Clear Sky Science · ru
Геолокация пользователей в социальных сетях на основе K-medoid и графовой сети внимания с гауссовским ядром
Почему ваши твиты могут выдать, где вы живёте
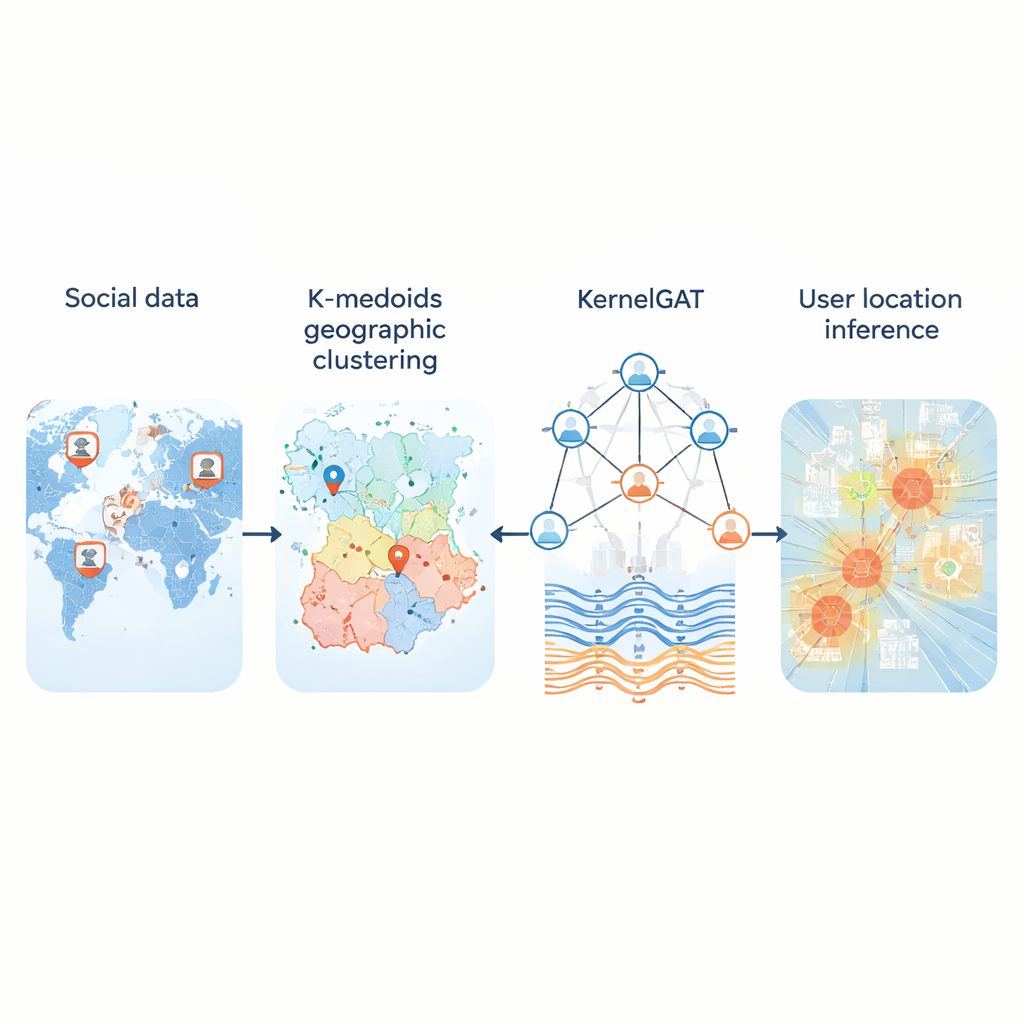
Каждый день миллионы людей публикуют в социальных сетях, не указывая GPS-координаты. Тем не менее эти публикации всё равно оставляют подсказки о том, где пользователи живут, работают и путешествуют. Умение выводить местоположение по такому публичному следу важно для всего — от реагирования при чрезвычайных ситуациях и отслеживания заболеваний до локальных рекомендаций и таргетированных сервисов. В этой статье предложен новый метод под названием KMKGAT, который использует и содержимое сообщений, и структуру их онлайн‑связей, чтобы точнее оценивать местоположение пользователей, чем предыдущие подходы.
