Clear Sky Science · ru
Улучшенный оптимизатор на основе обобщённого нормального распределения с методом восстановления по гауссовскому распределению и обратным обучением Коши для отбора признаков
Почему важно правильно выбирать данные
Современная жизнь опирается на данные: от медицинских снимков и банковских записей до лент социальных сетей. Но больше данных не всегда значит лучше. Когда компьютер обучается на тысячах исходных измерений одновременно, это может замедлить работу, увеличить затраты и, что неудивительно, снизить точность. В этой статье предложен более умный способ отсеивания измерений и сохранения лишь действительно значимых, с помощью нового алгоритма под названием Binary Adaptive Generalized Normal Distribution Optimizer (BAGNDO).
Проблема избытка подсказок
Представьте постановку диагноза на основе сотен лабораторных тестов, снимков и ответов на опросы. Многие из этих «признаков» могут быть шумными, избыточными или просто несущественными, и подача их всех в классификатор скорее запутает, чем поможет. Отбор признаков стремится выбрать меньшее, но более информативное подмножество входов, чтобы модели машинного обучения работали быстрее, дешевле и надёжнее. Простые статистические фильтры удаляют очевидно бесполезные признаки, но они не учитывают особенности конкретной модели и часто упускают тонкие комбинации переменных. Более продвинутые «обёртки» оценивают множества признаков, напрямую проверяя, насколько хорошо работает классификатор, но это порождает огромную задачу поиска: число возможных подмножеств взрывается с ростом числа признаков.
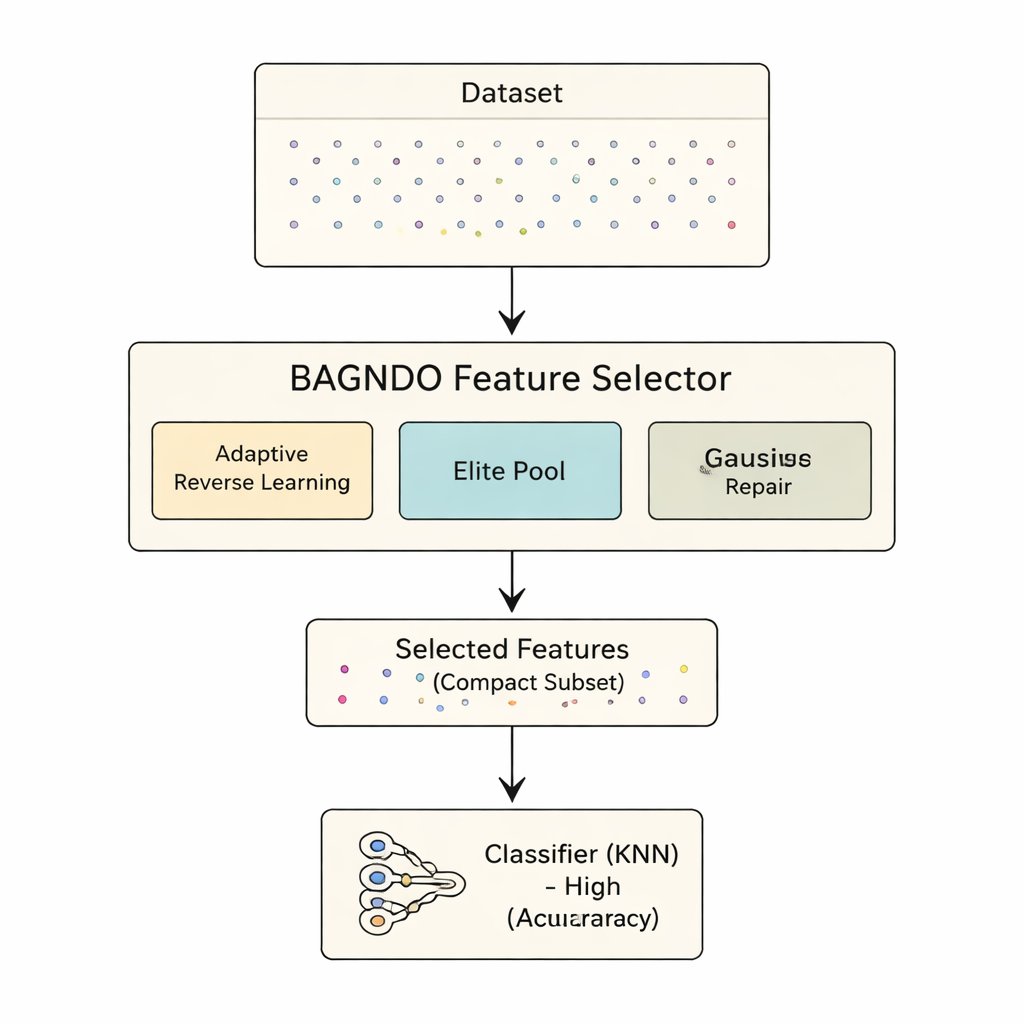
Искать умно, а не вслепую
