Clear Sky Science · ru
Трекер типа Siamese с трансформером: двухветвевой подход с регрессией, учитывающей уверенность, и адаптивным обновлением шаблона
Обучение компьютеров следовать за одним объектом в загруженной сцене
От автомобилей с автопилотом до домашних камер наблюдения и дронов — многим современным устройствам нужно отслеживать один движущийся объект в плотной, постоянно меняющейся среде. Эта задача, называемая визуальным отслеживанием объектов, кажется простой человеку, но оказывается удивительно сложной для машин: люди проходят перед камерой, меняется освещение, объект уходит в даль или кратковременно скрывается. В статье представлена система TSDTrack — новый трекер, использующий современные достижения глубокого обучения и трансформеров, чтобы надежнее держать цель в условиях реального мира.
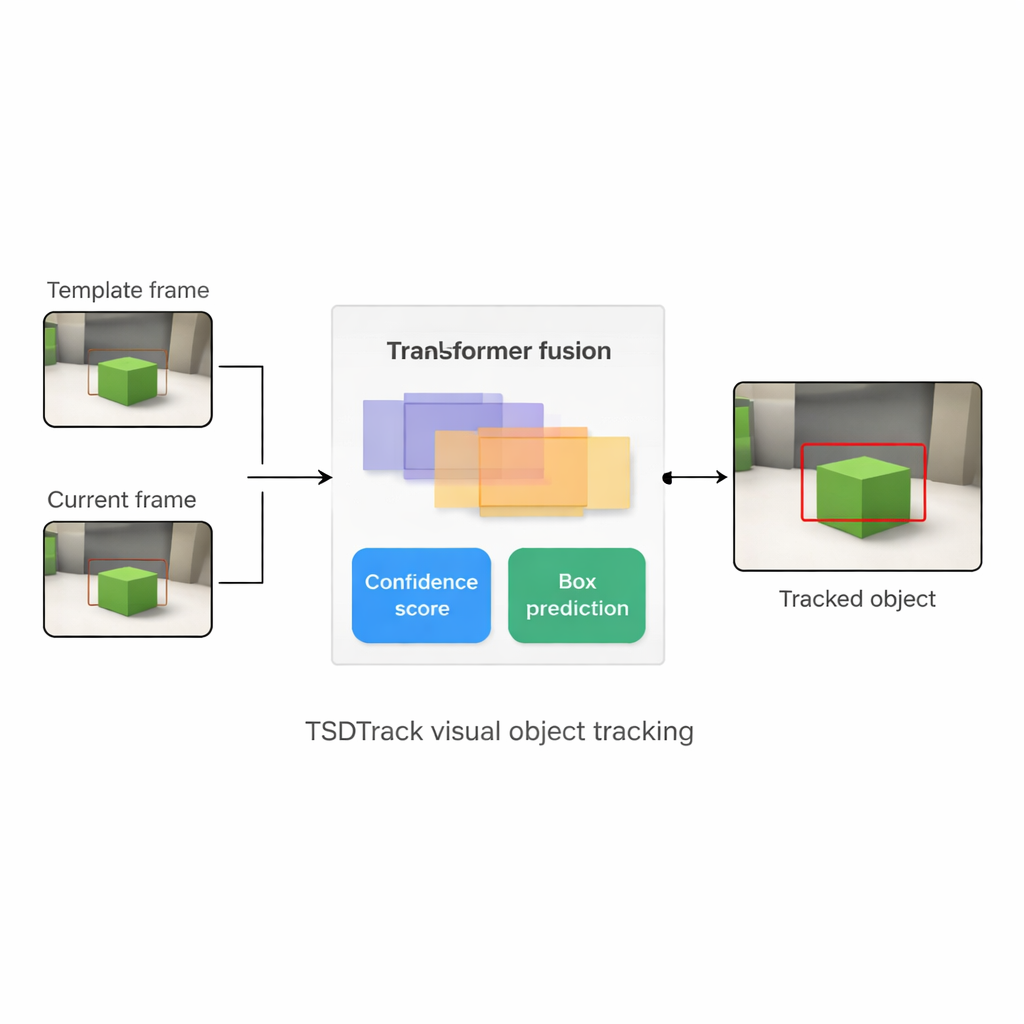
Почему следовать за одним объектом так трудно
Трекер обычно видит объект четко только в первом кадре видео и затем должен продолжать его находить по мере изменения сцены. Традиционные методы опирались либо на вручную сконструированные признаки изображения, либо на нейросеть, сравнивающую первый кадр («шаблон») с каждым новым кадром. У таких систем было три существенных слабости. Во-первых, они часто держали исходный шаблон фиксированным, поэтому при повороте объекта, частичном перекрытии или изменении масштаба трекер испытывал затруднения. Во-вторых, они обычно опирались на один уровень детализации изображения, пропуская сочетание тонких контуров и более широкого контекста, которые помогают человеку распознавать объекты. В-третьих, они не умели оценивать степень неопределенности: выдавали рамку вокруг предполагаемого объекта без ясного представления о надежности этой оценки, что приводило к дрейфу на фон.