От онлайн‑болтовни к реальным местам
Когда пользователи пишут твиты или микроблоги, они могут упоминать названия мест, пользоваться местным сленгом или взаимодействовать с ближайшими друзьями. Компании вроде Twitter (теперь X) знают IP‑адрес пользователя, но внешним исследователям и провайдерам услуг такие данные обычно недоступны. Им приходится работать с публичной информацией: самим текстом, профилями пользователей и тем, кто с кем общается. Ранние методы делились на три группы. Методы только по содержимому извлекали слова и хэштеги для угадывания мест. Методы только по сети опирались на факт, что люди склонны взаимодействовать с близкими географически пользователями. Третья, более мощная группа объединяла оба вида сигналов, но всё ещё имела слабые места — особенно для людей в малонаселённых регионах и у пользователей, чьи онлайн‑связи охватывают большие расстояния.
Более умное географическое группирование с реальными центрами пользователей
Ключевая проблема — как превратить непрерывную поверхность Земли в набор регионов, которые компьютер сможет предсказывать. Многие системы разрезают карту на фиксированную сетку. Это работает достаточно хорошо в городах, но терпит неудачу в сельской местности, где огромные ячейки покрывают сотни километров. Новый метод заменяет жёсткие сетки кластеризацией k‑medoids — способом группировки пользователей так, чтобы каждый регион был центрирован на реальном пользователе, а не на искусственной точке. Это делает регионы компактнее и менее чувствительными к выбросам, особенно там, где пользователей мало. В тестах на трёх больших наборах данных Twitter, охватывающих США и мир, такая адаптивная разбивка уменьшала типичные ошибки по сравнению со схемами на основе сетки и давала более правдоподобные «домашние регионы» для пользователей.
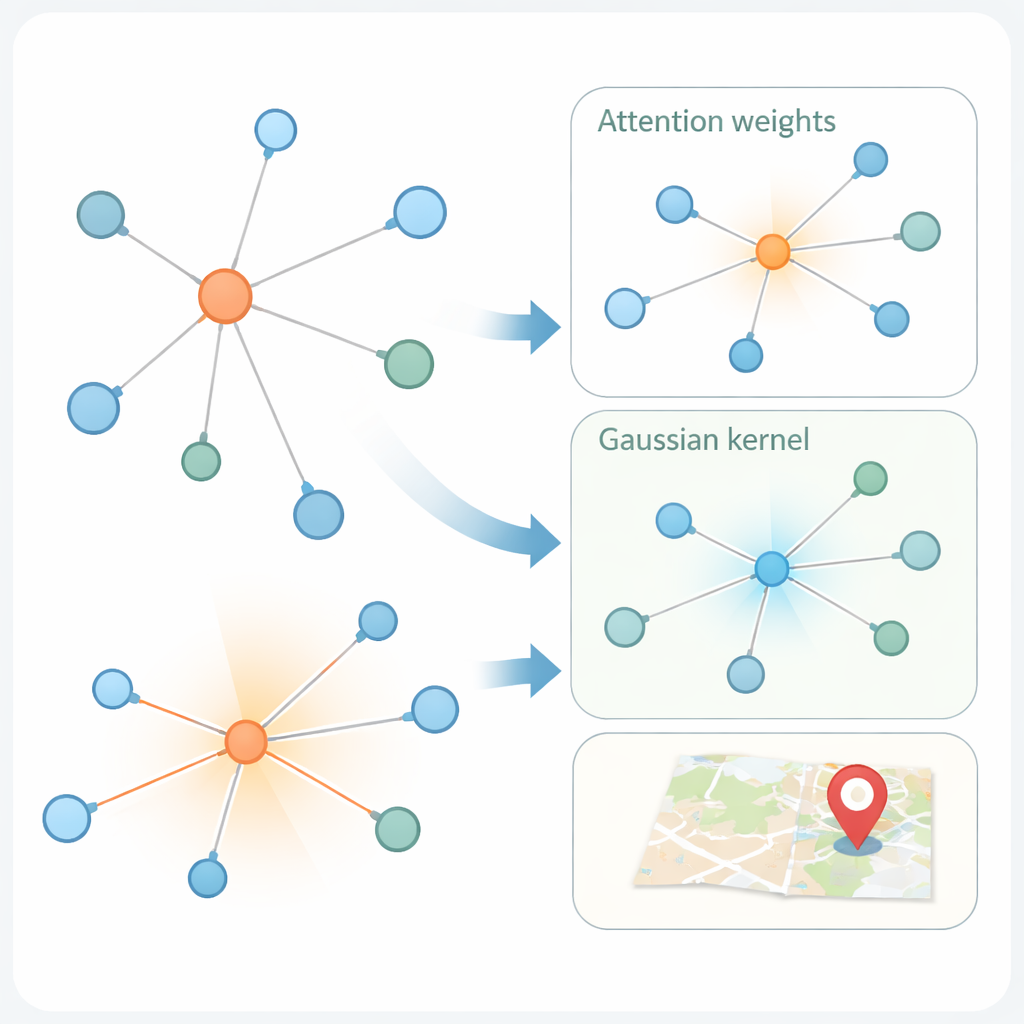
Дать сети возможность фокусироваться на близких и похожих пользователях
Вторая инновация — в том, как модель учится на социальной графовой структуре. Современные «графовые сети внимания» уже взвешивают соседей пользователя по‑разному, исходя из схожести их признаковых представлений. Но одна только схожесть может вводить в заблуждение: аккаунт в Нью‑Йорке и аккаунт в Лондоне могут использовать похожий язык, но быть далеко друг от друга географически. KMKGAT дополняет внимание гауссовским ядром — математическим фильтром, который отдаёт приоритет соседям с близкими к целевому пользователю изученными признаками и ослабляет влияние удалённых. Несколько таких ядер, комбинируемых как смесь линз, позволяют модели улавливать локальность в разных масштабах. Это отражает простое, но мощное правило: онлайн‑взаимодействия часто сильнее между людьми, которые находятся физически ближе.
