Clear Sky Science · ru
Автоматизированная идентификация контекстно релевантных биомедицинских сущностей с использованием обоснованных LLM
Почему умная разметка медицинских статей важна
Каждый год появляется тысячи биомедицинских исследований, каждое из которых полно сведений о генах, типах клеток, заболеваниях и методах лечения. Тем не менее большая часть этой информации остаётся запертой в длинных PDF-файлах, что затрудняет другим учёным поиск нужных данных. В этой статье рассматривается, как современные методы искусственного интеллекта — большие языковые модели (LLM) — могут автоматически извлекать ключевые биомедицинские термины из научных статей, помогая превращать разрозненные публикации в хорошо организованные, поисковые ресурсы.
От неструктурированных статей к поисковым строительным блокам
Биомедицинские исследовательские центры, такие как немецкие Collaborative Research Centers, зависят от прозрачных и структурированных данных, чтобы делать исследования пригодными для повторного использования в течение многих лет. Традиционно исследователи вручную помечали свои наборы данных важными сущностями, такими как организмы, клеточные линии и гены — утомительная и трудоёмкая задача. LLM способны читать полные тексты статей и понимать контекст, что делает их многообещающими инструментами для автоматизации разметки. Но есть сложность: решение о том, какие термины действительно релевантны, зависит от научного вопроса и того, как данные будут повторно использоваться. Авторы работают в рамках тщательно продуманной схемы метаданных нефрологически-ориентированного CRC «NephGen», которая подсказывает ИИ, какие типы сущностей искать и как их следует организовать.
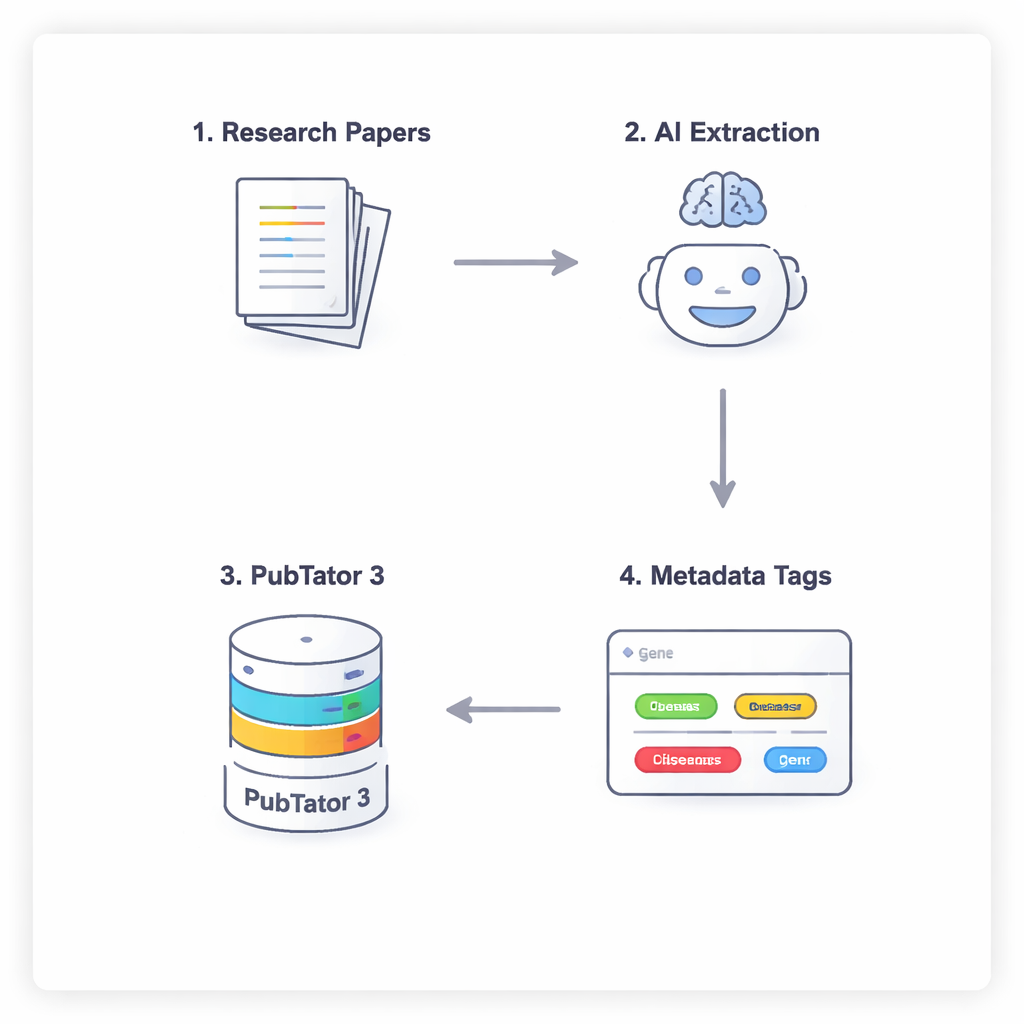
Четырёхэтапный диалог между ИИ и биологической базой данных
Чтобы предотвратить склонность ИИ к домыслам или «галлюцинациям» биомедицинских фактов, исследователи используют четырёхэтапный процесс, который заставляет модели осторожно рассуждать и перепроверять результаты. Сначала модель сканирует полный текст статьи (игнорируя обсуждение и ссылки), чтобы предложить потенциально релевантные сущности. Во-вторых, она должна обратиться к внешнему инструменту — PubTator 3, большой биомедицинской базе данных — чтобы подтвердить, что каждое предложенное название действительно существует и имеет признанный идентификатор. В-третьих, ИИ назначает каждую подтверждённую сущность в слот схемы метаданных NephGen, которая группирует сущности в иерархическую, человеком разработанную структуру. Наконец, модель консолидирует всё это в структурированный JSON-вывод — по сути аккуратное машинно-читаемое резюме ключевых биомедицинских сущностей в статье.
