Clear Sky Science · ru
Методы квантовых ядер для маркетинговой аналитики с теорией сходимости и границами разделимости
Почему более точные прогнозы клиентов имеют значение
Компании всё чаще опираются на данные, чтобы решать, каких клиентов привлекать предложениями, поддержкой или кампаниями по удержанию. Но по мере усложнения данных традиционные инструменты могут не замечать тонкие закономерности, особенно когда пропущенный высокоценный клиент обходится дорого. В этой статье исследуется, могут ли зарождающиеся квантовые компьютеры — машины, использующие правила квантовой физики — улучшить такие прогнозы для задач маркетинга, причём с учётом современных несовершенных, «шумных» устройств.

От записей о клиентах к квантовым схемам
Авторы сосредотачиваются на практической задаче, которую они называют классификацией потребителей: прогнозировании того, какие пользователи взаимодействуют с цифровым сервисом или примут его. Каждый пользователь описывается небольшим набором числовых признаков, таких как демография и поведение на платформе. Вместо того чтобы подавать эти данные напрямую в стандартный алгоритм, они сначала кодируют их в состояние нескольких кубитов с помощью компактной квантовой схемы. Эта схема действует как преобразование признаков, превращая данные в форму, которую может быть проще разделить на две группы — «скорее вовлечётся» и «скорее не вовлечётся». Поверх этого квантового преобразования используют известный метод классификации, метод опорных векторов, в квантово-ориентированной версии, называемой Q-SVM (SVM с квантовым ядром).
Тестирование квантовых идей в реалистичных условиях
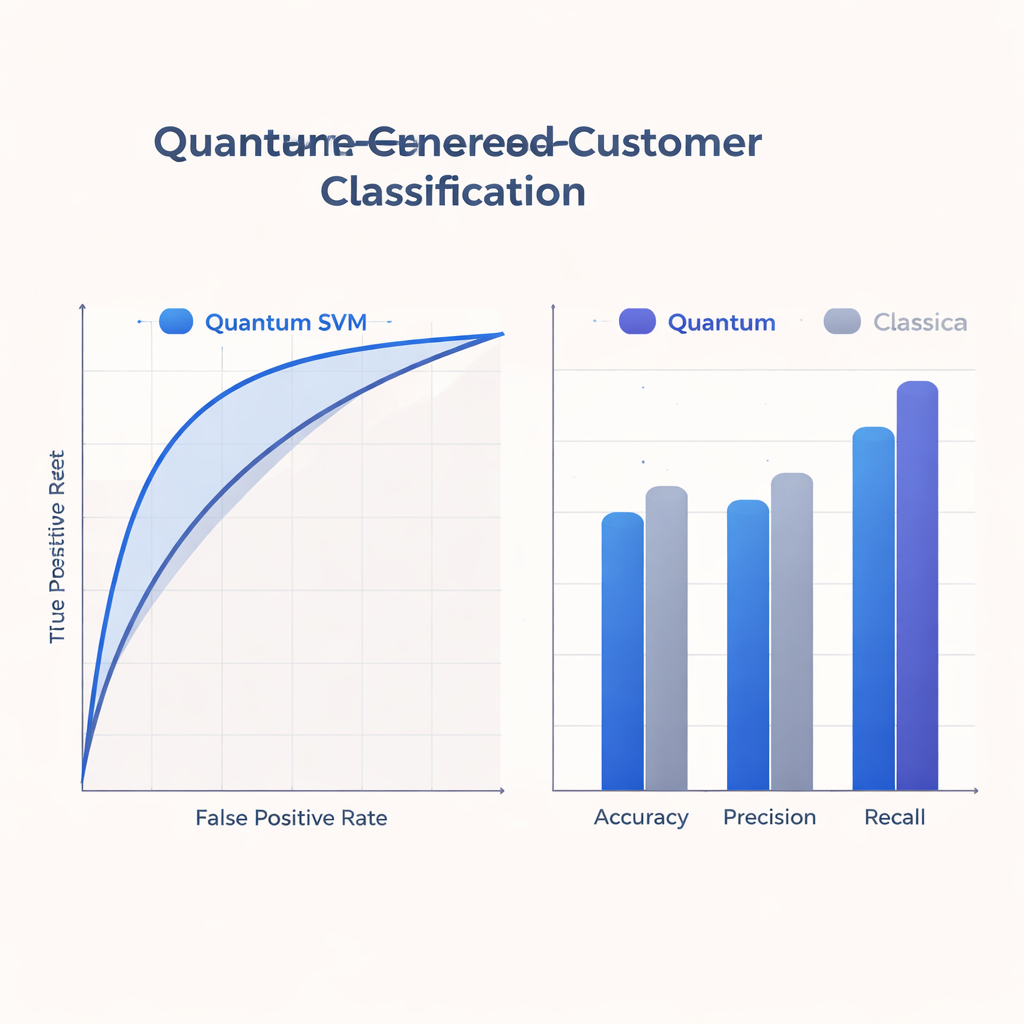
Поскольку современные квантовые устройства малы и подвержены ошибкам, исследование ограничивается мелкими (shallow) схемами, соответствующими возможностям ближайшей перспективы аппаратуры. Команда обучает и оценивает свой Q-SVM на реальном анонимизированном наборе данных примерно с 500 обучающими и 125 тестовыми примерами, по восемь признаков на пользователя, моделируя как идеальное, так и шумное квантовое поведение. Они сравнивают квантовый подход с сильными классическими базовыми методами, которые используют популярные kernel-трюки на обычных компьютерах. По метрикам точности, precision, recall и площади под ROC-кривой (сводная мера компромисса между обнаружением положительных и избеганием ложных срабатываний) Q-SVM показывает сопоставимые или лучшие результаты, с особенно высоким recall: он правильно идентифицирует большую долю действительно заинтересованных пользователей, чем классические модели.
Теоретические гарантии за кулисами