Лёгкие текстовые признаки, которые всё равно несут подсказки о местоположении
Вместо опоры на тяжёлые глубинные языковые модели, которые могут плохо справляться с шумным, наполненным сленгом стилем твитов, авторы используют классическую технику TF–IDF, чтобы превратить коллекцию публикаций каждого пользователя в мешок взвешенных ключевых слов. Распространённые слова вроде «the» или «lol» получают малый вес, тогда как более редкие, специфичные для региона термины выходят в топ. Эти текстовые признаки присоединяются к каждому пользователю в социальной сети и проходят через улучшенную сеть внимания. Примечательно, что лучшие результаты получались, когда большинство текстовых признаков случайно отбрасывалось во время обучения, что указывает на то, что лишь небольшая доля слов действительно помогает в определении местоположения, а остальное вносит шум.
Превосходство над современными методами в масштабе
Для оценки производительности исследователи измеряли, на каком расстоянии в километрах центр предсказанного региона находится от известных координат пользователя, и какой процент пользователей был помещён в пределах 161 км (100 миль) от их истинного местоположения. На трёх эталонных наборах данных Twitter KMKGAT последовательно соответствовал или превосходил сильные существующие системы, повышая точность в пределах 161 км на несколько процентных пунктов — значимый прирост на этом уровне зрелости. Преимущества были наиболее заметны в небольших и средних сетях, тогда как в массивном глобальном графе метод был ограничен необходимостью во время обучения выборочно учитывать только ближайших соседей.
Что это значит в повседневном понимании
Для неспециалистов вывод таков: становится всё более реально оценивать, где находятся пользователи социальных сетей, даже если они никогда не ставят метку местоположения. Группируя пользователей в реалистичные регионы на основе реальных аккаунтов и обучая модель в первую очередь полагаться на близких, похожих соседей в социальной сети, KMKGAT сокращает пространство, где человек, вероятно, живёт или публикует. Это может помочь спасателям находить людей во время бедствий, улучшать локальный поиск и рекомендации и поддерживать исследования распространения информации между местами. В то же время это подчёркивает, сколько наши обычные онлайн‑взаимодействия могут рассказать о нашей офлайн‑жизни, что требует вдумчивого обращения с данными и защиты приватности.
Цитирование: Jiao, A., Qiao, Y., Li, P. et al. Social user geolocation based on K-medoids and Gaussian Kernel graph attention network. Sci Rep 16, 5115 (2026). https://doi.org/10.1038/s41598-026-35532-3
Ключевые слова: геолокация в социальных медиа, местоположение пользователей Twitter, графовые нейронные сети, сервисы, зависящие от местоположения, онлайн-конфиденциальность