Чтобы справиться с этим взрывом, исследователи прибегают к метаэвристическим алгоритмам — стратегиям поиска, вдохновлённым природными или физическими процессами, которые балансируют широкое исследование и целенаправленную донастройку. Одна из таких методик, Generalized Normal Distribution Optimizer (GNDO), рассматривает кандидатов на решение как выборки из гибкой колоколообразной кривой и постепенно сдвигает эту кривую в сторону лучших ответов. GNDO показал себя в инженерных и энергетических задачах, но при отборе признаков он склонен преждевременно застревать на посредственных решениях и испытывает трудности с балансом между глобальным исследованием и локальной донастройкой. Авторы отмечают этот существенный пробел: изящная математика GNDO не всегда переводится в высокую эффективность при работе с высокоразмерными двоичными решениями о том, какие признаки оставить.
Трёхчастное улучшение классического механизма
Предлагаемая архитектура BAGNDO усиливает GNDO тремя согласованными идеями. Во‑первых, стратегия адаптивного обратного обучения Коши регулярно порождает «зеркальные» варианты текущих решений с использованием распределения с тяжёлыми хвостами. Это стимулирует смелые прыжки в неизведанные области пространства поиска и предотвращает застревание в локальных ямах. Во‑вторых, стратегия «элитного пула» хранит не один лучший вариант, а небольшую группу лидеров плюс смешанного «направляющего» кандидата. Такая более богатая группа руководителей помогает поддерживать разнообразие, при этом направляя поиск в перспективные регионы. В‑третьих, метод восстановления худших решений на основе гауссовского распределения анализирует слабейших кандидатов и подталкивает их в сторону паттернов, извлечённых из элиты, эффективно перерабатывая неудачные решения в более удачные вместо их простого игнорирования.
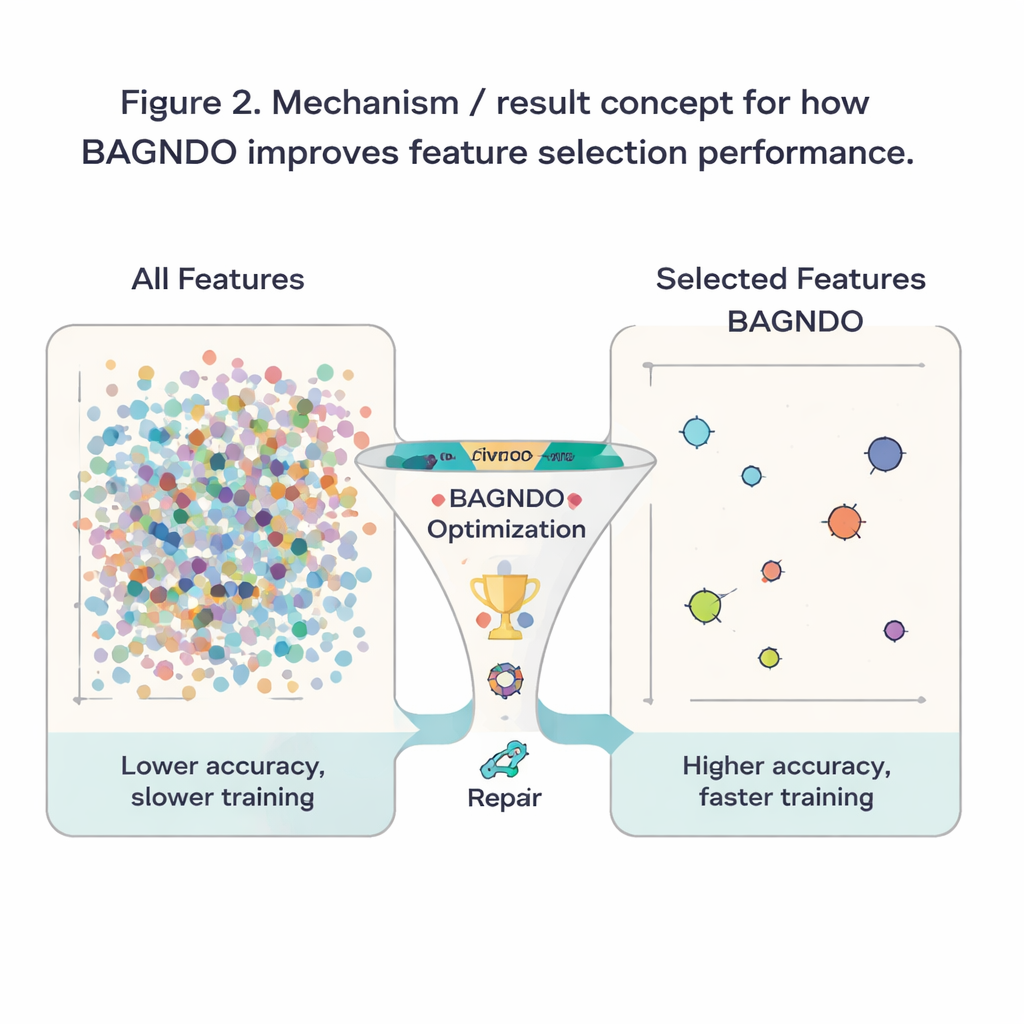
Проверка метода на практике