Тестирование восьми моделей ИИ на реальных исследованиях по почкам
Команда реализовала этот рабочий процесс с помощью API для 14 различных LLM и обнаружила, что только восемь из них надёжно соблюдали строгие требования, такие как возврат валидного JSON и корректное использование внешних инструментов. Эти восемь моделей затем применили к шести статьям по нефрологии и попросили каждого автора статьи кратко в личном интервью проверить итоговый список сущностей, сгенерированный ИИ. Поскольку не существует фиксированного «правильного» числа сущностей для извлечения, авторы сосредоточились на точности: какую долю предложенных сущностей учёные признали корректными. Используя статистические методы метаанализа, адаптированные для долей, близких к 100%, они оценили точность для каждой модели с учётом вариабельности между статьями.
Высокая точность, но компромиссы в усилиях, стоимости и скорости
Во всех моделях ИИ достигли общей точности примерно 91%, то есть подавляющее большинство предложенных сущностей были признаны корректными. GPT-4.1, GPT-4o Mini и Gemini 2.0 Flash показали наивысшую точность — примерно 94–98% — хотя их различия статистически неочевидны. Модели Gemini, как правило, предлагали больше сущностей в целом, что приводило к большему числу корректных тегов, но и к большему объёму проверки со стороны людей. Некоторые более мелкие или дешёвые модели, такие как GPT-4.1 Nano, работали быстрее и стоили дешевле, но были заметно менее точны. Авторы визуализировали эти компромиссы с помощью Парето-границ, выявив сочетания моделей, балансирующие точность, число корректных сущностей, стоимость и время обработки: например, GPT-4o Mini оказался особенно привлекательным, когда важны и высокая точность, и низкая стоимость.
Почему люди всё ещё должны оставаться в цикле
Несмотря на высокие показатели, исследование подчёркивает важные ограничения. Модели иногда путали информацию, относящуюся к опубликованной статье, с деталями, которые не были действительно релевантны исходному набору данных, пригодному для повторного использования. Эта путаница отражает более широкую проблему автоматизированного текстового майнинга: научные статьи обсуждают гораздо больше, чем попадает в общий набор данных. Авторы поэтому рекомендуют, чтобы эксперты-люди продолжали проверять аннотации, сгенерированные ИИ, до их публикации. Они также отмечают, что их оценка охватывает лишь шесть статей по нефрологии, поэтому нужны более широкие тесты в других областях. Со временем рутинная схема «человек в цикле» могла бы создать эталонный набор согласованных аннотаций, что позволило бы измерять не только точность, но и долю сущностей, упущенных ИИ.
Что это значит для будущего обмена биомедицинскими данными
Исследование демонстрирует, что при тщательном руководстве и привязке к надёжным базам данных современные LLM могут надёжно помогать аннотировать биомедицинские статьи, значительно сокращая ручную работу исследователей. Лучшие модели приближаются к уровню точности экспертов, предлагая различные компромиссы между полнотой, стоимостью и скоростью. Пока что проверка людьми остаётся необходимой, чтобы гарантировать, что аннотации действительно соответствуют наборам данных и контексту исследования. Но по мере того как инструменты и модели с открытым кодом продолжают развиваться, такие рабочие процессы могут стать стандартной основой для превращения сегодняшнего потока медицинских публикаций в хорошо организованный и повторно используемый общедоступный ресурс.
Цитирование: Watter, M., Giuliani, C., Benadi, G. et al. Automated identification of contextually relevant biomedical entities with grounded LLMs. Sci Rep 16, 1952 (2026). https://doi.org/10.1038/s41598-026-35492-8
Ключевые слова: биомедицинский текстовый майнинг, большие языковые модели, аннотация метаданных, обоснованный ИИ, исследования нефрологии