Clear Sky Science · ru
Слепое распознавание каналов кодов на основе сверточных нейронных сетей с двухветвевым слиянием признаков
Более умные радиостанции для переполненных диапазонов
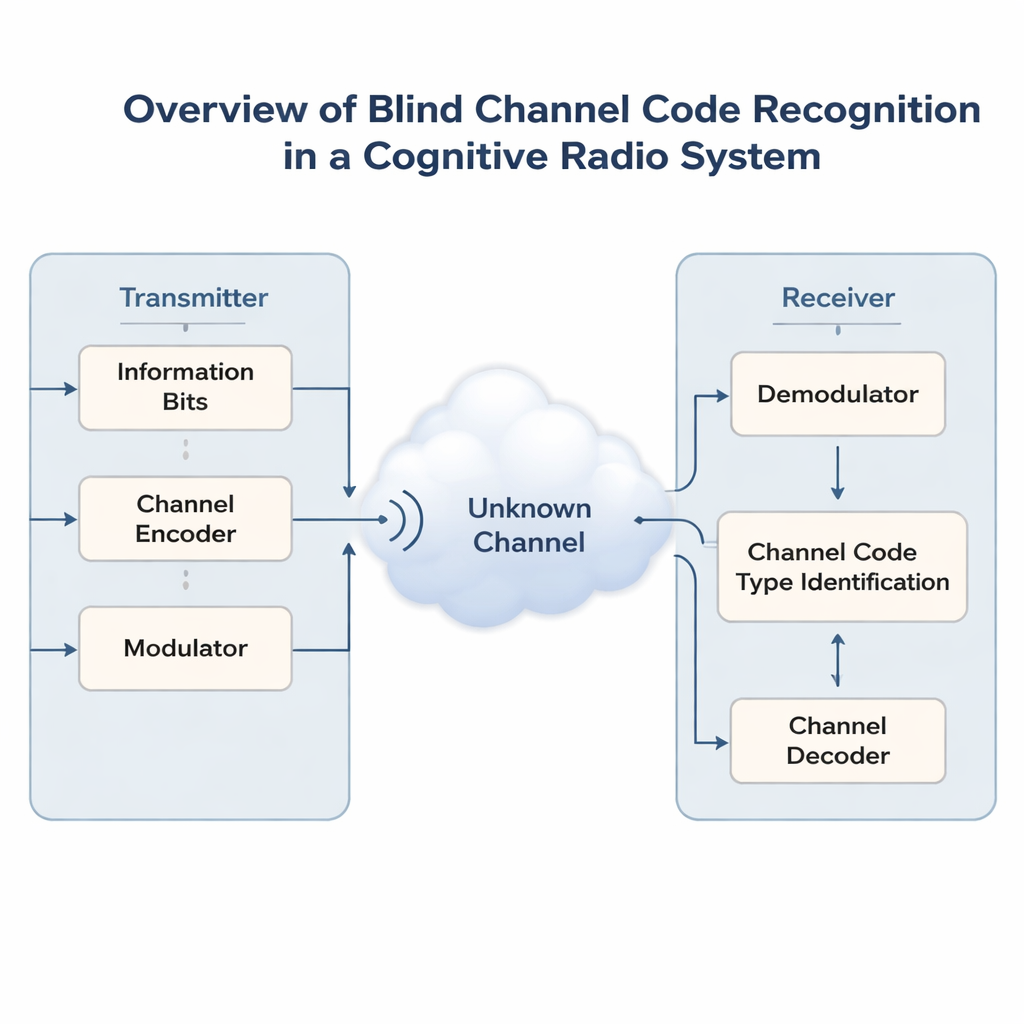
Беспроводные сети становятся всё более загруженными: телефоны, датчики и автомобили конкурируют за одни и те же радиочастоты. Чтобы избежать хаоса, будущие «когнитивные радио» должны сначала слушать, а затем интеллектуально делить спектр, уже принадлежащий другим. Ключевая проблема в том, что такие приёмники часто не знают, как исходный сигнал был защищён от ошибок перед передачей. В этой статье представлен новый метод искусственного интеллекта, который способен без предварительной информации угадывать скрытый код коррекции ошибок в сигнале — что упрощает задачу умным приёмникам по захвату и надёжной передаче данных.
