Когда правительства, учёные или социологи пытаются узнать что-то о всей популяции — например, о среднем доходе, урожайности или уровне загрязнения — они редко могут измерить каждого. Вместо этого отбирается выборка и результаты масштабируются на всю совокупность. Это работает хорошо только если данные ведут себя «хорошо». На практике же опросы и измерения полны ошибок и экстремальных значений, которые могут сильно исказить выводы. В этой статье представлена новая методика вычисления средних по совокупности, которая остаётся надёжной даже при наличии «грязных» данных, делая решения на основе опросов более заслуживающими доверия.
Когда простые средние дают сбой
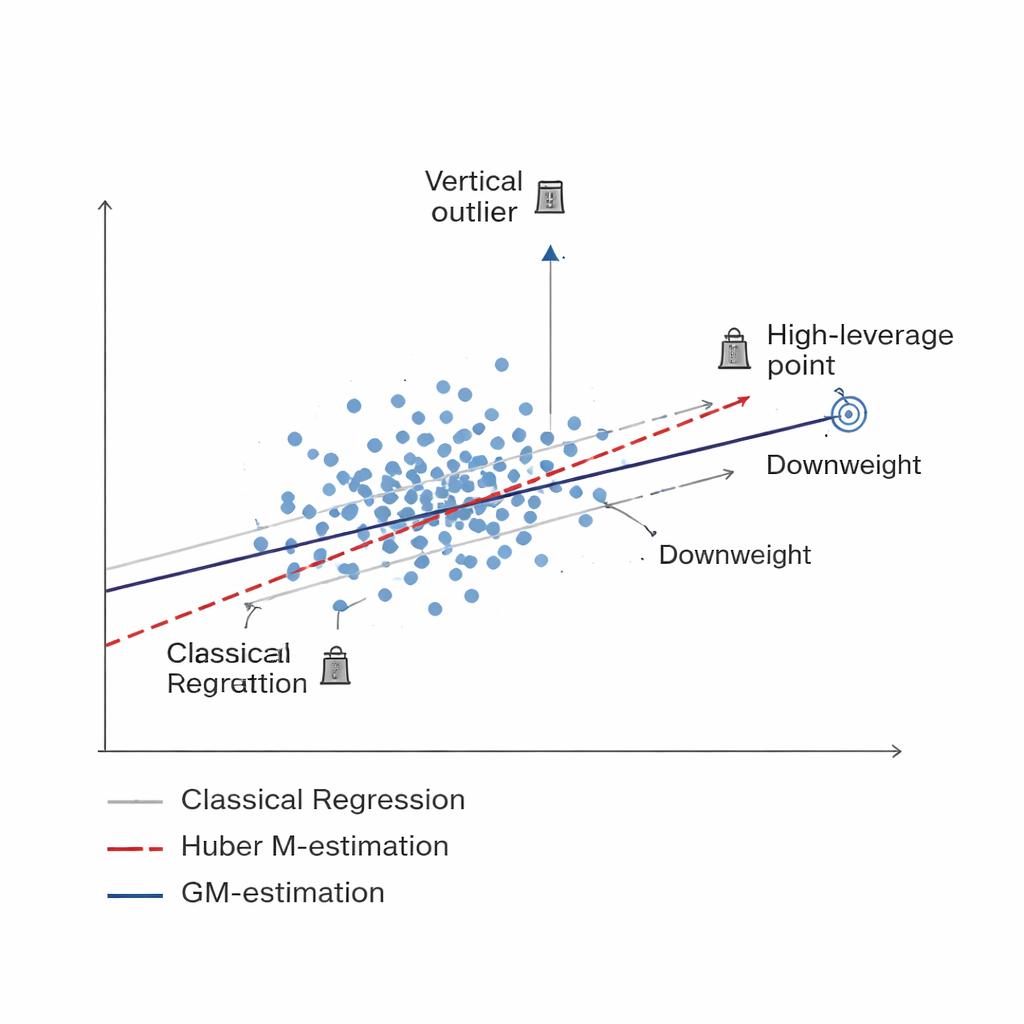
Стандартные инструменты для оценки среднего по совокупности, такие как простое выборочное среднее или обычная регрессия, предполагают, что большинство наблюдений подчиняются плавным закономерностям, без экстремальных выбросов или нетипичных случаев. В социальных и экономических опросах, мониторинге окружающей среды и сельскохозяйственной статистике это ожидание часто не оправдывается. Несколько ошибочных измерений, редкие но экстремальные события или неверно указанные ответы могут отвести оценки в сторону от истины, увеличивая и смещение, и неопределённость. Ранее предложенные подходы пытались смягчить влияние таких выбросов с помощью так называемых робастных методов, включая популярную Huber M-оценку. Хотя эти методы полезны, они в основном защищают от экстремальных значений по отклику и остаются уязвимыми к необычным шаблонам во вспомогательной информации.
