
Что это значит для повседневного анализа данных
Для непрофессионалов и практиков главное послание заключается в том, что сжатие данных не обязательно должно опираться на догадки. Используя собственную геометрию данных для решения вопросов «сколько соседей» и «в какую размерность», эта схема превращает широко используемые инструменты, такие как LLE, спектральная кластеризация и UMAP, в более умные и устойчивые версии самих себя. Результат — более надёжные низкоразмерные представления — графики и признаки, которые лучше отражают истинную форму данных — при этом часто уменьшается время, затрачиваемое на ручной подбор гиперпараметров. На практике это означает, что задачи вроде визуализации больших коллекций изображений, группировки документов или подготовки входов для прогнозных моделей могут стать проще и надёжнее, если позволить данным адаптивно направлять процесс сжатия.
Цитирование: Di Noia, A., Ravenda, F. & Mira, A. A general framework for adaptive nonparametric dimensionality reduction. Sci Rep 16, 9028 (2026). https://doi.org/10.1038/s41598-026-35847-1
Ключевые слова: снижение размерности, обучение на многообразиях, ближайшие соседи, внутренняя размерность, визуализация данных