Сочетание глобального контекста и тонких деталей
TSDTrack решает эти проблемы, сочетая классическую сиамскую архитектуру для трекинга с трансформером — тем типом моделей на основе внимания, который произвел революцию в задачах обработки языка и зрения. Система использует глубокую сеть для извлечения признаков из двух входов: небольшого фрагмента, задающего цель, и более широкого участка, содержащего область поиска. Вместо опоры на один масштаб признаков она извлекает информацию из нескольких слоев сети, которые кодируют контуры, формы и объектно-уровневые паттерны. Модуль слияния на базе трансформера обучается комбинировать эти слои так, чтобы трекер понимал и локализацию элементов на изображении, и их взаимосвязи в более широком контексте. Это помогает отличать цель от похожих объектов и захламления, даже когда изображение шумное или частично закрыто.
Понимание собственной уверенности трекера
Сердце TSDTrack — двухветвевой предсказательный блок, разделяющий задачу на два связанных вопроса: «Где объект?» и «Насколько можно доверять этому ответу?». Одна ветвь оценивает показатель уверенности, который отражает не только схожесть с шаблоном, но и то, насколько предсказанная рамка перекрывается с вероятными областями объекта. Другая ветвь рассматривает координаты рамки не как единичную догадку, а как вероятностное распределение по множеству возможных позиций, что позволяет модели выражать неопределенность. Когда изображение четкое, распределение сжимается и рамка становится точной; когда объект смазан или частично скрыт, распределение расширяется. Такой вероятностный подход дает более плавную и стабильную постановку рамки по сравнению со старыми трекерами, делающими одно жесткое предсказание.
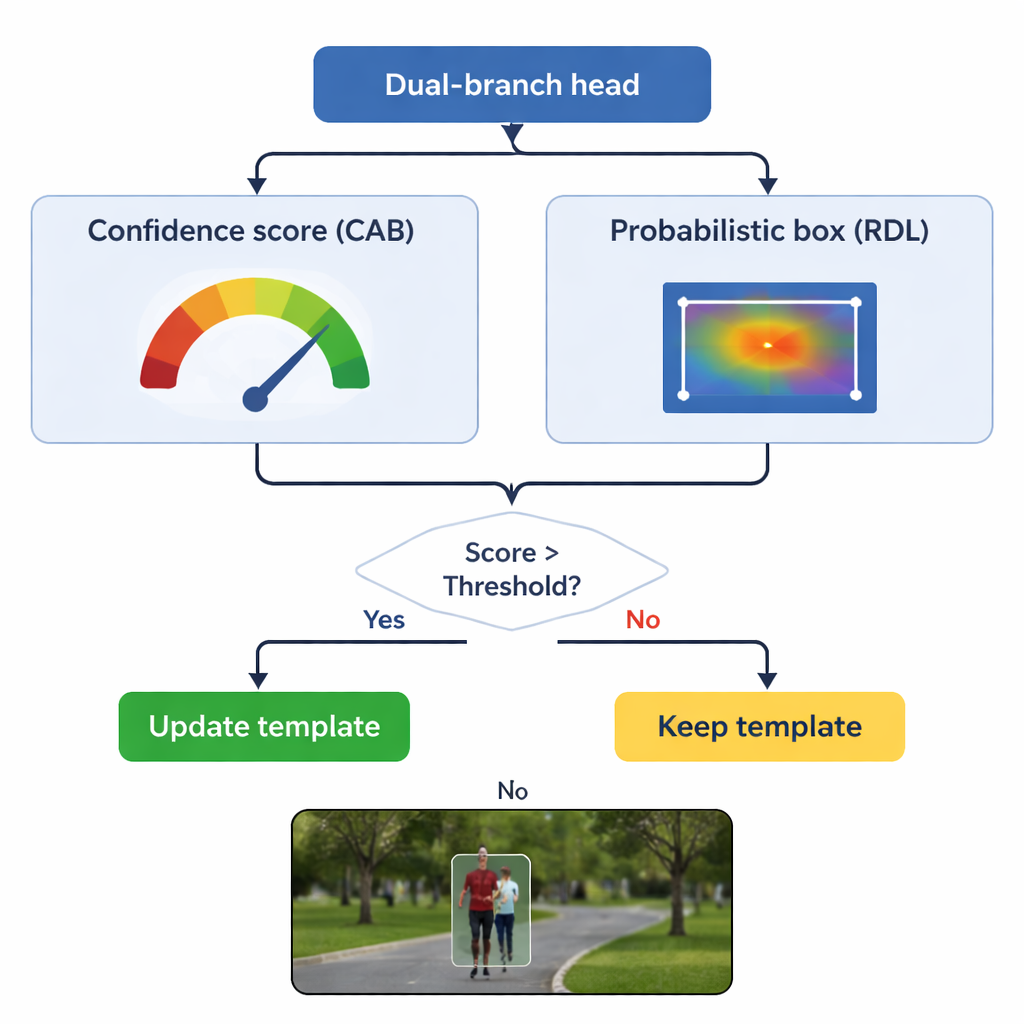
Обновление памяти без забывания исходного образа