Более умный способ понижать вес сомнительных данных Figure 1.
Исследование развивает новое семейство оценивателей, построенных на обобщённой M-оценке (GM-оценке). Вместо равного обращения с каждым отобранным элементом методы GM назначают адаптивные веса, которые зависят одновременно от двух факторов: насколько экстремален отклик единицы (вертикальный выброс) и насколько необычна связанная с ней информация (точка с высоким левереджем). Три конкретные версии — названные Mallows-GM, Schweppes-GM и SIS-GM — разработаны для распространённых схем выборки, включая простую случайную выборку без замены и более сложные стратифицированные планы, где популяция разделена на относительно однородные группы. Совместно контролируя оба типа проблемных наблюдений, эти оцениватели стремятся сохранить итоговую оценку среднего стабильной даже при серьёзном загрязнении данных.
Проверка новых оценивателей
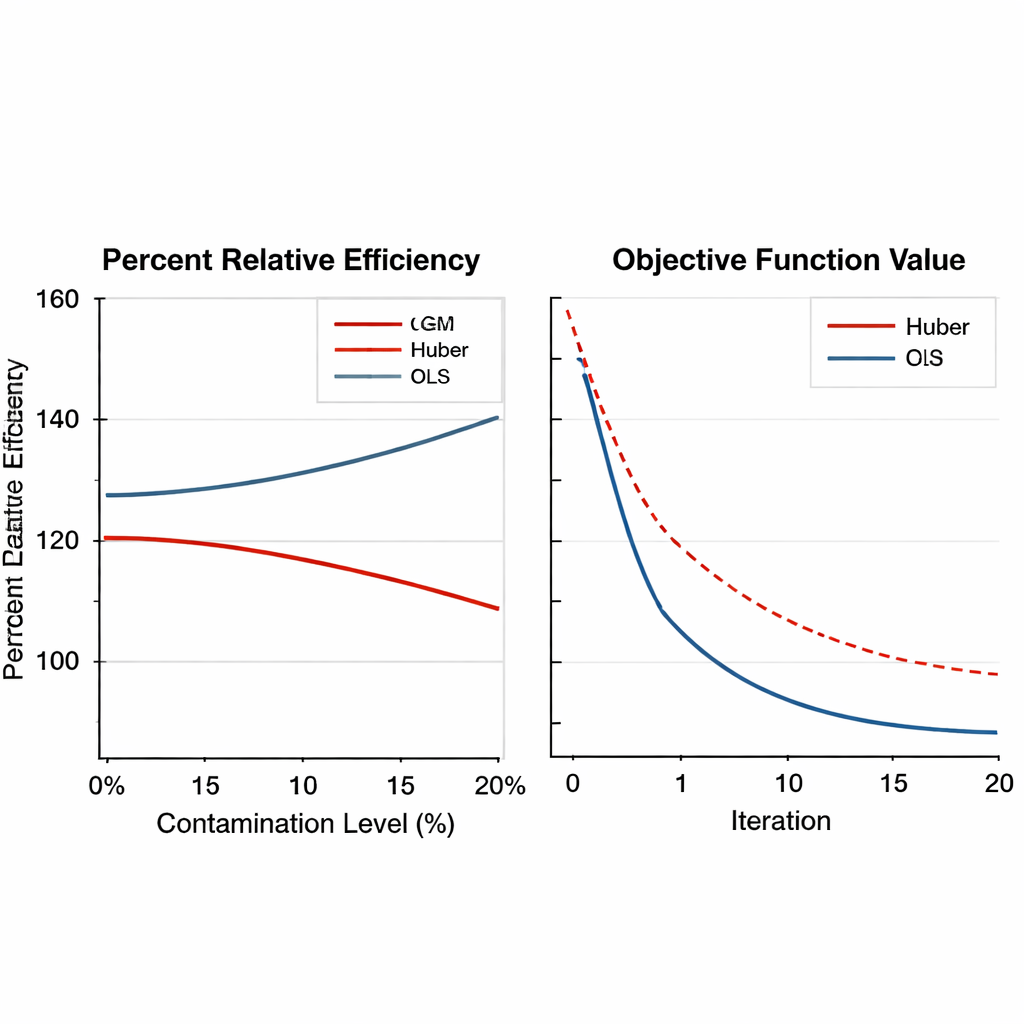
Чтобы оценить эффективность GM-оценивателей, автор проводит обширные численные эксперименты. Сначала реальные данные по табаководству анализируются в двух вариантах: в «чистой» версии и в преднамеренно искажённой версии, где одна единица заменена экстремальными значениями. Новые оцениватели сравнивают с традиционной регрессией и робастными методами на основе Huber с использованием показателя, называемого процентной относительной эффективностью, который отражает, насколько меньше ошибка оценки. При широком диапазоне размеров выборок GM-оцениватели последовательно превосходят старые методы, особенно когда данные содержат экстремумы. В некоторых сценариях лучший из GM-оценивателей снижает ошибку более чем на 50 процентов по сравнению с подходом Хабера.
Робастность в разных схемах, условиях и при выборе настроек Figure 2.