Помимо чистой производительности, статья ставит более глубокий вопрос: когда вообще стоит ожидать выгоды от квантовых методов? Авторы развивают три основных теоретических результата. Во-первых, они показывают, что при выполнении определённых условий гладкости задачи обучения и при сохранении мелких квантовых схем процесс обучения квантовых ядер должен сходиться надёжно за разумное число шагов. Во-вторых, они приводят границы разделимости, указывающие на то, что их квантовое извлечение признаков может, при специфических допущениях, увеличить разрыв между двумя классами клиентов по сравнению с классическими преобразованиями — фактически упрощая задачу. В-третьих, они анализируют, как приближённые методы могут существенно снизить стоимость работы с большими пространствами признаков, получаемыми из квантовых схем, так что подход остаётся вычислительно осуществимым.
Что это может значить для маркетологов
Для команд по маркетингу и аналитике клиентов самый конкретный выигрыш заключается в том, как квантовая модель балансирует упущенные возможности и напрасные контакты. Более высокий recall у Q-SVM означает, что модель реже пропускает пользователей, которые положительно откликнутся на предложение — ключевое преимущество в кампаниях по удержанию или проактивному обслуживанию. При этом её precision и общая точность остаются в диапазоне, сопоставимом с сильными классическими базами, что подтверждается устойчивой ROC-кривой. Поскольку метод хорошо работает при разных порогах принятия решений, команды могут регулировать, насколько агрессивной или осторожной быть — отдавая приоритет либо recall, либо precision — без необходимости каждый раз переобучать модель.
Многообещающее начало, а не квантовая революция (пока)
Авторы подчёркивают, что их выводы — это ранние шаги, а не доказательство всеобщего превосходства квантовых методов. Результаты получены в симуляциях на одном наборе данных, а не на масштабных экспериментах на аппаратуре или в разных рынках. Их математические гарантии также опираются на идеализированные допущения, которые могут не полностью выполняться на шумных устройствах. Тем не менее работа показывает, что тщательно сконструированные квантовые ядра уже могут соответствовать или немного превосходить хорошие классические методы в реалистичной задаче по работе с потребителями, одновременно предлагая понятную дорожную карту к большим преимуществам по мере масштабирования квантовой аппаратуры. Вывод для читателей: квантовое машинное обучение движется от абстрактных обещаний к инструментам, которые однажды могут сделать прогнозы по клиентам более точными и гибкими в реальных бизнес‑условиях.
Цитирование: Sáez Ortuño, L., Forgas Coll, S. & Ferrara, M. Quantum kernel methods for marketing analytics with convergence theory and separation bounds. Sci Rep 16, 6645 (2026). https://doi.org/10.1038/s41598-026-35793-y
Ключевые слова: квантовое машинное обучение, маркетинговая аналитика, классификация клиентов, метод опорных векторов, квантовые ядра