Почему скрытые коды коррекции ошибок важны
Современные беспроводные каналы защищают данные с помощью кодов коррекции ошибок, которые добавляют структурированную избыточность, позволяющую приёмникам исправлять ошибки, вызванные шумом и помехами. Разные ситуации требуют разных кодов: простые коды Хэмминга, более мощные BCH и Рида–Соломона, гибкие LDPC и Polar, либо потоковые сверточные и Turbo-коды. В некоперативных условиях — например, в военной связи, мониторинге спектра или в открытых общих полосах — приёмник не может спросить передатчик, какой код используется. Он видит только зашумлённый поток битов. Правильное определение схемы кодирования, задача, называемая слепым распознаванием кодов, необходимо выполнить прежде чем возможна осмысленная декодировка или более высокоуровневая обработка.
Ограничения ранних методов распознавания
Ранние исследования либо сосредотачивались на одном семействе кодов за раз, либо опирались на вручную подобранную статистику — например, частоты повторов битов, степень «случайности» последовательности или алгебраические трюки, специфичные для конкретного кода. Такие подходы могут сказать «это какой-то блочный код», но им трудно различить несколько популярных форматов одновременно. В последние годы глубокое обучение улучшило ситуацию, рассматривая потоки бит как предложения в языковой модели. Однако большинство нейросетей либо смотрят только на сырые последовательности, либо только на вручную созданные признаки, и обычно справляются не более чем с двумя–тремя типами кодов одновременно. Их точность резко падает при увеличении вероятности ошибок битов — как раз тогда, когда надёжное распознавание наиболее необходимо.
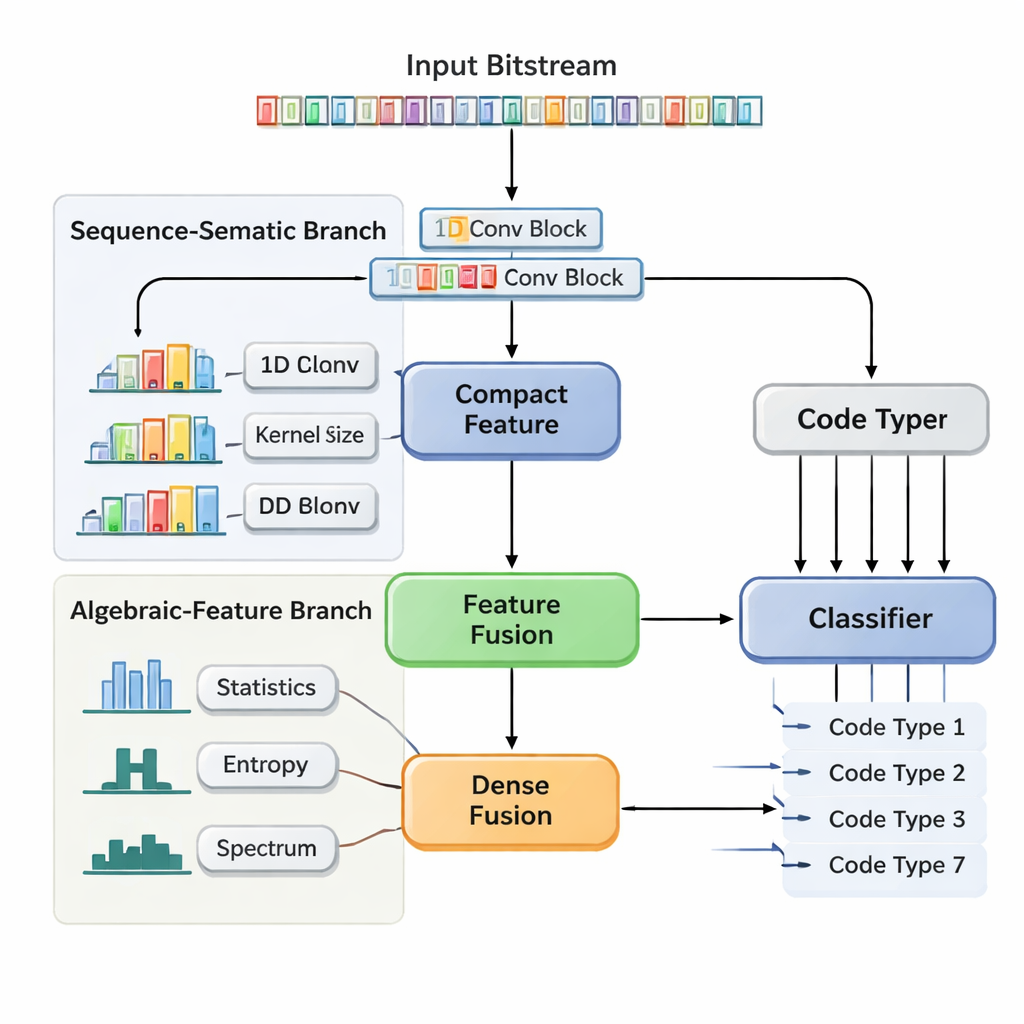
Нейросеть с двумя треками, изучающая структуру и статистику
Авторы предлагают двухветвевую сверточную нейронную сеть с слиянием признаков (DBFCNN), которая решает задачу слепого распознавания семи широко используемых кодов за один проход: Хэмминга, BCH, Рида–Соломона, LDPC, Polar, сверточных и Turbo-кодов. Первая ветвь рассматривает входные биты как короткие «слова», группируя их по 8 бит и отображая каждый восьмибитный блок в плотный вектор, подобно встраиваниям слов в обработке естественного языка. Затем применяются одномерные свёртки с разными размерами окон и скоростями дилатации. Небольшие фильтры улавливают краткодействующие закономерности, например плотную структуру простых блочных кодов, в то время как большие и дилатированные фильтры охватывают более длинные участки, выявляя следы интерливера и паритетных шаблонов, характерных для Turbo и LDPC. Шаг глобального пулинга сжимает это в компактное резюме структурного «отпечатка» последовательности.