Далее работа расширяет проверки с помощью крупномасштабных компьютерных симуляций. Искусственные популяции генерируются при нескольких формах распределения — нормальном, скошенном и с тяжёлыми хвостами — и загрязняются различными долями выбросов, от нуля до 20 процентов. Рассматриваются как простые, так и стратифицированные планы выборки, а сила связи между основной переменной и её помощниками варьируется от слабой до сильной. GM-оцениватели не только сохраняют преимущество при сильном загрязнении, часто достигая выигрыша в эффективности свыше 150 процентов, но и демонстрируют плавную и надёжную численную сходимость. Важно, что их характеристики мало меняются при разумных изменениях внутренних настроек, что означает: практикам не нужно тонко подбирать параметры для каждого нового опроса.
Что это означает для практических опросов
Проще говоря, статья показывает, что предложенные GM-оцениватели предоставляют более безопасный способ преобразования несовершенных выборок в оценки средних по совокупности. При идеальных, «чистых» данных они примерно так же точны, как классические методы. Но когда данные содержат ошибки измерений, неверно указанные значения или редкие экстремальные события — как часто бывает в национальных опросах, экологическом мониторинге и финансовой статистике — они дают существенно более надёжные ответы. Поскольку методы вычислительно выполнимы и хорошо работают в разных схемах и условиях, эти оцениватели предлагают практическое улучшение, которое делает решения, основанные на данных, более устойчивыми к неизбежной «грязи» реальных данных.
Цитирование: Abuhasel, K.A. A robust methodology for finite population mean estimation based on Generalized M estimation.
Sci Rep16, 5182 (2026). https://doi.org/10.1038/s41598-026-35592-5