Ключевая опасность в трекинге — «дрейф шаблона»: если модель будет обновлять представление об объекте по плохим кадрам, она может постепенно «выучить» фон. TSDTrack решает эту проблему, позволяя ветви уверенности выполнять роль шлагбаума. Система обновляет внутренний шаблон только когда оценка уверенности превышает выбранный порог, и даже в этом случае мягко смешивает новую информацию с исходным видом, а не заменяет его целиком. Такое селективное обновление позволяет трекеру адаптироваться к реальным изменениям, например при повороте человека или вращении автомобиля, не поддаваясь на кратковременные окклюзии или отвлекающие факторы. Исходный шаблон при этом хранится как стабильная опора на случай, если последующие обновления окажутся ошибочными.
Что значат результаты на практике
Авторы протестировали TSDTrack на нескольких общепринятых бенчмарках по трекингу, включая длинные видео, быстрые перемещения, аэрофотосъемку с дронов и сцены с сильным загромождением. Во всех тестах новый метод стабильно превосходил многие передовые трекеры по точности (насколько рамка близка к истинному положению объекта) и по надежности (как редко трекер полностью теряет объект), при этом работая достаточно быстро для реального времени на современном оборудовании. Для неспециалиста вывод таков: TSDTrack надежнее держит выбранную цель в сложных условиях реальных камер. За счет объединения многомасштабного рассуждения трансформера, оценки собственной уверенности и аккуратного обновления шаблона он представляет собой более надежный строительный блок для приложений вроде автономного вождения, интеллектуального видеонаблюдения и разумной робототехники.
Цитирование: Sachin Sakthi, K.S., Jeong, J.H. & Choi, W.Y. Transformer-augmented dual-branch siamese tracker with confidence-aware regression and adaptive template updating. Sci Rep 16, 5170 (2026). https://doi.org/10.1038/s41598-026-35692-2
Ключевые слова: визуальное отслеживание объектов, трекеры на основе трансформеров, сиамские сети, компьютерное зрение, автономные системы