Ручные измерения, стабилизирующие модель
Вторая ветвь даёт совсем другую перспективу. Вместо сырых бит она вычисляет семь семейств описательных статистик, которые инженеры знают как чувствительные к выбору кодов. Сюда входят частоты появлений серий одинаковых битов, сложность последовательности, насколько случайной она выглядит, насколько сильно она коррелирует со сдвинутыми копиями самой себя и как энергия распределена по частотам. Дополнительные меры исследуют, насколько «линейным» кажется код и как ведут себя локальные блоки битов. Поскольку эти статистики медленно меняются с ростом шума, они дают сети стабильную, устойчивую к шуму перспективу. Небольшая нейросетевая подсистема преобразует вектор таких признаков в ещё одно компактное представление. Наконец, DBFCNN конкатенирует обе ветви, нормализует и регуляризует объединённые признаки и передаёт их классификатору, который выдаёт вероятности для каждого из семи типов кодов.
Доказательство надёжности в зашумлённых условиях
Чтобы строго проверить DBFCNN, авторы сгенерировали более миллиона синтетических примеров, охватывающих семь семейств кодов, различные настройки параметров и вероятности ошибок битов от почти безошибочных до крайне зашумлённых условий. Они обучали и тестировали модель с помощью тщательных процедур Монте-Карло, чтобы избежать скрытых пересечений между обучающими и тестовыми данными. На этом широком диапазоне DBFCNN постоянно превосходила три сильных базовых метода, включая предыдущую мультимасштабную дилатированную CNN, специально разработанную для этой задачи. При умеренных и низких уровнях ошибок (вероятность ошибки бита ниже 10⁻³) новая сеть правильно определяла тип кода примерно в 98% случаев, улучшая абсолютную точность примерно на 5–11 процентных пунктов по сравнению с сильнейшей предыдущей моделью. Даже при высоком уровне шума DBFCNN сохраняла явное преимущество и всё ещё могла с высокой уверенностью распознавать несколько сложных кодов.
Что это значит для будущих когнитивных радио
Для неспециалиста основной вывод таков: эта работа демонстрирует, как сочетание экспертных знаний и глубокого обучения может сделать радиостанции гораздо более автономными. DBFCNN улавливает тонкие «акценты» разных кодов коррекции ошибок в зашумлённых потоках битов, слушая двумя способами одновременно: одна ветвь фиксирует детальные локальные шаблоны, а другая измеряет глобальные статистические подсказки. Сливая эти представления, система чаще всего может точно определить, какая схема кодирования используется, без какого-либо сотрудничества со стороны отправителя. Эта способность является строительным блоком для когнитивных радио, которые могут присоединяться к незнакомым сетям, адаптироваться к меняющейся среде и эффективнее использовать ограниченный спектр, сохраняя надёжность связи даже при переполненных и зашумлённых эфирах.
Цитирование: Ma, Y., Lei, Y., Liu, C. et al. Blind recognition of channel codes based on dual-branch feature fusion convolutional neural networks. Sci Rep 16, 5159 (2026). https://doi.org/10.1038/s41598-026-35558-7
Ключевые слова: когнитивное радио, кодирование каналов, глубокое обучение, коррекция ошибок, классификация сигналов