Чтобы оценить практическую пользу этих идей, авторы применили BAGNDO к 18 известным бенчмарк‑набором из репозитория UCI, охватывающим медицинскую диагностику, игры, сигналы и другие области. В каждом случае алгоритм искал подмножество признаков, позволяющее стандартному классификатору k‑ближайших соседей делать точные предсказания. BAGNDO сравнивали с девятью сильными конкурентами, включая оптимизацию роя частиц, методы генетического типа и несколько современных алгоритмов, вдохновлённых роями. Во всех тестах BAGNDO последовательно находил более компактные наборы признаков, сохраняя или часто улучшая точность предсказаний. Он достигал наилучшей точности с самыми компактными подмножествами в 14 из 18 наборов данных, а статистические тесты подтвердили, что эти улучшения не случайны.
Что это значит для повседневного машинного обучения
Для непрофессионала результат можно резюмировать просто: авторы создали более дисциплинированный «отборщик признаков», который помогает алгоритмам обучения сосредоточиться на действительно важных данных в наборе. Лучше сочетая широкое исследование, руководство элиты и восстановление слабых кандидатов, BAGNDO отсекает лишние входы, сохраняя или повышая точность. Это означает более быстрые модели, меньшие затраты на хранение и вычисления и чаще более ясное понимание того, какие измерения или вопросы наиболее информативны. Хотя метод более вычислительно затратен, чем некоторые простые альтернативы, он представляет собой мощный инструмент для задач, где критически важны точность и интерпретируемость — от медицинской поддержки принятия решений до промышленного мониторинга и дальше.
Цитирование: Ghetas, M., Elaziz, M.A. & Issa, M. Enhanced generalized normal distribution optimizer with Gaussian distribution repair method and cauchy reverse learning for features selection. Sci Rep 16, 4794 (2026). https://doi.org/10.1038/s41598-026-35804-y
Ключевые слова: отбор признаков, метаэвристическая оптимизация, машинное обучение, снижение размерности, точность классификации